Je pense à quelque chose qui me dérange plus que ça ne le devrait......🤔
Un médecin passe vingt ans à comprendre comment le corps humain échoue. Un avocat consacre une décennie à apprendre comment les arguments s'effondrent au tribunal. Un enseignant passe d'innombrables heures à déterminer pourquoi certaines explications fonctionnent et d'autres non..... Puis un jour, ils se retrouvent devant un outil d'IA, lui disent "cette réponse est fausse" ou "ce raisonnement est incomplet" et le modèle apprend tranquillement de cette correction..... Il devient plus affûté. Il devient plus précis. Il devient plus précieux pour l'entreprise qui l'a construit.
Et ces personnes ? Elles s'en vont avec rien d'autre qu'une IA légèrement améliorée pour laquelle elles paieront un abonnement le mois prochain.
Ce n'est pas une conspiration. C'est juste comment le système a été construit.... Et pendant longtemps, personne ne l'a remis en question sérieusement.
Quand j'ai d'abord lu l'approche d'OpenLedger concernant l'apprentissage par renforcement avec feedback humain, je dois être honnête, mon premier instinct était le scepticisme....👀 j'ai vu trop de projets envelopper un concept familier dans un nouveau langage et l'appeler innovation. Mais plus je me suis attardé sur la structure réelle ici, plus j'ai réalisé qu'une tentative véritablement différente était en cours.
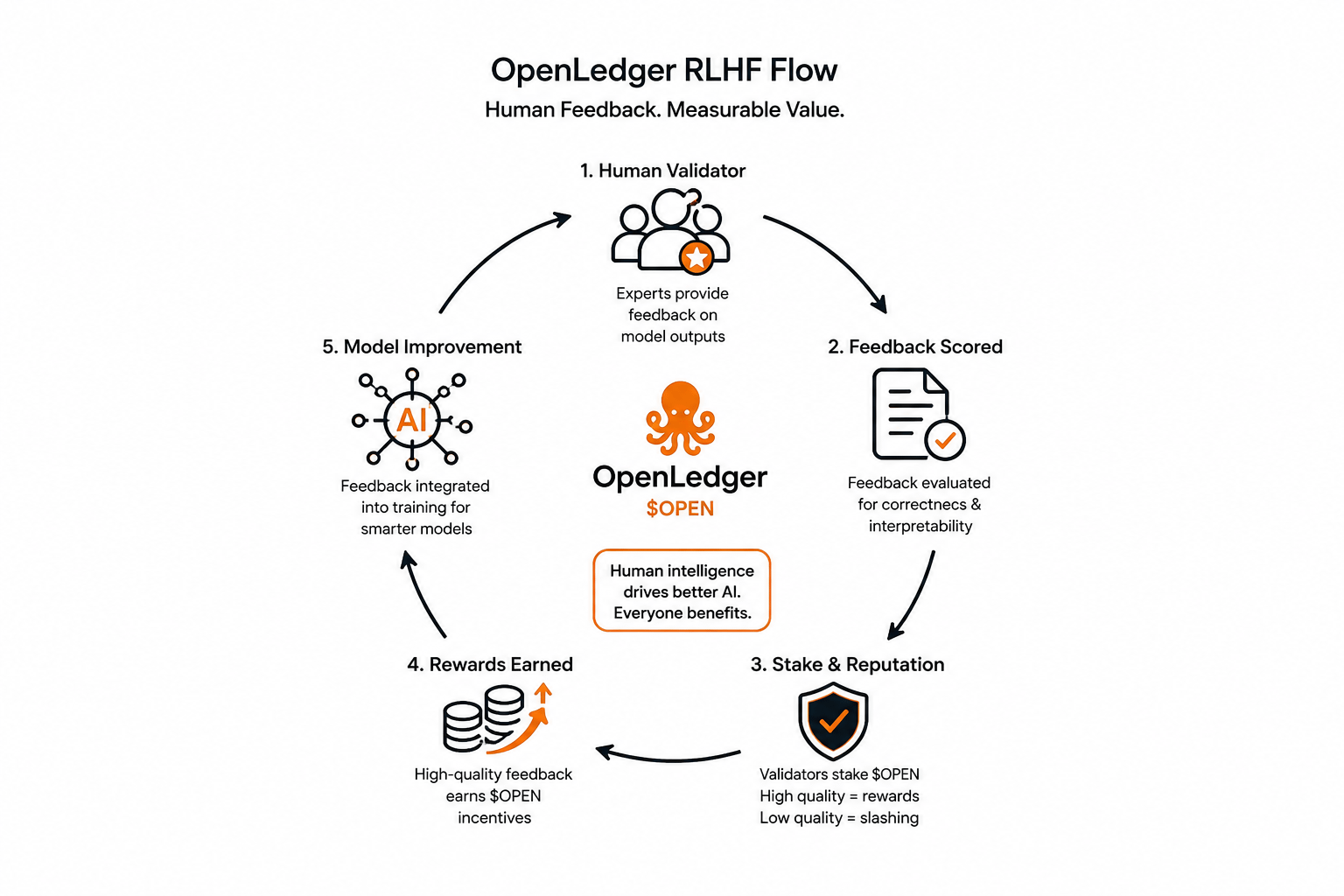
La revendication centrale est simple. Lorsque qu'un validateur humain évalue une sortie de modèle, ce retour n'est pas juste des données qui entrent dans une boîte noire. C'est une contribution mesurable avec une récompense correspondante. La fonction de récompense d'OpenLedger est conçue pour pondérer les retours humains en fonction de la justesse et de l'interprétabilité, et la compensation s'écoule en conséquence à travers $OPEN. Un retour de haute qualité gagne des incitations de mise. Un retour pauvre ou manipulateur est pénalisé par une sanction de mise.
Cette dernière partie mérite d'être méditée. La sanction de mise en jeu pour un mauvais retour est un choix de conception qui en dit long sur ce que ce système essaie réellement de résoudre. La plupart des plateformes qui collectent des retours humains n'ont aucune véritable conséquence pour des réponses peu sérieuses ou malhonnêtes. Ici, votre crédibilité en tant que validateur a de la peau financière dans le jeu. Cela change la structure d'incitation d'une manière difficile à simuler avec un langage marketing.
