
J'ai traîné dans le monde des cryptos assez longtemps pour savoir quand un projet essaie trop de se donner de l'importance, et quand quelque chose mérite au moins un second regard. OpenLedger se trouve dans cet espace intermédiaire un peu gênant pour moi. Il parle d'IA, de données, de modèles, d'agents, d'attribution, de liquidité et de propriété tout en même temps, ce qui, normalement, me ferait décrocher. Mais je remarque que celui-ci ne se contente pas de répéter le discours habituel "IA plus blockchain". On dirait qu'il tourne autour d'un vrai problème, même si je ne suis pas encore sûr qu'il puisse le résoudre.
La chose qui me frappe toujours avec des projets comme celui-ci, c'est que l'histoire semble plus propre que la réalité. Sur le papier, cela a du sens. Si les données ont de la valeur, alors les personnes qui contribuent aux données devraient être payées. Si des modèles sont construits à partir d'entrées partagées, peut-être que les personnes derrière ces entrées devraient avoir une sorte de revendication. Si des agents vont faire un travail utile, peut-être qu'il devrait y avoir un moyen de suivre ce qu'ils ont utilisé et d'où cela vient. Tout cela semble raisonnable. Presque trop raisonnable. La crypto a l'habitude de faire en sorte que des idées raisonnables semblent inévitables juste avant que le bazar ne commence.
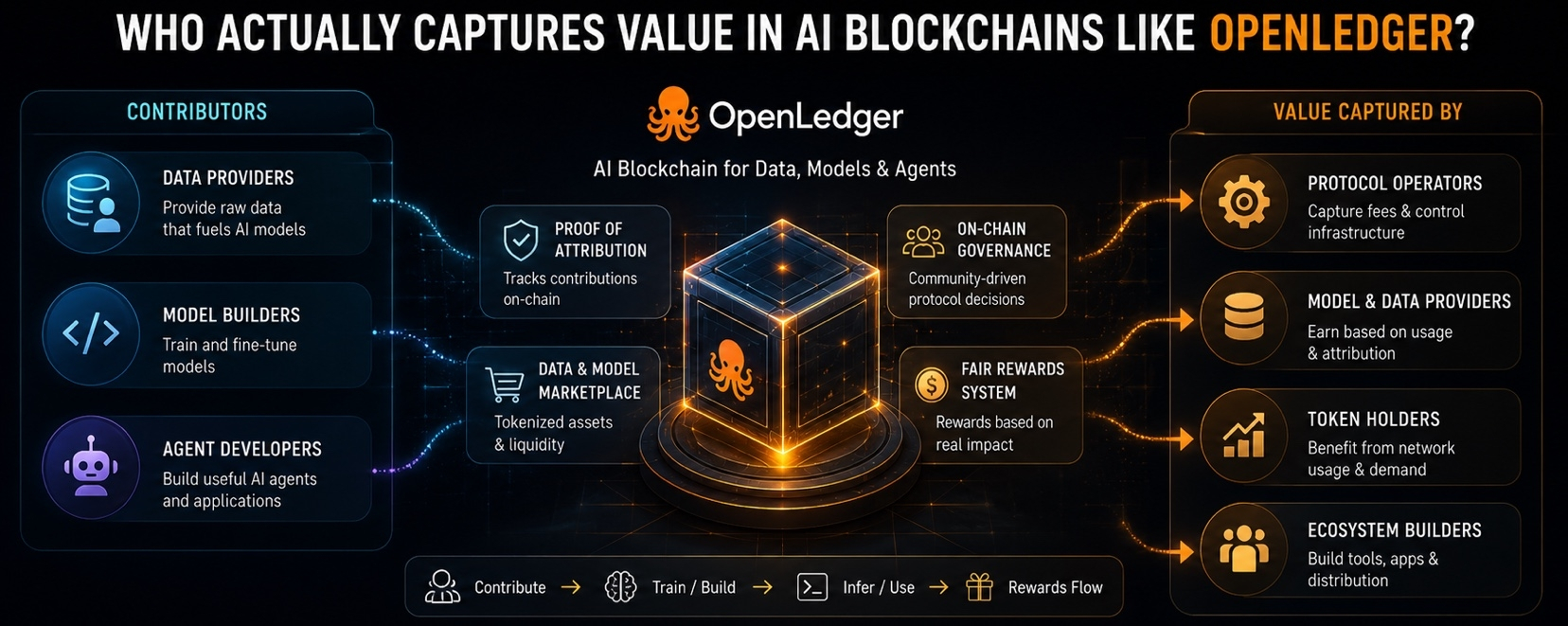
Ce à quoi je pense, c'est que la valeur dans la crypto atterrit rarement là où le livre blanc dit qu'elle le fera. Elle finit généralement quelque part de plus ennuyeux, plus concentré et moins équitable. Les personnes qui sont payées en premier sont généralement celles qui contrôlent l'accès, pas celles qui ont aidé à créer la matière première. Les opérateurs de protocole, les détenteurs de tokens, les bâtisseurs avec la distribution la plus forte, les personnes qui comprennent où se trouvent les goulets d'étranglement et comment s'y asseoir. C'est là que l'argent finit généralement. Pas parce que le système est maléfique d'une manière dramatique, mais parce que les systèmes dérivent vers ceux qui sont les plus proches des points de blocage.
