

Chaque fois que le récit Crypto x AI se propage sur le marché, ma première réaction est le doute. La plupart des projets ne sont que des coquilles vides, qui reconditionnent des points de terminaison API de base sous le nom de blockchain. Ils n'ont pas d'infrastructure décentralisée réelle, et disparaissent dès que le cycle se termine. Mais quand j'ai observé @OpenLedger leur économie de données AI décentralisée, la réalité on-chain semblait un peu différente et crédible ici. Ces gens ne se contentent pas de raconter des histoires sur la tokenomics, mais se concentrent sur des pipelines de données vérifiables.

Aujourd'hui, le plus grand goulot d'étranglement de l'intelligence artificielle n'est pas la puissance de calcul, mais plutôt la qualité des données d'entraînement. Les grandes entreprises technologiques monopolisent toutes les données d'Internet sans autorisation et ne compensent pas les utilisateurs. #OpenLedger ce concept renverse la situation.
Son approche dépend de la provenance vérifiable des données, où chaque donnée a un enregistrement clair sur la chaîne. Si vous devez le comprendre simplement, c'est comme une cuisine communautaire où nous apportons nos épices. Un grand livre transparent note qui a apporté quoi, afin que lorsque le plat soit vendu sur le marché, tout le monde reçoive une part équitable.
Le moteur de ce réseau est son consensus Proof of Contribution et son système de validation des nœuds décentralisés. Lorsque qu'un créateur de données télécharge un ensemble de données, les nœuds du réseau les vérifient pour éviter que des acteurs malveillants ne spamment le système. Ceux qui travaillent réellement dur pour créer des ensembles de données précis reçoivent une juste récompense. Pour faire fonctionner tout ce flux, leur jeton natif $OPEN est utilisé.
$OPEN le jeton joue un rôle de couche de règlement centrale pour le staking, les incitations à la validation, les récompenses de contribution de données et la coordination du réseau. Si vous devez exécuter un nœud de validation de données dans le réseau, vous devez staker des jetons $OPEN en tant que garantie pour punir les comportements malveillants. D'autre part, les développeurs d'IA d'entreprise et les studios commerciaux doivent effectuer des paiements et des règlements de facturation en utilisant le même jeton $OPEN pour accéder à des ensembles de données d'entraînement vérifiés sur le marché et utiliser des ressources de calcul.
