La plupart des gens parlent encore de l'IA de la même manière qu'ils parlaient de l'informatique en nuage il y a des années.
Plus d'échelle.
Plus de calcul.
Des modèles plus grands.
Des réponses plus rapides.
Et honnêtement, ça avait du sens pendant un certain temps car toute la course à l'IA était essentiellement une question de qui pouvait entraîner les plus grands systèmes en premier.
Mais dernièrement, je pense que le marché regarde peut-être complètement la mauvaise couche.
Le véritable goulot d'étranglement n'est probablement plus l'intelligence.
C'est la propriété.
Qui possède les données ?
Qui est récompensé quand l'IA devient rentable ?
Qui bénéficie réellement après avoir contribué des connaissances, des corrections, des retours ou du matériel de formation ?
En ce moment, la plupart des systèmes d'IA fonctionnent comme d'énormes trous noirs d'informations. Les gens leur fournissent des données chaque jour, les modèles s'améliorent silencieusement en arrière-plan, les entreprises gagnent des milliards, et les contributeurs originaux disparaissent complètement du côté économique.
Ce modèle fonctionne au début.
Je ne suis pas sûr que cela fonctionne pour toujours.
C'est une des raisons pour lesquelles OpenLedger attire plus d'attention dernièrement.
À première vue, OpenLedger ressemble à un autre projet IA + blockchain. Le marché en a déjà des centaines. La plupart parlent d'IA décentralisée, de couches de calcul, de marchés d'inférence ou de coordination GPU.
Mais le véritable focus d'OpenLedger semble différent une fois que vous passez du temps à le rechercher.
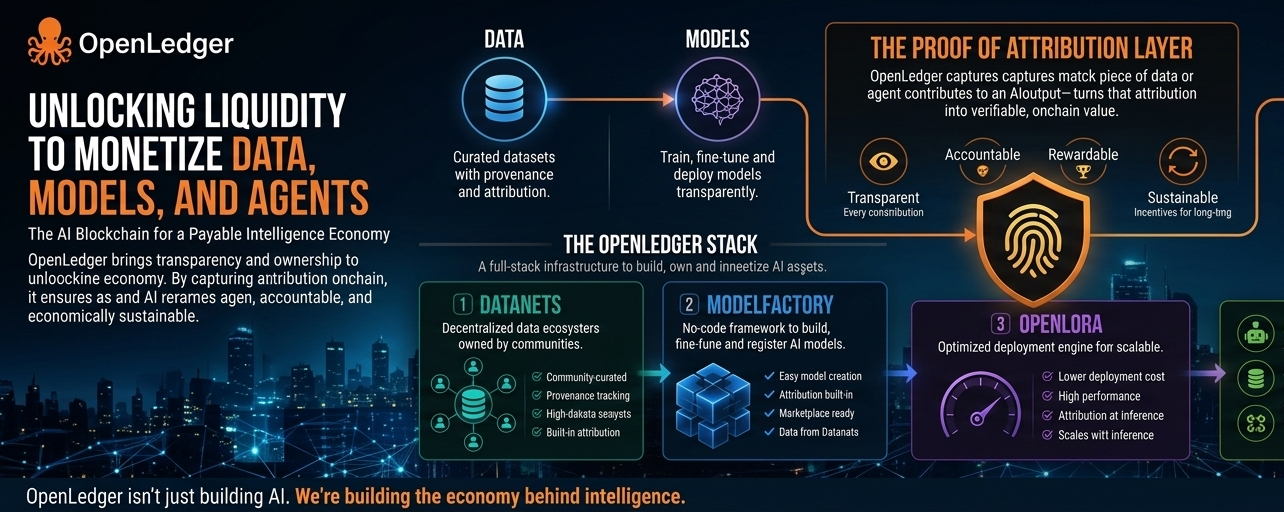
Le projet construit une infrastructure autour de quelque chose de beaucoup plus spécifique : l'attribution.
Pas juste stocker l'IA sur la blockchain.
En fait, suivre qui a contribué à la création de l'intelligence et rendre ces contributions économiquement mesurables.
Cela change complètement la conversation.
Au lieu de demander :
« Comment construisons-nous une IA plus grande ? »
OpenLedger demande :
« Comment construisons-nous des économies d'IA où les contributeurs sont visibles ? »
C'est un problème beaucoup plus grand que la plupart des gens ne le réalisent.
L'industrie actuelle de l'IA fonctionne sur un travail invisible.
Chaque ensemble de données, correction, annotation, boucle de rétroaction, ajustement de préférence humaine ou contribution spécialisée améliore la qualité des modèles. Mais la plupart des contributeurs ne reçoivent jamais de gains à long terme après que le modèle soit devenu commercialement réussi.
OpenLedger pense que la blockchain peut corriger une partie de cela.
L'idée centrale derrière le réseau est appelée Preuve d'Attribution.
Le concept est relativement simple à expliquer mais beaucoup plus difficile à construire techniquement.
Le système tente de suivre comment les ensembles de données, les modèles et les contributeurs influencent les résultats de l'IA au fil du temps. Au lieu que les contributions disparaissent dans un énorme modèle centralisé, OpenLedger veut qu'elles soient enregistrées de manière transparente afin que les contributeurs puissent continuer à gagner de la valeur chaque fois que leurs données ou leur intelligence aident à générer des résultats plus tard.
Cela crée une structure économique complètement différente pour l'IA.
Normalement, les entreprises d'IA monétisent l'accès.
OpenLedger veut que les systèmes d'IA monétisent la participation.
Et honnêtement, ce changement semble plus grand que ce que les gens comprennent actuellement.
