
OpenLoRA : Le fossé entre l'éducation à l'IA et l'implémentation pratique
L'industrie de l'IA se concentre souvent sur le développement de modèles de plus en plus grands et intelligents, mais le déploiement est un autre défi qui influence la capacité de l'IA à évoluer dans des scénarios réels. Si servir un modèle puissant nécessite une infrastructure coûteuse, une latence élevée et des ressources GPU dédiées pour chaque tâche spécialisée, cela n'a que peu d'utilité.
C'est ici qu'OpenLoRA d'OpenLedger fait la différence.
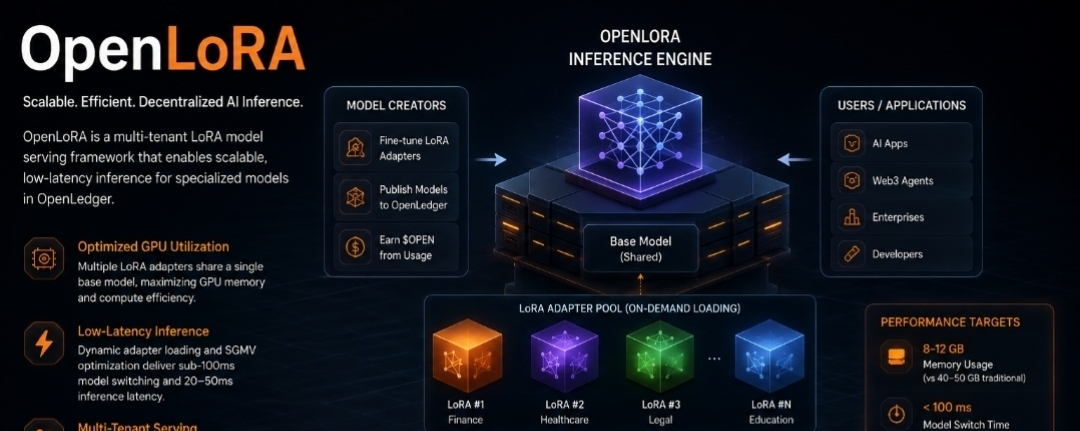
Un cadre de service de modèle LoRA multi-tenant appelé OpenLoRA a été créé pour fournir une inférence à faible latence et évolutive pour les modèles d'IA spécialisés. OpenLoRA permet à des milliers de modèles spécialisés de partager un modèle de base commun tout en chargeant dynamiquement uniquement les adaptateurs nécessaires, supprimant ainsi le besoin de déployer des instances GPU séparées pour chaque modèle affiné. Cela réduit les coûts d'exploitation et augmente considérablement l'efficacité.
L'utilisation de l'IA traditionnelle entraîne souvent des inefficacités significatives :
• Différents modèles utilisent différentes quantités de mémoire GPU.
• Le coût de l'infrastructure augmente avec l'échelle.
• Il y a des délais lors du changement entre les modèles spécialisés.
• Les ressources GPU sont toujours sous-utilisées.
OpenLoRA utilise un certain nombre d'innovations significatives pour résoudre ces problèmes :
Infrastructure GPU pour plusieurs locataires
Plutôt que de charger à plusieurs reprises des modèles entiers, plusieurs modèles LoRA partagent un seul modèle de base pré-entraîné. Cela augmente l'efficacité computationnelle tout en réduisant la surcharge de mémoire GPU.
Chargement dynamique des adaptateurs
Les adaptateurs ne sont chargés que lorsque nécessaire, et une fois l'inférence terminée, ils sont déchargés. Les délais de démarrage à froid sont réduits et un changement rapide de modèle est rendu possible en maintenant le modèle de base en mémoire.
Optimisation du SGMV
Pour les charges de travail d'inférence, la multiplication de matrices-vecteurs segmentée maintient des schémas d'accès à la mémoire optimaux tout en facilitant l'exécution efficace des lots.
Planification GPU avec intelligence
Pour maximiser le débit et maintenir un équilibre des charges de travail à travers les ressources, les requêtes sont attribuées dynamiquement en fonction de la mémoire disponible et des exigences de lot.
Les objectifs de performance sont notables :
• Utilisation de la mémoire : 8–12 Go au lieu de 40–50 Go dans les méthodes de déploiement conventionnelles
• Le temps de changement entre les modèles est inférieur à 100 ms.
• Débit : plus de 2000 tokens par seconde
• Latence : environ 20–50 ms
Le fait qu'OpenLoRA soit plus qu'un simple cadre d'inférence rend cela particulièrement intrigant pour l'IA décentralisée. Cela crée un système où les contributeurs peuvent être rémunérés en fonction de l'utilisation du modèle et de l'influence en s'intégrant dans l'écosystème plus vaste d'OpenLedger, qui comprend Datanets et Proof of Attribution. La question "Qui a le plus grand modèle ?" pourrait céder la place à "Qui peut déployer l'intelligence efficacement à grande échelle ?" à mesure que l'IA évolue. Selon OpenLoRA, une exécution plus intelligente pourrait être tout aussi importante pour l'avenir de l'IA que des modèles plus intelligents.