

Je reviens souvent à la même pensée inconfortable ces derniers temps. Peut-être que l'économie de l'IA n'a jamais vraiment été une question de modèles. Peut-être que ça a toujours été une histoire de travail invisible. Chaque prompt, chaque pattern de trading, chaque ensemble de données, chaque interaction en ligne alimente silencieusement l'intelligence machine quelque part en arrière-plan. Nous contribuons constamment à des systèmes que nous ne possédons pas. Et pendant longtemps, l'industrie a traité cela comme normal. Les données entraient, les entreprises prenaient de l'ampleur, et l'attribution disparaissait dans une infrastructure de boîte noire que personne ne pouvait inspecter.
Puis j'ai commencé à tester @OpenLedger more sérieusement, et honnêtement, tout le cadre autour de la propriété de l'IA a commencé à sembler différent.
Au début, je pensais que le protocole se positionnait simplement à l'intérieur du cycle narratif actuel de l'IA comme tout le monde. Les marchés crypto font cela en permanence. Un mois, tout devient modulaire. Le mois suivant, tout devient agentique. Mais l'architecture de #OpenLedger semblait particulièrement axée sur quelque chose de plus profond que l'attention du marché. Le livre blanc revient sans cesse à une idée centrale : l'intelligence doit rester économiquement connectée aux personnes et aux systèmes qui y contribuent. Pas symboliquement. Programmatique.
Cette distinction compte plus que je ne l'avais prévu.
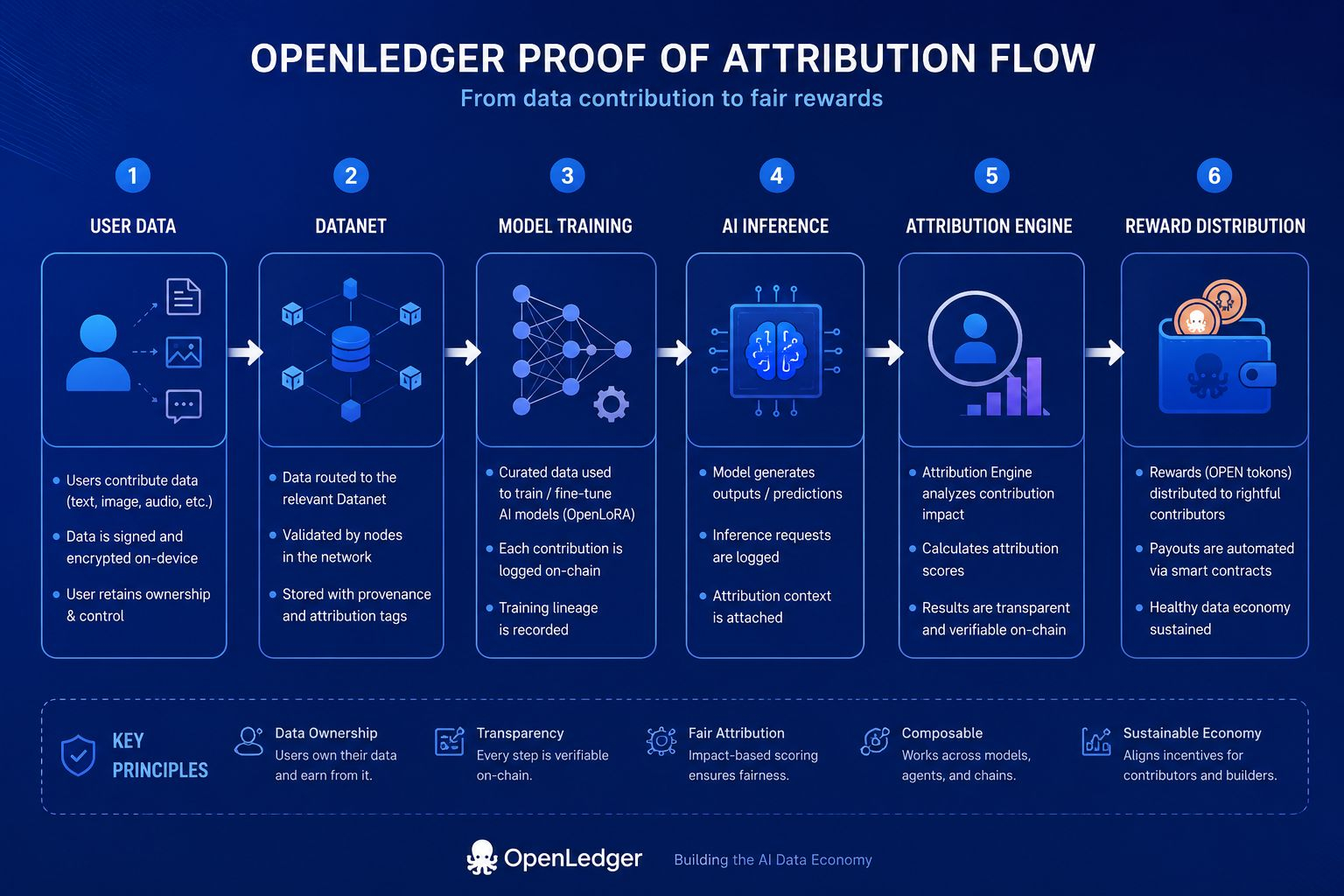
