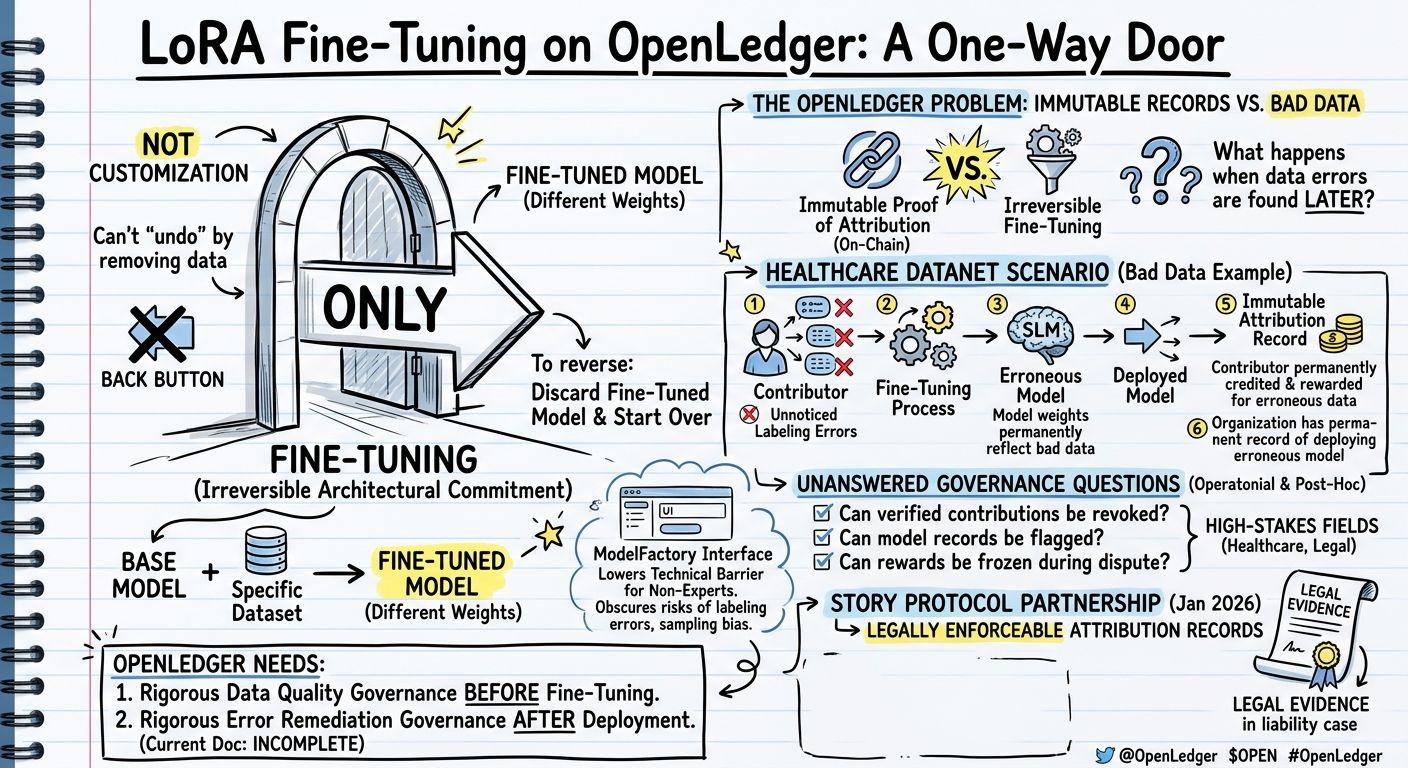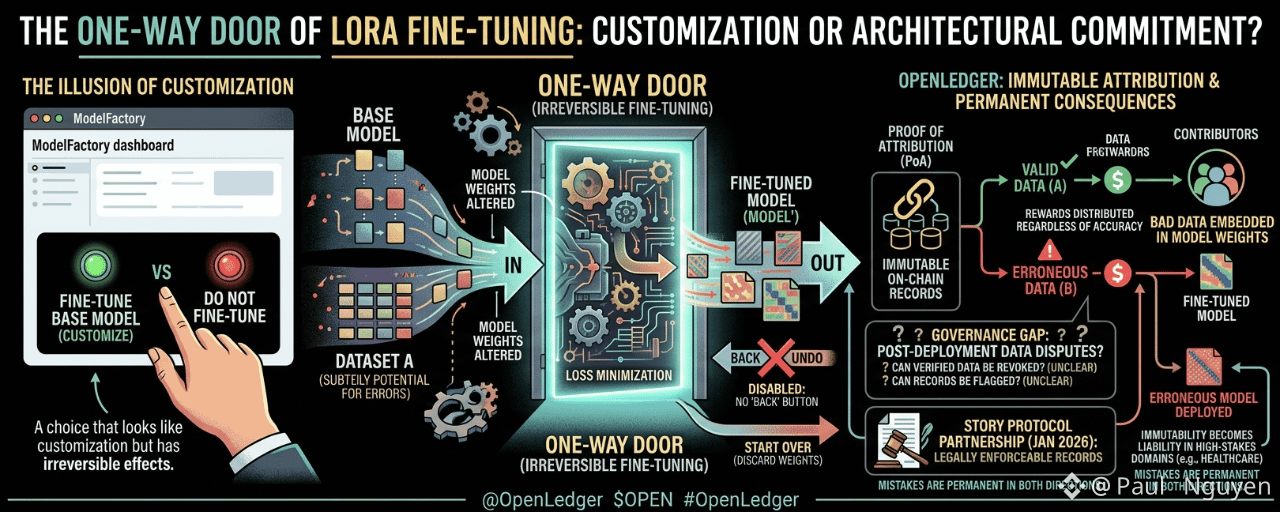
Il y a une décision que chaque constructeur de modèles sur ModelFactory d'OpenLedger prend lorsqu'il lance un run de fine-tuning, une décision qui est présentée dans l'interface comme un choix de personnalisation mais qui est en réalité plus proche d'un engagement architectural irréversible. La décision est de fine-tuner un modèle de base sur un ensemble de données spécifique. Une fois que vous le faites, vous avez un nouveau modèle qui fonctionne différemment du modèle de base d'une manière qui ne peut pas être proprement annulée. Vous ne pouvez pas "annuler" un run de fine-tuning en supprimant les données. Vous pouvez fine-tuner le modèle à nouveau sur des données différentes, ce qui le modifie encore plus. Vous pouvez revenir au modèle de base d'origine et recommencer, en laissant de côté les poids fine-tunés. Mais le modèle fine-tuné spécifique, entraîné sur vos données spécifiques à ce moment-là, est une porte dérobée. Le modèle de base qui entre n'est pas le même que le modèle fine-tuné qui sort, et il n'y a pas de bouton de retour.
Le système de preuve d'attribution d'OpenLedger est conçu pour retracer quelles données d'entraînement ont influencé quelle sortie de modèle, et il enregistre cette lignée de manière immuable sur la chaîne. L'immuabilité est le bon design pour l'économie d'attribution : si les enregistrements d'attribution pouvaient être altérés, les contributeurs ne pourraient pas avoir confiance que leurs parts de récompense resteraient précises au fil du temps. Mais la combinaison d'enregistrements d'attribution immuables et d'un ajustement fin irréversible crée une situation spécifique que la documentation ne traite pas explicitement : que se passe-t-il lorsque les données d'entraînement sur lesquelles un modèle a été affiné s'avèrent être erronées, manipulées ou légalement grevées ?
