Je suis resté fixé sur mon écran un moment aujourd'hui, sans vraiment suivre les prix, juste en tombant dans un terrier de lapin auquel je ne m'attendais pas. J'ai commencé parce que j'étais curieux de quelque chose d'ennuyeux : qui possède réellement les données qui entraînent les modèles d'IA sur lesquels tout le monde travaille en ce moment.
Alors j'ai commencé à fouiller @OpenLedger et je ne m'attendais pas à grand-chose, honnêtement. Encore une présentation d'IA plus blockchain. J'en ai lu une centaine. Mais j'ai continué parce que quelque chose dans la façon dont le système est structuré semblait différent de l'angle auquel je m'attendais.
Voici le truc que je ne pouvais pas me sortir de la tête.
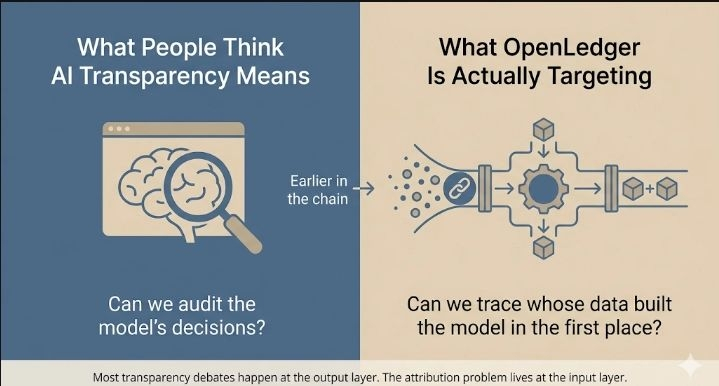
Tout le monde parle de transparence en IA comme si cela signifiait que vous pouvez voir le raisonnement du modèle, voir ses sorties, auditer ses décisions. C'est la version populaire du problème.
Mais OpenLedger pointe vers quelque chose plus tôt dans la chaîne : les données elles-mêmes. Pas le comportement du modèle après l'entraînement. La provenance de ce qui a été utilisé pour l'entraînement au départ.
Et quand je me suis vraiment posé avec ça, j'ai réalisé que je pensais à la mauvaise couche tout ce temps.
La façon dont la plupart des systèmes d'IA fonctionnent, et je veux dire même ceux que les gens appellent "ouverts", la pipeline de données est essentiellement invisible. Une entreprise ingère des données de quelque part, entraîne un modèle, et au moment où vous interagissez avec lui, il n'y a pas de trace.
Vous ne pouvez pas demander : de qui étaient ces données ? Ont-elles été utilisées avec permission ? Quelqu'un a-t-il été payé ? Les réponses ne sont tout simplement pas là. Le modèle existe. Les données qui l'ont créé ne le sont pas, du moins pas d'une manière récupérable.
Le mécanisme de Proof of Attribution d'OpenLedger essaie essentiellement de rendre cette trace permanente. Chaque jeu de données téléchargé, chaque contribution à l'entraînement d'un modèle est enregistrée sur la chaîne. Pas comme une revendication marketing. Comme une véritable entrée dans le registre que n'importe qui peut tracer. Un contributeur de données dans, disons, un Datanet médical ne se contente pas de télécharger et d'espérer recevoir des crédits. L'attribution est inscrite dans la chaîne, et lorsque ces données influencent la sortie d'un modèle, la récompense revient automatiquement.
Je pensais que c'était surtout théorique au début. Puis j'ai regardé comment la structure du token de gouvernance fonctionne : les détenteurs de OPEN convertissent en GOPEN pour participer aux décisions du protocole, y compris les paramètres d'attribution. Donc la communauté ne bénéficie pas seulement de la transparence, elle maintient activement les règles qui définissent ce qui compte comme une attribution valide.
C'est quelque chose de différent de ce que la plupart des projets veulent dire quand ils parlent de "gouvernance communautaire".
Mais voici la partie qui me dérange vraiment.
L'attribution sur la chaîne ne fonctionne que si la contribution de données elle-même est honnête. OpenLedger peut enregistrer qu'un jeu de données a été téléchargé. Il peut suivre quand ces données influencent un modèle. Ce qu'il ne peut pas vérifier complètement, du moins pas encore, d'après ce que je peux dire, c'est si les données ont été légitimement sourcées avant d'entrer dans la chaîne.
Si quelqu'un télécharge des données récupérées ou usurpées et que la couche d'attribution enregistre fidèlement sa contribution, la transparence est réelle mais l'équité ne l'est pas. Le registre est précis. L'acte sous-jacent ne l'est pas.
Ce n'est pas un petit caveat. Tout le poids moral de ce système repose sur l'hypothèse que ce qui est attribué est propre. Et en ce moment, je ne suis pas sûr qu'il existe un mécanisme assez robuste pour attraper cela à grande échelle.
Je continuais à y penser comme… imaginez un système de reçus où chaque transaction est parfaitement enregistrée, mais personne ne vérifie si les biens vendus ont été volés. La comptabilité est impeccable. Le problème est en amont.
Peut-être que c'est soluble. Le partenariat de Story Protocol avec OpenLedger essaie au moins de créer des normes de licence légale pour les données d'entraînement de l'IA, ce qui ajouterait une couche de conformité par-dessus la couche d'attribution.
C'est la bonne direction. Mais c'est encore tôt, et plus le problème est difficile, plus j'ai tendance à surveiller ceux qui le testent réellement par rapport à ceux qui se contentent de le décrire.
Les 2 millions de OPEN Yapper Arena fonctionnant en parallèle sont un signal intéressant, au fait. Un incitatif d'engagement au-dessus d'un système d'attribution. Ce qui signifie qu'en ce moment, le signal le plus fort sur la chaîne n'est pas "les données ont été utilisées équitablement", mais "la personne a parlé de ce projet pendant six mois."
Ils mesurent des choses différentes. L'un est important pour l'intégrité de l'IA. L'autre est important pour le prix du token.
Quoi qu'il en soit. Le marché fait encore ce mouvement latéral qu'il fait depuis un moment. Je reviendrai probablement là-dessus lorsque l'équipe et les déblocages des investisseurs commenceront à bouger en septembre et je verrai si l'activité d'attribution s'est vraiment intensifiée ou si le registre ne fait que documenter du bruit social.