Le cadre de preuve d'attribution du protocole essaie de résoudre un problème que la plupart des systèmes d'IA ignorent intentionnellement. Les modèles traditionnels absorbent des informations sans préserver la lignée de contribution. Une fois que les ensembles de données entrent dans des pipelines centralisés, la propriété se dissout effectivement. OpenLedger tente d'inverser cette dynamique grâce à une infrastructure liée à l'attribution où les ensembles de données, les entrées d'ajustement fin, l'activité d'inférence, les agents d'IA et les sorties de modèles restent économiquement traçables à travers le réseau. En langage simple, le système pose une question qui semble étonnamment radicale maintenant : qui a réellement aidé à produire cette intelligence ?
Et c'est là que les choses deviennent techniquement fascinantes.
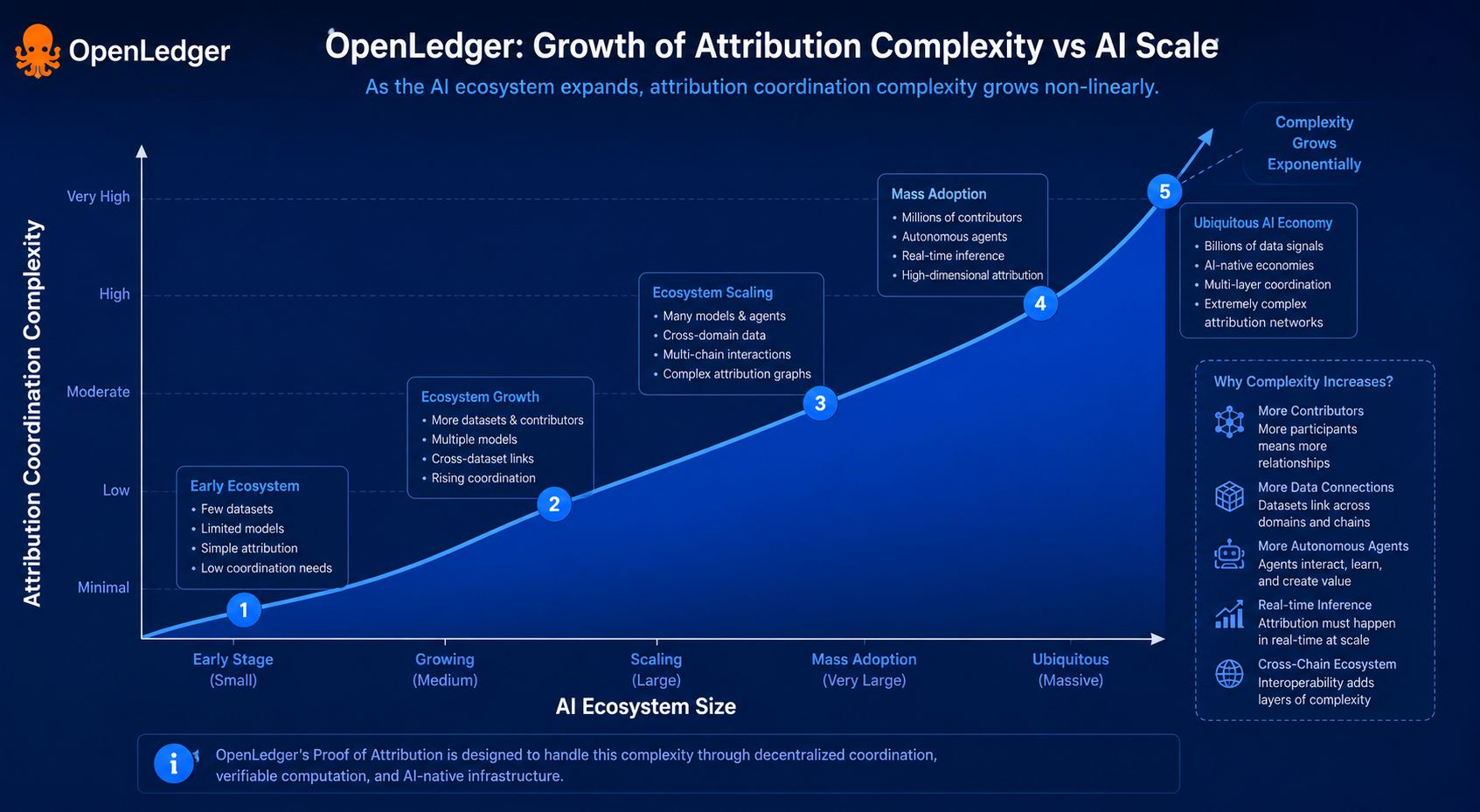
Plus j'explorais les Datanets d'OpenLedger, moins ils ressemblaient à une infrastructure blockchain normale et plus ils commençaient à ressembler à des économies d'intelligence décentralisées. Chaque Datanet peut se spécialiser autour de catégories uniques de données et de coordination de l'IA tout en alimentant continuellement des flux de valeur liés à l'attribution à travers l'écosystème. OpenLedger a récemment dépassé 3 millions de nœuds actifs selon les métriques de l'écosystème, tandis que la coordination d'inférence et les déploiements OpenLoRA continuent de s'étendre à travers plusieurs environnements d'exécution. Ces chiffres ont attiré mon attention car les systèmes d'attribution n'ont d'importance que s'ils survivent à l'échelle opérationnelle. De belles idées s'effondrent rapidement sous la pression du débit réel.