Maintenant, est-ce un problème résolu ? Pas du tout. La question plus difficile est de savoir si la mesure de qualité elle-même est fiable. Comment le système distingue-t-il une correction d'expert authentique d'une réponse fausse mais confiante ? Un médecin senior et un étudiant en médecine pourraient tous deux soumettre des retours avec une conviction égale. Le modèle ne peut pas automatiquement savoir quel jugement a plus de poids à moins que cette hiérarchie ne soit soigneusement intégrée dans la couche de validation. OpenLedger reconnaît ce défi de manière implicite à travers son cadre de scoring des validateurs, mais l'exécution de cette couche déterminera si cela devient une véritable économie de savoir ou juste un autre jeu de points.
Ce que je trouve plus convaincant que la tokenomics, c'est la philosophie sous-jacente. L'idée que l'intelligence humaine appliquée à l'affinage de l'IA mérite attribution et compensation n'est pas radicale. C'est évident. La partie radicale, c'est qu'à peu près personne dans l'industrie de l'IA ne s'est soucié de construire l'infrastructure pour cela. OpenLedger tente au moins de combler cette lacune avec de véritables mécaniques on-chain plutôt que des promesses.
Le modèle RLHF ici se connecte directement à l'écosystème plus large de $OPEN. Vos retours n'existent pas en isolement. Ils alimentent la formation de modèles spécialisés, qui influencent la qualité des inférences, qui à son tour impacte le pipeline de frais et de récompenses. Vous ne laissez pas juste une note. Vous participez à une chaîne de valeur qui a un début, un milieu, et un résultat mesurable.
J'ai encore des questions ouvertes. L'adoption parmi les experts du domaine, pas seulement les utilisateurs natifs de crypto, sera le vrai test. Une économie de feedback basée sur la blockchain ne devient significative que lorsque les personnes avec une expertise réelle jugent qu'il vaut leur temps de participer. C'est un problème plus difficile que de construire le protocole.
Mais voici ce à quoi je reviens sans cesse. La question que pose OpenLedger, à savoir si les personnes qui rendent l'IA plus intelligente méritent de partager ce qu'elles construisent....est plus sérieuse que la plupart des narrations crypto que j'ai suivies. Les projets répondent généralement à des questions sur lesquelles le marché s'accorde déjà. Celui-ci soulève une question que l'industrie a discrètement évitée.
Cela seul vaut la peine de regarder de près......👁️
DYOR... Ce n'est pas un conseil financier.
$CHIP #OpenLedger #decentralization #Altcoins! #CryptoVibes