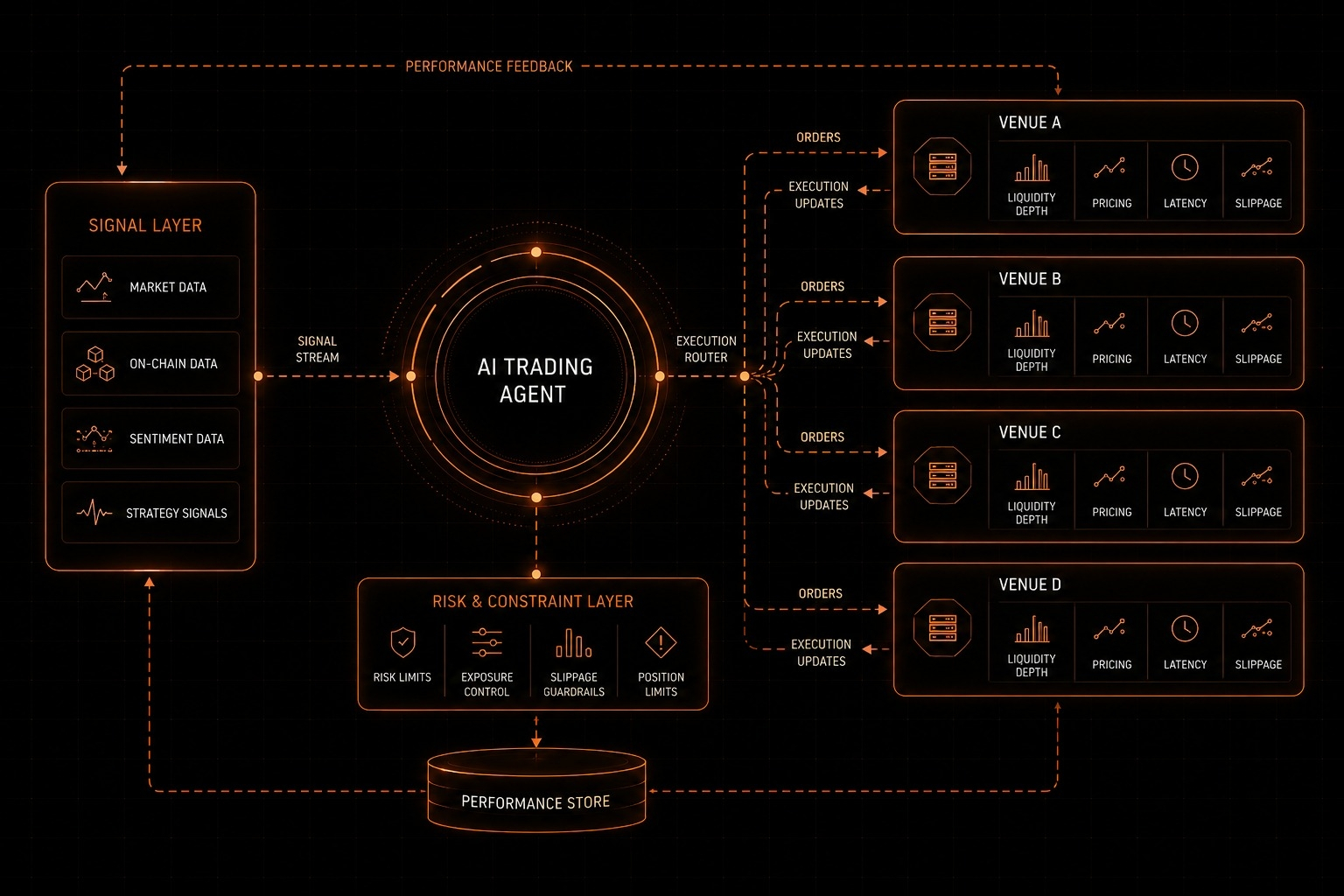
Pour tester ce cadre dans le monde réel, j'ai plongé profondément dans leur Infrastructure AI tokenisée. J'ai trouvé que leur configuration cloud Octoclaw et l'agent de trading intégré avaient un impact pratique très positif. Au départ, je pensais que la configuration de ces outils serait assez complexe, mais comment fonctionne Octoclaw, je l'ai utilisé personnellement et mon expérience a été très fluide. Octoclaw gère efficacement les ressources cloud et exécute les tâches d'IA via des nœuds de validation. Avec cela, leur agent de trading m'a semblé très précis en analysant les interactions sur la chaîne pour prendre des décisions automatisées.
Je pense qu'il est essentiel de comprendre cette exécution automatisée, car les marchés bougent maintenant beaucoup plus vite que le temps de réaction humain. Les agents d'IA n'hésitent pas, ne ressentent pas la fatigue et ne remettent pas en question leurs exécutions. Ils fonctionnent continuellement avec une exécution à la vitesse machine, totalement en dehors de la capacité de réaction humaine. Un trader humain ne peut monitorer que deux ou trois écrans à la fois, tandis qu'un agent de trading AI peut traiter des milliers de flux de données en synchronie avec une faible latence.
Dans des cas d'utilisation réels, cela intervient dans l'exécution d'arbitrage inter-chaînes. Lorsque qu'il y a un léger décalage de prix entre deux échanges décentralisés, Octoclaw calcule automatiquement le chemin du routeur et exécute à la vitesse machine des deux côtés. Après avoir déployé de la liquidité dans les Automated Market Makers lorsque le marché est volatil, cet agent de trading rééquilibre automatiquement les positions via des déclencheurs automatisés pour optimiser le rendement tout en gardant le risque sous contrôle.