Pour être honnête, la scalabilité était la première chose en laquelle je n'avais pas confiance.
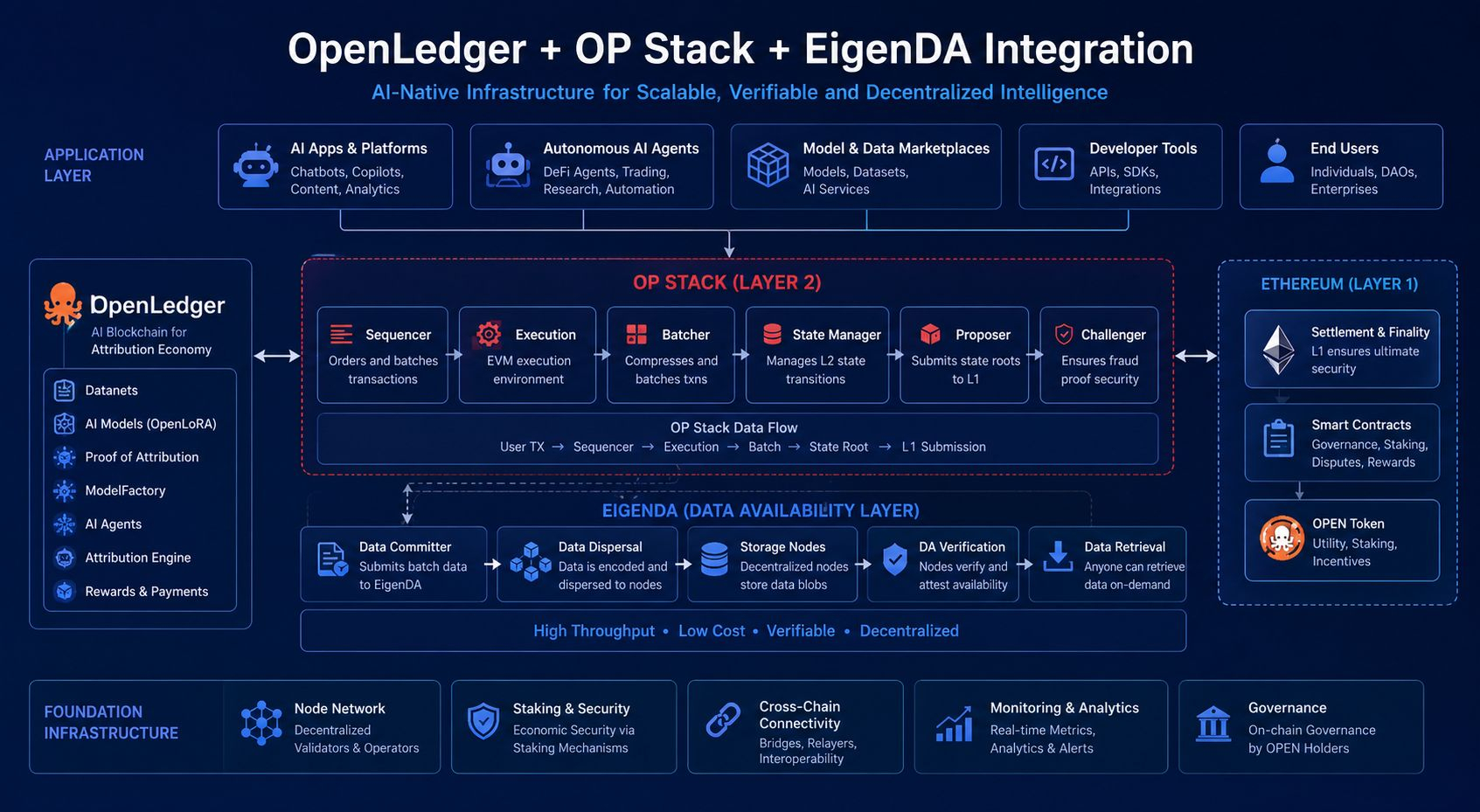
Parce que l'attribution semble élégante jusqu'à ce que chaque interaction d'IA nécessite soudainement des couches de vérification, du routage de récompenses et de la comptabilité des contributions. La complexité s'accumule rapidement. Une seule sortie générée par l'IA pourrait impliquer des modèles ajustés finement, des fournisseurs d'inférence, des systèmes de données en temps réel, une coordination de validateurs et des agents d'exécution autonomes simultanément. L'architecture d'OpenLedger semble intentionnellement modulaire pour gérer cette pression. Le protocole combine l'infrastructure OP Stack, la disponibilité des données soutenue par EigenDA et des systèmes d'interopérabilité inter-chaînes pour réduire les goulets d'étranglement entre les charges de travail de l'IA et les couches de règlement blockchain. En lisant plus profondément dans le système, j'ai cessé de le considérer comme une autre couche 2 et j'ai commencé à le voir davantage comme une infrastructure opérationnelle pour les économies machines.
Et peut-être que c'est la véritable histoire ici.
