

La première fois que j'ai croisé @OpenLedger , je l'ai presque immédiatement écarté. Un autre protocole d'IA, un autre token, une autre promesse de décentralisation qui va tout résoudre. Le marché est inondé de ces récits depuis des mois maintenant. Chaque projet prétend construire le futur de la propriété de l'IA, mais la plupart d'entre eux dépendent encore des mêmes structures centralisées en dessous. Ce qui m'a fait revenir à OpenLedger plus tard, ce n'était pas le buzz ou l'action des prix. C'était un sentiment étrange que le protocole pensait à l'IA différemment du reste du marché. Moins obsédé par le modèle lui-même, plus obsédé par ce qui se passe autour du modèle après qu'il existe.
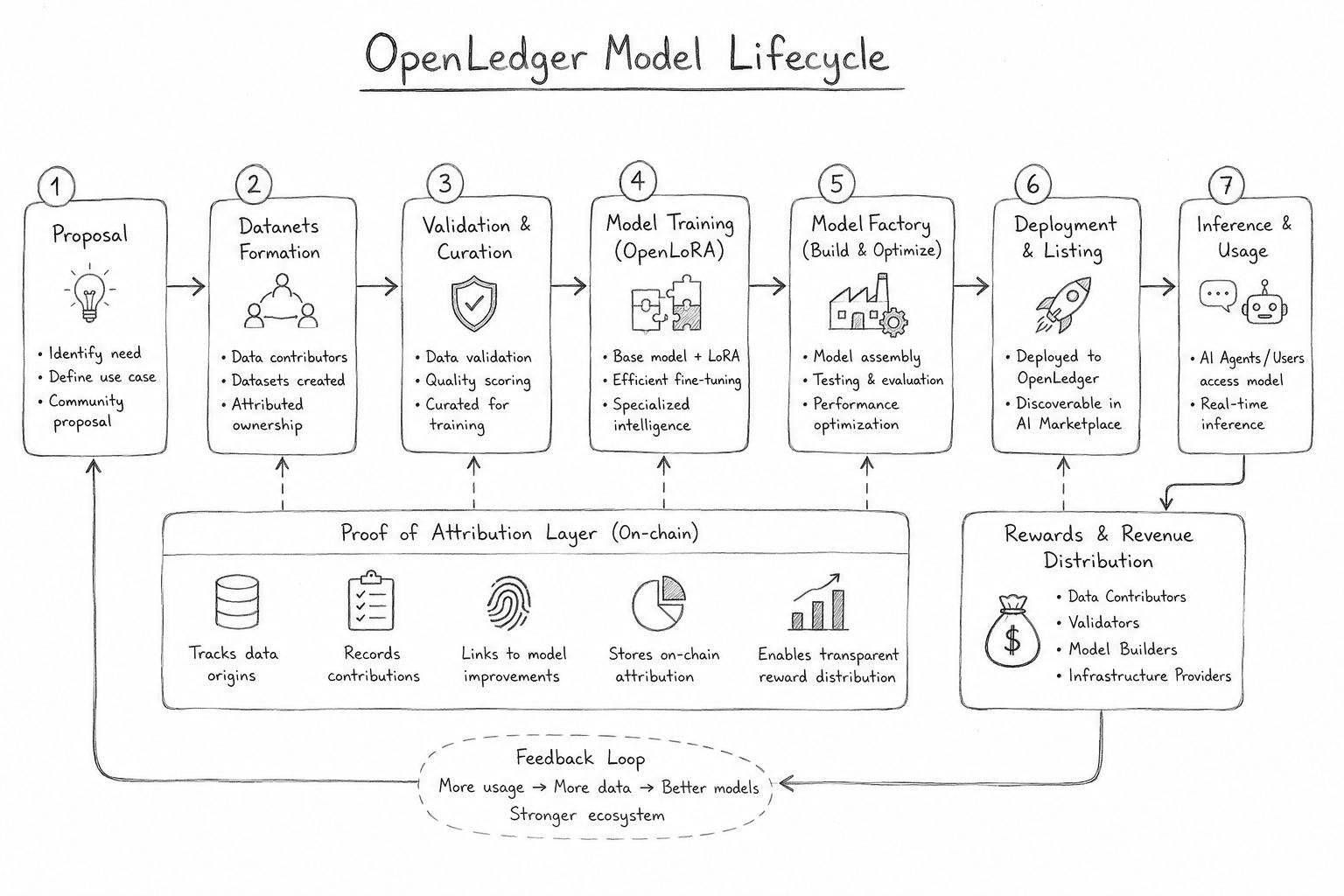
Cela est devenu évident une fois que j'ai commencé à suivre comment un modèle se déplace réellement à travers l'écosystème OpenLedger. Cela ne commence pas par un lancement flashy ou une démo polie. Cela commence par une proposition liée à un écart de demande spécifique dans le réseau. Cela semble petit, mais honnêtement, cela change toute la logique de développement. La plupart des entreprises IA construisent d'abord et recherchent l'utilité plus tard. #OpenLedger semble aborder le processus presque comme une planification d'infrastructure économique. Avant même que l'entraînement ne commence, le protocole considère déjà d'où viennent les données, qui contribue à la valeur, comment l'attribution fonctionne, et ce qui se passe une fois que la demande d'inférence apparaît plus tard. Je ne m'attendais pas à ce niveau de réflexion économique d'un protocole IA.
