Après avoir passé plus de temps à faire des recherches @OpenLedger sur l'architecture, je pense que beaucoup de gens regardent encore le projet sous le mauvais angle. L'idée principale n'est peut-être pas la génération d'IA elle-même, mais l'infrastructure requise pour rendre les données d'IA économiquement responsables.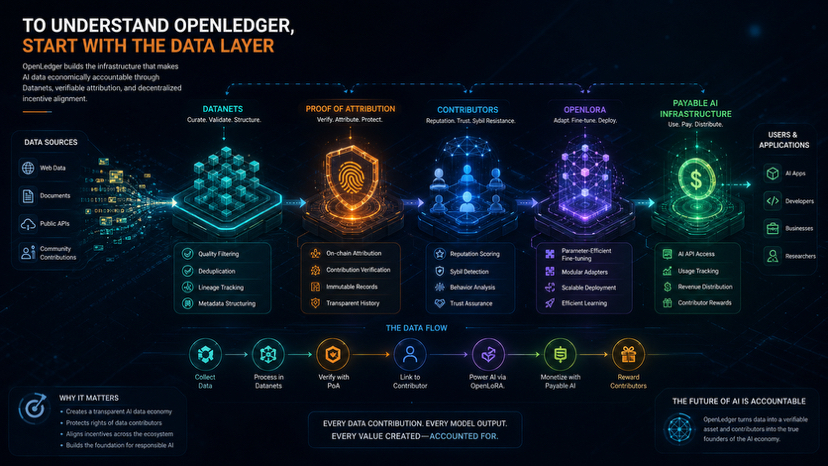
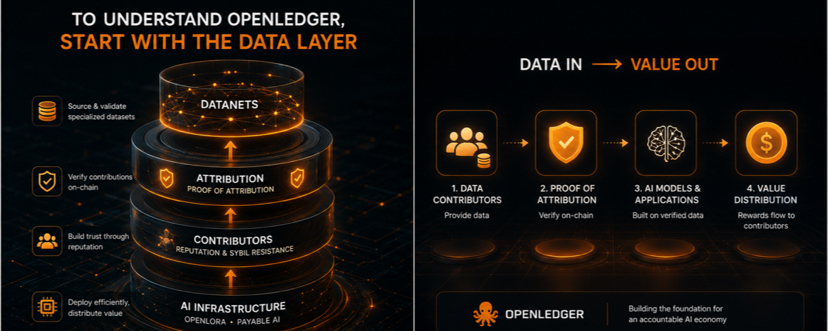
La plupart des systèmes d'IA aujourd'hui dépendent encore de gigantesques ensembles de données collectées sans attribution transparente. OpenLedger semble aborder cela différemment grâce aux Datanets et à la Preuve d'Attribution, où les ensembles de données, les contributeurs et les résultats des modèles peuvent être liés dans une structure mesurable sur la chaîne.
Ce qui rend cela encore plus intéressant, c'est le flux d'exécution derrière. Au lieu de simplement parler de l'IA décentralisée de manière théorique, l'écosystème connecte progressivement plusieurs couches ensemble :
• Datanets pour sourcer et valider des ensembles de données spécialisés
• Mécanismes de réputation des contributeurs et résistance à la Sybil
• OpenLoRA pour une efficacité de déploiement de modèles évolutifs
• Infrastructure IA payable pour la distribution de valeur liée à l'utilisation de l'IA
Si quelqu'un veut vraiment creuser OpenLedger, je pense que la meilleure approche c'est de ne pas commencer par les discussions sur les tokens, mais de comprendre comment les données circulent dans l'écosystème :
Qui contribue aux données ?
Comment l'attribution est-elle vérifiée ?
Comment la contribution peut-elle finalement devenir une valeur économique mesurable ?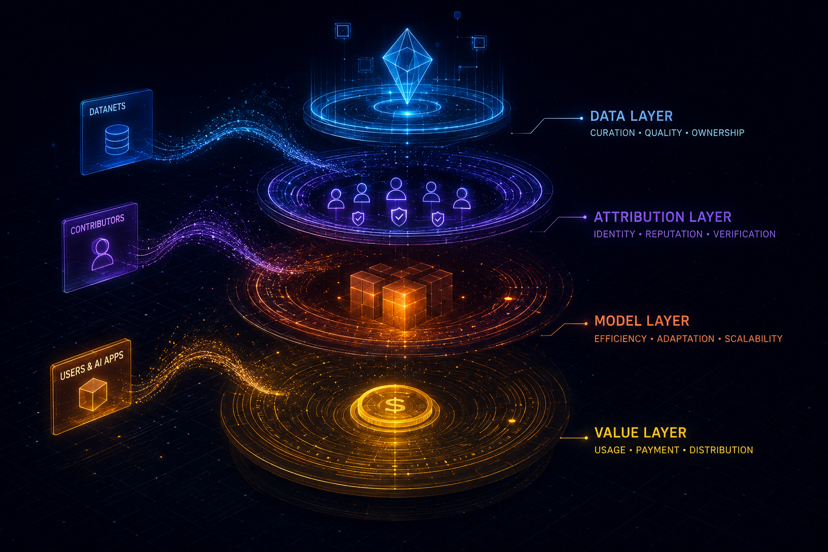
Cela pourrait finalement devenir l'une des questions les plus importantes dans la future économie de l'IA.