Mais sans une gestion des risques solide, les agents de trading à haute vitesse sont une épée à double tranchant. C'est pourquoi l'exécution agentique intègre des garde-fous techniques stricts. Chaque stratégie déployée est étroitement liée à un stop-loss algorithmique. Si une anomalie anormale ou un événement cygne noir survient sur le marché, l'agent coupe instantanément les positions de marché sans émotions et déplace le capital vers des actifs stables et sûrs. De plus, ces agents utilisent une configuration de gaz optimale et des routes RPC privées avant de soumettre des transactions pour éviter les bots MEV et le front-running.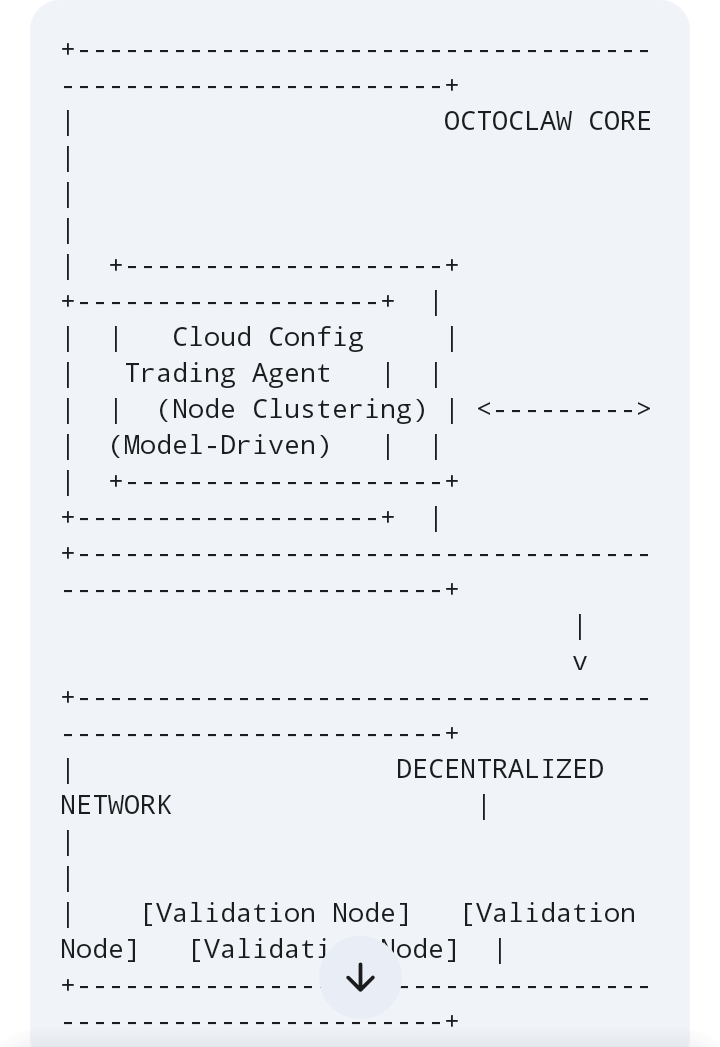
Toutes ces considérations comptent pour moi car OpenLedger construit discrètement une place de marché de données inter-écosystèmes de niveau entreprise. Sa survie ne dépend pas de l'engouement des particuliers, mais de la demande des développeurs d'IA d'entreprise. Lorsque les studios d'IA commerciaux réaliseront qu'ils obtiennent des ensembles de données d'entraînement légalement sûrs et vérifiés d'un marché décentralisé avec une provenance claire, ils adopteront naturellement ce système.
Mais avec cet optimisme, nous devons rester réalistes car maintenir la qualité des données dans des systèmes décentralisés sans autorisation est notoirement difficile. Si les nœuds de validation échouent pour une raison quelconque dans leur consensus, ou si des acteurs malveillants commencent à empoisonner le réseau, le système entier sera victime du principe des ordures qui entrent, ordures qui sortent. Les entreprises d'IA d'entreprise sont très impitoyables, elles exigent une précision absolue pour leurs modèles. Si elles commencent à recevoir des données toxiques de la plateforme, elles retourneront immédiatement aux anciennes agences de données centralisées.
Dans un avenir proche, je ne me concentrerai pas du tout sur les annonces sociales ou les métriques de hype. Pour moi, le vrai signal viendra lorsque nous verrons activement les applications d'IA externes intégrer réellement ces flux de données décentralisés dans leurs workflows quotidiens. Le jeu n'est pas seulement d'être intelligent, mais aussi de disposer d'une capacité de configuration et d'exécution physique. Il est facile d'écrire des choses sur n'importe quel deck, mais le faire évoluer face aux frictions du monde réel est une autre réalité. Si ce réseau peut soutenir une utilisation réelle d'entreprise avec le modèle d'utilité du jeton OPEN, cela marquera un moment solide pour l'IA et Web3.