Pense à ce que tu as mis en ligne ces cinq dernières années. Posts sur les forums, tutoriels, code sur GitHub, critiques de produits, commentaires. Une vraie réflexion. Un vrai moment.
Ce contenu a été extrait, empaqueté dans des ensembles de données d'entraînement, et utilisé pour construire des produits d'IA générant des milliards de revenus annuels. Personne n'a demandé. Personne n'a payé.
Ce n'est pas un grief de niche. C'est le modèle commercial fondamental de l'industrie de l'IA. Et en 2026, entre les poursuites judiciaires croissantes et la pression réglementaire, ce modèle commence à fléchir.
@OpenLedger was construit pour ce qui vient ensuite.
Alors, qu'est-ce qu'OpenLedger, en fait ?
L'idée principale est simple : si vos données influencent la sortie d'un modèle d'IA, vous devriez être en mesure de le prouver et d'être compensé pour cela.
Le mécanisme qui rend cela possible à grande échelle s'appelle un Datanet. Pensez-y comme un ensemble de données appartenant à la communauté avec une piste d'audit complète. Chaque téléchargement est horodaté sur la chaîne, chaque contributeur identifié, et chaque fois qu'un modèle s'entraîne ou interroge ces données, le système enregistre qui a contribué quoi et combien cela a compté.
La compensation circule automatiquement en tokens $OPEN en fonction de ces scores d'influence. Pas de comptabilité manuelle. Pas de confiance requise.
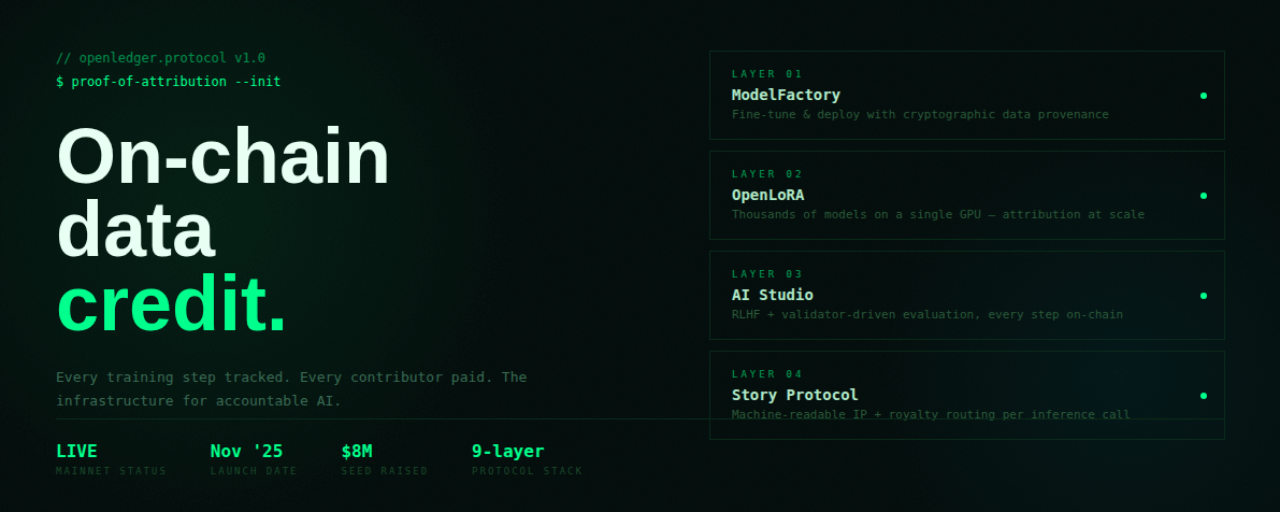
L'infrastructure en dessous
Trois outils alimentent le système :
ModelFactory est un tableau de bord sans code pour peaufiner et déployer des modèles d'IA sur le réseau OpenLedger. Chaque session d'entraînement est cryptographiquement liée à ses sources de données.
OpenLoRA est une couche de service de modèle qui héberge des milliers de modèles ajustés sur un seul GPU. C'est ce qui rend l'IA consciente de l'attribution commercialement viable, pas seulement techniquement intéressante.
AI Studio est l'environnement pour le fine-tuning supervisé et l'apprentissage par renforcement avec retour humain. Chaque étape est enregistrée sur la chaîne, l'influence de chaque contributeur est suivie.
Ensemble, ils transforment un ensemble de données d'un téléchargement unique en un flux de revenus récurrents. Vos données gagnent chaque fois qu'un modèle entraîné dessus est interrogé.
La couche légale : Story Protocol
En janvier 2026, OpenLedger a établi un partenariat avec Story Protocol pour ajouter la propriété intellectuelle lisible par machine au système d'attribution.
Ce que cela permet en pratique : un modèle d'IA peut s'entraîner sur des données attribuées, tarifer son inférence via x402, collecter des paiements en $OPEN, et acheminer les redevances aux contributeurs de données, le tout dans un seul cycle de demande-réponse HTTP.
Où en sont les choses
OpenLedger a été fondé en 2024 par Ashtyn Bell et Pryce Adade-Yebesi. L'entreprise a levé un tour de financement de 8 millions de dollars dirigé par Polychain Capital et Borderless Capital. Le mainnet a été lancé en novembre 2025.
La feuille de route 2026 couvre une plateforme à neuf couches allant de l'attribution de données à travers les économies d'agents. Un produit DeFAI appelé OpenFin a été annoncé en mars 2026 et est toujours à venir.
$OPEN se trade bien en dessous de son plus haut historique. Que ce soit une opportunité structurelle ou un rabais d'adoption précoce, c'est à vous d'évaluer.
Faites vos propres recherches. #OpenLedger
Ce n'est pas un conseil financier. Les actifs crypto sont volatils.