
Les modèles d'AI attirent la plupart des attentions. Des modèles plus gros. Des sorties plus intelligentes. Des réponses plus rapides.
Mais il y a un problème plus silencieux en dessous de tout ça : la qualité des données.
L'AI n'est utile que tant que l'information qu'elle apprend est de qualité. Et aujourd'hui, une grande partie de ces données se trouve dans des systèmes fermés contrôlés par un petit nombre de plateformes. Alors que le contenu généré par l'AI inonde Internet, il devient de plus en plus difficile de trouver des données fiables, spécialisées et de haute qualité, et non pas plus facile.
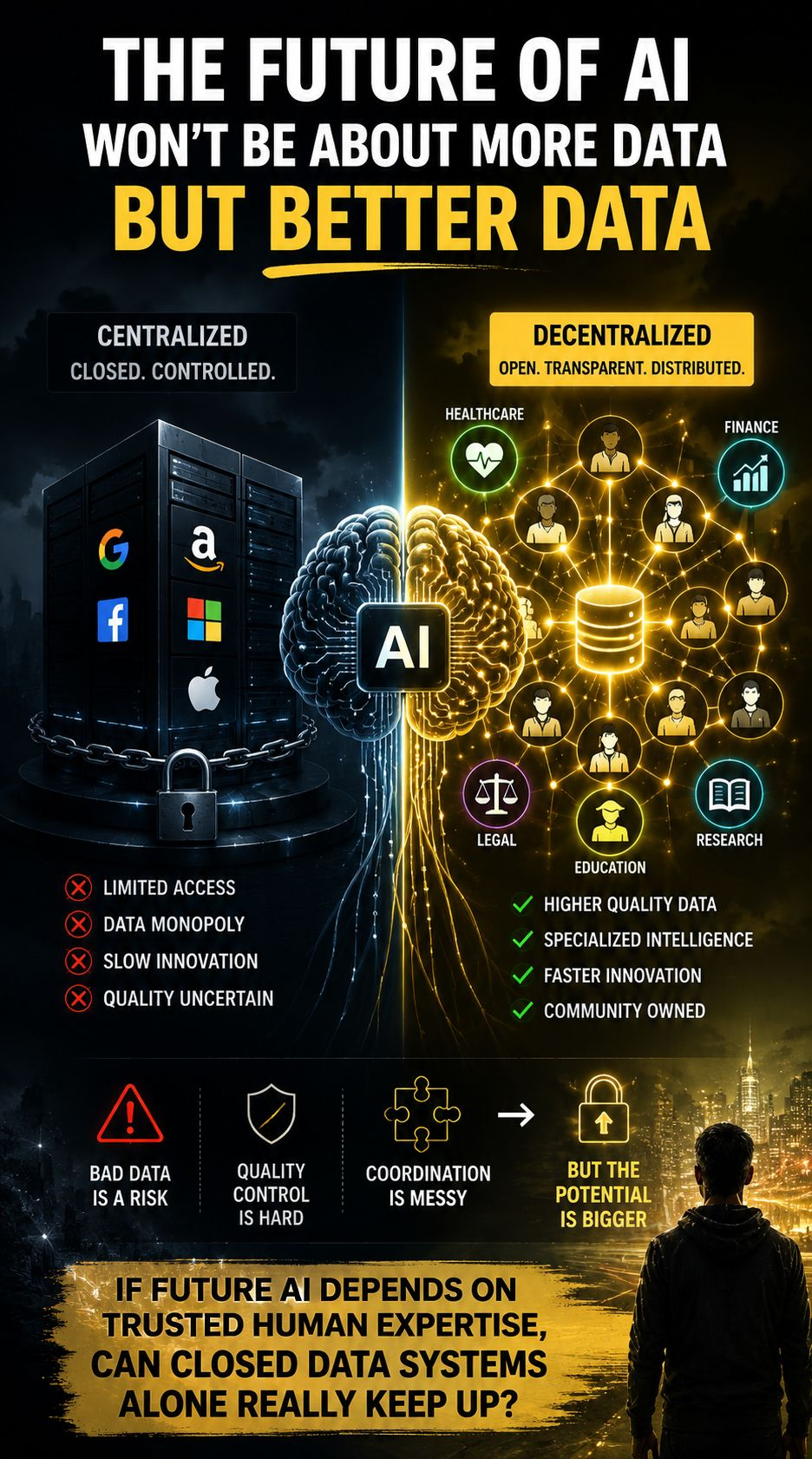
C'est pourquoi les données AI décentralisées ont de l'importance.
L'argument est simple : l'AI de demain ne gagnera peut-être pas grâce à plus de données, mais grâce à de meilleures données.
Une IA dans le secteur de la santé ne peut pas se fier au contenu aléatoire d'internet. Un modèle financier a besoin d'une vision précise du marché. Une IA juridique dépend d'une expertise de confiance. L'intelligence spécialisée nécessite des ensembles de données spécialisés.
Les systèmes de données décentralisés tentent de résoudre cela en rendant les contributions plus ouvertes, transparentes et distribuées au lieu de dépendre entièrement de pipelines centralisés.
L'implication plus grande est souvent ignorée : si la connaissance humaine de haute qualité devient la ressource la plus précieuse pour l'IA, les systèmes qui collectent et organisent cette intelligence peuvent être tout aussi importants que les modèles eux-mêmes.
Bien sûr, la décentralisation crée des défis. Le contrôle de la qualité est difficile, la coordination est chaotique, et les mauvaises données restent un risque.
Cependant, une question devient de plus en plus pressante :
Si l'IA future dépend de l'expertise humaine de confiance, les systèmes de données fermés peuvent-ils vraiment suivre ?