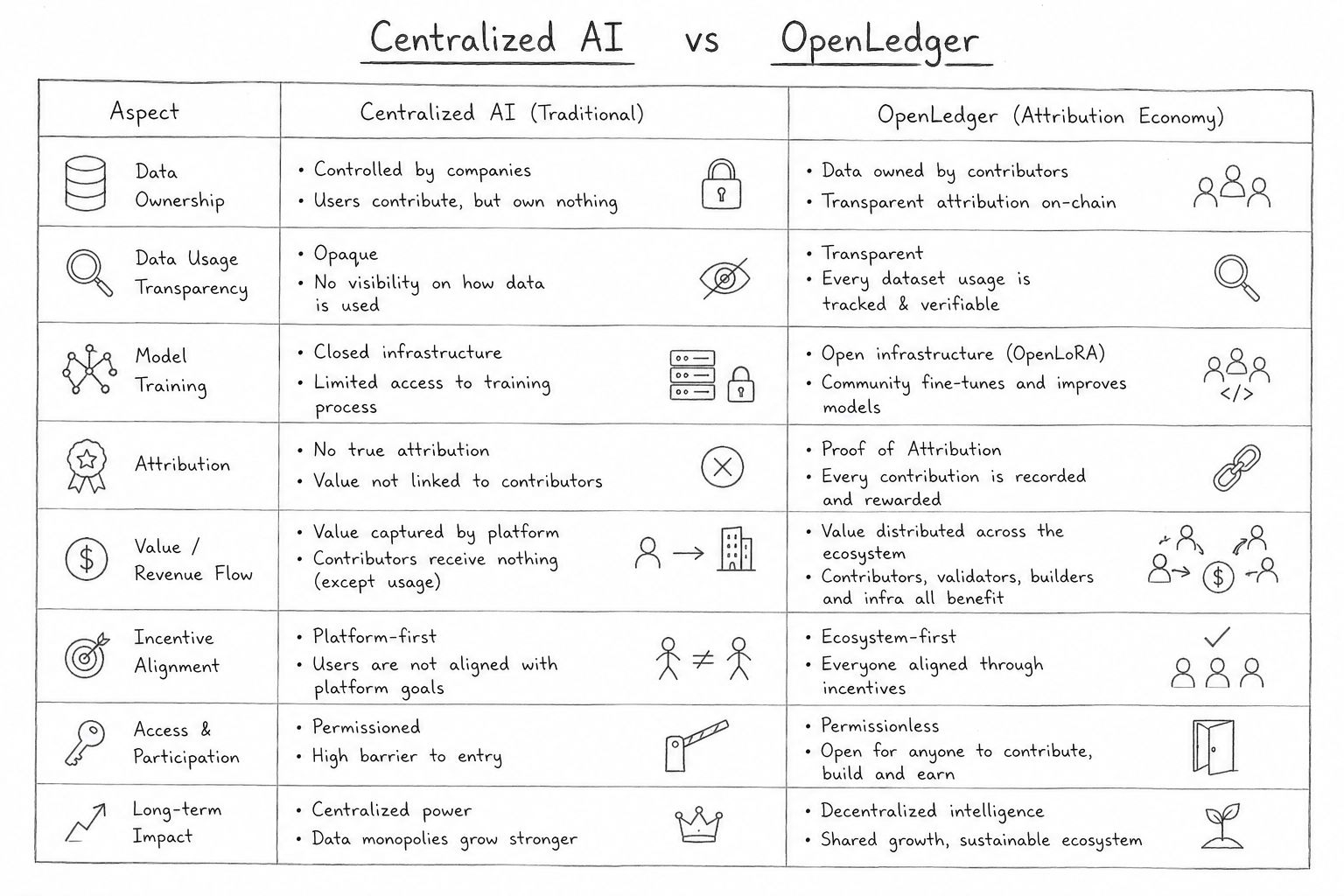
Plus je regardais en profondeur, plus la structure des Datanets commençait à avoir du sens pour moi. Dans les systèmes IA traditionnels, les ensembles de données sont généralement invisibles après le début de l'entraînement. Les utilisateurs contribuent des informations, les entreprises les absorbent, et la propriété disparaît dans une infrastructure fermée. OpenLedger traite les données plus comme une couche économique vivante plutôt que comme une matière première. Les contributeurs, validateurs et créateurs de modèles restent connectés à travers des mécanismes d'attribution liés au cycle de vie lui-même. C'est probablement le premier moment où le protocole a cessé de sembler être un autre récit IA et a commencé à ressembler à un système de coordination. L'architecture semble conçue pour préserver le flux de valeur au lieu de le concentrer.