Parce qu'une fois que l'attribution existe correctement, les données elles-mêmes deviennent programmables.
Les contributeurs cessent d'être invisibles.
Les connaissances spécialisées deviennent monétisables.
Les modèles d'IA deviennent connectés aux personnes qui les ont améliorés.
Cela commence à ressembler moins à un logiciel traditionnel et plus à une économie numérique fonctionnelle.
Une chose que j'ai trouvée particulièrement intéressante en recherchant OpenLedger est à quel point le projet se concentre sur une IA spécialisée plutôt que sur de gigantesques modèles généralistes.
Cela a en fait beaucoup de sens.
Le marché a passé des années à chasser de grands modèles frontières parce que plus gros semblait plus impressionnant. Mais les systèmes d'IA pratiques semblent de plus en plus récompenser la spécialisation à la place.
Une IA de santé formée sur des ensembles de données médicales vérifiées peut avoir plus d'importance qu'un énorme modèle générique.
Une IA axée sur la finance formée sur de réelles intelligences de marché peut surpasser des systèmes plus larges pour l'analyse de trading.
Une IA juridique construite autour d'ensembles de données juridiques fiables peut devenir beaucoup plus précieuse que des résultats généralisés.
L'infrastructure d'OpenLedger semble conçue autour de cette direction exacte.
Le projet introduit quelque chose appelé Datanets, qui sont essentiellement des environnements décentralisés où les communautés peuvent créer et gérer ensemble des ensembles de données spécialisés.
Pense à ça une seconde.
Au lieu que des modèles d'IA grattent sans fin des informations aléatoires sur Internet, des communautés spécialisées pourraient théoriquement créer des ensembles de données de meilleure qualité tout en maintenant l'attribution attachée de manière permanente.
Cela change entièrement les incitations.
Parce que si les contributeurs savent qu'ils continuent à bénéficier de l'utilisation plus tard, ils ont soudainement une raison de maintenir la qualité au lieu de simplement déverser des informations dans des systèmes gratuitement.
Le projet a également construit des systèmes comme ModelFactory et OpenLoRA pour aider les développeurs à créer, peaufiner et déployer des modèles d'IA plus efficacement.
Mais honnêtement, je pense que l'infrastructure compte moins que la direction elle-même.
Le récit plus large ici est qu'OpenLedger traite l'IA comme une économie plutôt qu'un produit.
Cela semble important.
Surtout maintenant que les agents IA autonomes deviennent un véritable sujet de discussion dans le crypto et la tech.
La plupart des gens imaginent encore l'IA comme des chatbots ou des assistants.
Mais la prochaine phase ressemble probablement à quelque chose de très différent.
Les agents IA géreront probablement des portefeuilles.
Exécuter des trades.
Acheter du calcul.
Accéder à des ensembles de données.
Exécuter des flux de travail.
Coordonner des applications.
Interagir avec des contrats intelligents.
Peut-être même négocier avec d'autres agents de manière autonome.
Une fois que cela se produit, l'attribution devient soudainement une infrastructure critique.
Parce que si les systèmes d'IA deviennent des acteurs économiques eux-mêmes, les marchés auront finalement besoin de moyens pour suivre d'où provient l'intelligence et qui mérite d'être compensé.
Sans attribution, l'extraction de valeur devient infinie.
Avec l'attribution, les économies d'IA commencent à devenir durables.
C'est essentiellement la thèse plus large d'OpenLedger.
Et honnêtement, cela semble beaucoup plus aligné avec la direction que prend l'IA que beaucoup des narrations plus simples d'« IA token » flottant sur le marché actuellement.
Une autre chose qui a attiré mon attention était la collaboration d'OpenLedger autour des systèmes de formation d'IA avec droits clarifiés.
Cette partie compte plus que ce que les gens pensent.
L'industrie de l'IA se dirige lentement vers une collision avec les lois sur la propriété intellectuelle, les droits des créateurs et les questions de propriété des ensembles de données. En ce moment, l'espace opère encore dans une zone grise parce que la régulation n'a pas encore entièrement rattrapé.
Mais finalement, les systèmes d'IA à grande échelle auront probablement besoin de preuves plus claires montrant :
d'où proviennent les données d'entraînement,
si les contributeurs ont approuvé l'utilisation,
et comment les créateurs sont compensés.
OpenLedger semble se préparer pour cet avenir tôt au lieu d'attendre le problème plus tard.
Et cela pourrait finir par être l'un des plus grands avantages positionnels du projet.
Parce que l'infrastructure construite avant la régulation devient généralement plus précieuse une fois que la régulation arrive.
Bien sûr, rien de tout cela ne garantit le succès.
Les défis techniques ici sont énormes.
Suivre l'attribution avec précision à travers des systèmes d'IA complexes est extrêmement difficile.
Les systèmes de récompense peuvent être manipulés.
La qualité des ensembles de données devient difficile à vérifier.
Échelonner une infrastructure décentralisée contre des géants de l'IA centralisée est également incroyablement difficile.
Mais la direction elle-même semble très réelle.
L'IA évolue lentement au-delà des logiciels.
Cela devient une infrastructure économique.
Et une fois que l'intelligence devient monétisable à grande échelle, la question n'est plus seulement :
« Quelle IA est la plus intelligente ? »
La question plus grande devient :
« Qui est payé lorsque l'intelligence crée de la valeur ? »
C'est la partie qu'OpenLedger essaie de résoudre.
Et honnêtement, je pense que le marché sous-estime encore à quel point ce problème peut devenir important au cours des prochaines années.
\u003cc-439/\u003e