Imaginez qu'un contributeur de Datanet dans le secteur de la santé télécharge un ensemble de données contenant des erreurs d'étiquetage. Les erreurs ne sont pas évidentes, les données ont passé le processus de vérification d'OpenLedger, et un SLM médical est affiné sur les données erronées. Le modèle est déployé. Des requêtes sont exécutées. Les récompenses d'attribution sont distribuées proportionnellement aux contributeurs de données, y compris le contributeur dont l'ensemble de données erroné fait maintenant partie des poids du modèle. L'enregistrement d'attribution est sur chaîne et immuable. L'ajustement fin est irréversible. Même si l'erreur de données est découverte plus tard, les poids du modèle reflètent déjà l'influence des mauvaises données. La réentraînement sur des données corrigées produit un modèle différent, mais le modèle original affiné et son enregistrement d'attribution existent toujours sur la chaîne. Le contributeur qui a téléchargé des données erronées a des preuves sur chaîne de sa contribution et a reçu des récompenses pour cela. L'organisation qui a déployé le modèle erroné a un enregistrement permanent sur chaîne d'avoir agi ainsi.
La réponse d'OpenLedger à ce scénario dépend de la manière dont ses systèmes de gouvernance et de qualité des données gèrent les litiges de qualité des données a posteriori. La documentation décrit un processus de vérification sur chaîne pour les contributions, mais ne précise pas ce qui se passe lorsqu'une contribution vérifiée est ultérieurement trouvée erronée. Une contribution vérifiée peut-elle être révoquée ? L'enregistrement d'attribution d'un modèle peut-il être signalé comme basé sur des données contestées ? Le système de gouvernance peut-il geler les récompenses à un contributeur dont les données ont été jugées erronées pendant qu'un examen est en cours ? Ce sont des questions de gouvernance opérationnelle qui ont une importance énorme pour un système d'attribution d'IA opérant dans des contextes de santé ou juridiques où des données d'entraînement erronées ont des conséquences réelles, et elles ne sont pas répondues dans la documentation publique.
L'interface sans code de ModelFactory réduit la barrière technique pour les contributeurs qui n'ont peut-être pas l'expertise ML pour reconnaître quand leurs données sont formatées d'une manière qui causera des erreurs d'étiquetage, des biais d'échantillonnage ou d'autres problèmes de qualité dans le modèle résultant. L'interface est accessible. Les conséquences de l'entraînement d'un modèle sur de mauvaises données et de son déploiement ne sont pas accessibles : elles sont obscurcies derrière le tableau de bord de formation propre et la distribution de récompenses d'attribution. OpenLedger a besoin d'un cadre de litige et de remédiation de la qualité des données qui aborde la découverte d'erreurs de données après déploiement. Sans cela, la combinaison d'enregistrements immuables et d'ajustements fins irréversibles crée un système où les erreurs sont permanentes dans les deux sens : les bonnes contributions de données sont créditées de manière permanente, et les mauvaises contributions de données sont intégrées de manière permanente dans les poids du modèle et enregistrées de manière permanente comme valides sur la chaîne.
Le partenariat Story Protocol de janvier 2026 ajoute une force exécutoire légale aux enregistrements d'attribution, ce qui rend la permanence de ces enregistrements à la fois plus précieuse et plus conséquente. Un enregistrement d'attribution légalement exécutoire pour un modèle de santé formé sur des données erronées n'est pas seulement une entrée de blockchain. C'est un document légal qui pourrait être utilisé comme preuve dans une affaire de responsabilité impliquant les résultats cliniques de ce modèle. OpenLedger construit l'infrastructure pour un domaine à enjeux élevés. L'irréversibilité de l'ajustement fin et l'immuabilité des enregistrements d'attribution sont les bonnes propriétés pour une économie d'attribution fonctionnelle. Ce sont également des propriétés qui exigent une gouvernance rigoureuse de la qualité des données avant qu'un modèle ne soit affiné et une gouvernance rigoureuse de la remédiation des erreurs après déploiement. La documentation actuelle décrit la première partie de manière incomplète et la seconde partie pas du tout.