La plupart des systèmes crypto d'aujourd'hui tournent encore autour du déplacement de la liquidité de manière plus efficace. Mais l'IA change la nature même de la production économique. Une fois que des agents autonomes commencent à prendre des décisions, à exécuter des stratégies, à analyser des marchés et à coordonner des ressources de manière indépendante, l'intelligence devient une infrastructure productive plutôt qu'un logiciel passif. OpenLedger semble conçu autour de cette hypothèse. Le $OPEN token fonctionne de moins en moins comme un actif spéculatif et davantage comme un carburant de coordination pour la validation d'attribution, les systèmes d'exécution d'IA, la participation aux Datanets et les interactions économiques machine à machine.
Mais il y a un autre côté à cela auquel je ne peux pas m'empêcher de penser.
Plus l'intelligence devient mesurable, plus la propriété elle-même devient fragmentée.
Un futur système d'IA pourrait s'appuyer sur des milliers de micro-contributions distribuées simultanément. Données de formation générées par l'humain. Cycles de renforcement synthétiques. Couches d'ajustement fin OpenLoRA spécialisées. Flux financiers en temps réel. Systèmes de mémoire d'agents autonomes. Signaux d'exécution inter-chaînes. Déploiements de ModelFactory. Soudain, l'intelligence ne ressemble plus à un produit unique créé par une seule entité. Elle commence à se comporter comme une chaîne d'approvisionnement constamment changeante de cognition elle-même. L'attribution devient moins une question d'auteur et plus une question de tracé des relations économiques invisibles à travers des systèmes décentralisés.
C'est là que l'idée devient difficile.