Je pense que c'est pourquoi la Preuve d'Attribution semble si importante dans l'écosystème. Au début, je pensais que c'était juste un langage de marque, honnêtement. Mais plus je suivais le cycle de vie, plus cela devenait central. $OPEN ne cherche pas simplement à décentraliser l'hébergement de modèles ou l'inférence. Il essaie de suivre qui a réellement contribué à l'intelligence du résultat final. Cela change complètement l'économie. Si un ensemble de données améliore un modèle, l'attribution reste attachée à la valeur générée plus tard. Si un modèle spécialisé réussit après son déploiement, les récompenses ne vont pas seulement au propriétaire du point de terminaison. Le protocole continue d'étendre la visibilité économique à travers tout le pipeline au lieu de la cacher derrière des API.
La phase de déploiement est là où toute l'idée est devenue vraiment intéressante pour moi. La plupart des produits IA traitent le déploiement comme la fin du développement. OpenLedger le traite comme le début de la participation économique. Une fois qu'un modèle est opérationnel, il continue d'interagir avec des validateurs, la demande d'inférence, des contributeurs et des systèmes d'attribution à travers des boucles de récompense continues. Cela crée une dynamique étrange où les modèles se comportent presque comme des actifs numériques productifs au lieu de versions logicielles statiques. Je me suis souvent demandé à quel point cela se sentait différent par rapport aux plateformes IA centralisées où l'extraction de valeur est principalement invisible après le lancement.
Même l'infrastructure technique autour du cycle de vie semble conçue pour la continuité plutôt que pour une attention à court terme. OpenLoRA et ModelFactory rendent l'écosystème modulaire, où les modèles peuvent évoluer, s'adapter et se spécialiser sans reconstruire l'ensemble du pipeline depuis le début. Cette partie m'a en fait plus rappelé l'infrastructure financière que l'infrastructure logicielle. Le protocole semble moins intéressé par la création d'un modèle dominant et plus par la création d'un environnement où l'intelligence spécialisée peut continuellement émerger, se déployer et monétiser grâce à des incitations basées sur l'attribution. C'est une ambition très différente de celle que poursuivent la plupart des projets IA en ce moment.
Les métriques de l'écosystème ont commencé à sembler plus significatives une fois que je les ai vues à travers ce prisme. L'expansion d'OpenLedger vers une infrastructure compatible avec Ethereum semblait soudainement moins un jeu de liquidité et plus une tentative de rendre les économies d'attribution portables à travers les écosystèmes. Le token OPEN a également plus de sens dans ce cadre car il fonctionne moins comme un actif spéculatif et plus comme une infrastructure de coordination entre ensembles de données, validateurs, modèles et activité d'inférence. La plupart des chaînes continuent de rivaliser en utilisant des comptes de transactions ou des classements de TVL, mais OpenLedger semble mesurer quelque chose de beaucoup plus difficile à quantifier : la production d'intelligence économiquement attribuable.
Ce qui me rend prudent, cependant, c'est que le protocole expose ouvertement à quel point ces systèmes peuvent devenir fragiles. Les données de faible qualité, les échecs de gouvernance, le déséquilibre des récompenses et le spam de modèles semblent tous des risques réalistes dans une économie IA ouverte. Étrangement, cette honnêteté a rendu le projet plus crédible à mes yeux. Le livre blanc ne se lit pas comme un fantasme sur l'IA remplaçant tout du jour au lendemain. Il se lit plus comme une ingénierie d'infrastructure construite autour de l'hypothèse que les incitations finissent par échouer à moins d'être constamment ajustées. Ce réalisme est rare sur ce marché en ce moment.
Je ne sais toujours pas si OpenLedger devient finalement dominant ou si les entreprises d'IA centralisées écrasent simplement tout grâce à l'échelle et à la puissance de calcul. Mais je pense que le protocole a identifié un problème que la plupart des gens sous-estiment encore. La bataille IA du futur ne tournera peut-être pas autour de qui possède le plus grand modèle. Elle pourrait tourner autour de qui possède l'attribution, la coordination et la valeur économique entourant l'intelligence elle-même. Les modèles deviennent moins chers chaque mois. L'entraînement devient lentement une commodité. Mais les structures de propriété équitables autour de la valeur générée par l'IA semblent encore non résolues. Et honnêtement, c'est probablement pour ça qu'OpenLedger reste sur mon radar plus longtemps que la plupart des projets IA.