OpenLedger essaie de changer cela avec l'attribution. Cette partie m'intéresse. L'idée que les contributeurs de données peuvent être tracés, que l'utilisation des modèles peut être liée aux entrées, que les récompenses peuvent couler en fonction de la contribution réelle plutôt que sur des promesses vagues — c'est le genre de chose que la crypto dit vouloir faire, mais qu'elle réussit rarement à accomplir d'une manière qui survive au contact de la réalité. L'attribution semble propre jusqu'à ce que vous essayiez de la tarifer. Ensuite, cela devient flou très rapidement. Quelle importance a eu un ensemble de données ? Combien un contributeur devrait-il recevoir ? Qu'est-ce qui compte comme un impact significatif ? Qui décide ? Ce ne sont pas de petites questions. Ce sont le jeu entier.
Et c'est là que je commence à être un peu sceptique, car j'ai vu trop de projets prétendre que la mesure résout l'équité. Ce n'est pas le cas. La mesure donne juste une forme à l'équité. La partie difficile reste le jugement qui se cache derrière. Si OpenLedger peut vraiment faire fonctionner l'attribution d'une manière qui semble honnête, utile et difficile à manipuler, alors ce serait quelque chose. Mais je ne fais pas entièrement confiance à un système qui prétend transformer la contribution en formule parfaite. Les systèmes humains sont trop chaotiques pour cela. Les incitations se tordent. Les gens s'adaptent. Les intermédiaires apparaissent. Ceux qui comprennent le mieux les règles sont généralement les premiers à les contourner.
Pourtant, quelque chose à propos de cela semble suffisamment différent pour que je ne veuille pas le balayer. Pas parce que c'est garanti de fonctionner, mais parce que cela semble viser un véritable point de pression. Tout le monde continue de parler de propriété de l'IA, de provenance de l'IA, de monétisation de l'IA, comme si ces choses étaient évidentes en théorie et n'étaient qu'une question d'exécution en pratique. Ce ne sont pas. La question entière est qui est payé lorsque l'intelligence devient une couche de plateforme. Cette question reste ouverte. Et dans la crypto, les questions ouvertes sont là où résident les véritables expériences, même si la plupart d'entre elles finissent par échouer de la même manière.
Je pense que la réponse à 'qui capture la valeur' est probablement décevante, ce qui est généralement le cas dans ces situations. Si OpenLedger fonctionne, la première capture réelle ira probablement aux personnes qui rendent le réseau difficile à обход, aux personnes qui peuvent réellement fournir des modèles utiles et des données utiles, et aux personnes qui sont suffisamment proches du flux de frais pour que l'utilisation se traduise par quelque chose de tangible. Les détenteurs de tokens pourraient aussi capturer de la valeur, mais seulement si le token n'est pas juste un actif décoratif attaché à une histoire. Il doit avoir de l'importance. Il doit être nécessaire. Il doit être gênant à ignorer.
C'est la partie à laquelle je reviens sans cesse. La crypto adore parler de propriété, mais la propriété sans demande n'est qu'un sentiment. Un token peut être bien conçu et échouer à capturer quoi que ce soit si les utilisateurs peuvent le contourner. Un projet peut avoir un système de récompense astucieux et perdre de la valeur si les personnes qui font le vrai travail sont plus faciles à remplacer que celles qui contrôlent les rails. Et un protocole peut sembler magnifiquement aligné sur une présentation, tandis que le marché décide tranquillement que la partie utile vit ailleurs.
J'ai déjà vu cela avec d'autres cycles. L'excitation initiale donne toujours l'impression qu'un nouvel ordre économique est en train de naître. Puis le temps passe et les mêmes vieilles questions reviennent. Qui a le pouvoir. Qui a du levier. Qui est payé. Qui peut partir. Qui ne peut pas. La crypto ne s'échappe jamais vraiment de ces questions. Elle change juste la formulation.
Donc, avec OpenLedger, je ne pense pas à cela comme à une grande réinvention. Je pense à cela comme une tentative sérieuse de faire en sorte que les contributions de données et de modèles se comportent davantage comme de véritables intrants économiques. C'est plus difficile que cela en a l'air. Peut-être plus difficile que cela ne devrait l'être. Mais c'est aussi pourquoi cela mérite d'être suivi. Pas parce que je crois à l'engouement. Je ne le fais pas. Pas parce que je pense que c'est garanti de fonctionner. Je ne pense pas non plus cela. Juste parce qu'une fois de temps en temps, un projet apparaît qui touche à un problème réel au lieu de simplement habiller un problème familier.
Et quand cela arrive, j'ai appris à ne pas précipiter la conclusion.