Parce que l'équité introduit de la friction. Cela le fait toujours. Les systèmes entièrement optimisés pour l'efficacité se centralisent généralement. Les systèmes optimisés pour une large attribution deviennent généralement plus lourds opérationnellement. OpenLedger semble conscient de cette tension tout au long de la conception du protocole. Le livre blanc souligne sans cesse le routage d'attribution modulaire au lieu d'une application rigide de la propriété, presque comme si le réseau comprenait que les marchés de l'intelligence resteront fluides et adaptatifs plutôt que statiques. Peut-être que je me trompe, mais cette flexibilité pourrait devenir nécessaire une fois que les agents d'IA commenceront à interagir de manière autonome à travers plusieurs chaînes et environnements d'exécution simultanément.
Je continue à réfléchir aux implications psychologiques sous-jacentes à tout cela.
Internet a appris aux gens à croire que les données étaient jetables. Quelque chose échangé négligemment pour la commodité. Mais les économies d'attribution pourraient complètement modifier cette relation au fil du temps. Une fois que les contributeurs comprennent que leurs données, leurs schémas comportementaux ou leur intelligence spécialisée peuvent générer une valeur économique persistante, la participation en ligne elle-même pourrait changer. L'architecture d'OpenLedger laisse entrevoir cette possibilité à travers des pipelines de données vérifiables et des systèmes de compensation liés à l'attribution. Les données cessent de se comporter comme des déchets passifs et commencent à se comporter comme un capital productif.
Et honnêtement, cette idée semble à la fois excitante et légèrement troublante.
Parce que transformer l'intelligence en un actif économique risque également de financiariser encore plus le comportement humain. Chaque interaction pourrait finalement devenir mesurable, attribuable et monétisable au sein des économies machines. Il y a une tension philosophique ici que les discussions crypto ignorent souvent. Les systèmes d'attribution peuvent habiliter les contributeurs tout en élargissant simultanément des structures d'incitation de surveillance autour de l'activité numérique. OpenLedger ne résout pas entièrement cette contradiction. Je ne suis pas sûr qu'un protocole puisse le faire. Mais au moins, le projet semble prêt à reconnaître la complexité au lieu de prétendre que la décentralisation crée automatiquement l'équité.
Plus je m'enfonçais dans l'écosystème, plus l'infrastructure commençait à ressembler à une toute nouvelle couche de coordination pour les marchés natifs d'IA. Des agents autonomes extrayant de l'intelligence des Datanets. Des systèmes d'exécution inter-chaînes interagissant avec des modèles conscients de l'attribution. Des déploiements OpenLoRA spécialisés autour du comportement du marché en temps réel. ModelFactory permettant une gestion du cycle de vie de l'IA continuellement adaptative. Cela ressemble moins à l'émergence d'une autre application crypto qu'à l'observation de la formation d'une architecture économique précoce autour de l'intelligence machine elle-même.
Et peut-être que c'est pourquoi cette expérience est restée dans ma tête plus longtemps que prévu.
Parce qu'OpenLedger force discrètement une conversation plus large sous la narration de l'IA. Pas simplement à quel point l'intelligence artificielle devient puissante, mais si l'intelligence elle-même peut rester économiquement responsable une fois que des systèmes autonomes se développent à l'échelle mondiale. Cette question dépasse largement les marchés crypto. Elle touche à la propriété, au travail, à la coordination, à la gouvernance et même à l'identité humaine dans des économies numériques de plus en plus façonnées par le raisonnement machine.
Le plus étrange, c'est à quel point tout semble encore très précoce.
En ce moment, la plupart des gens interagissant avec des systèmes d'IA ne pensent guère à l'infrastructure d'attribution sous-jacente. Ils se soucient des résultats. De la vitesse. De la commodité. Mais l'infrastructure compte toujours finalement. D'abord silencieusement. Puis tout à coup, d'un coup. L'informatique en nuage a fonctionné de cette manière. Les centres de données ont fonctionné de cette manière. Les couches de règlement blockchain ont fonctionné de cette manière. Les économies d'attribution pourraient suivre le même chemin jusqu'à ce qu'un jour, les gens réalisent que les systèmes produisant de l'intelligence sont devenus tout aussi économiquement importants que l'intelligence elle-même.
Et peut-être que dans des années, lorsque des agents IA autonomes coordonneront des flux de valeur à travers des réseaux décentralisés sans supervision humaine directe, la véritable question historique ne sera pas de savoir si nous avons réussi à construire une IA puissante.
Il se peut que ce soit si nous avons pensé à intégrer une mémoire économique dans la couche d'intelligence avant que les économies machines ne deviennent trop grandes pour être tracées de manière significative.