OpenLedger est l'un de ces projets qui te fait faire une pause pendant une seconde, pas parce que le pitch est complètement nouveau, mais parce que le problème sous-jacent est suffisamment réel pour que tu ne puisses pas le balayer d'un revers de main.
Et honnêtement, c'est rare dans le crypto maintenant.
Après quelques cycles, tu commences à développer une sorte d'allergie aux grandes narrations. DeFi allait reconstruire la finance. GameFi allait onboarder le prochain milliard d'utilisateurs. Les terrains du Metaverse allaient d'une manière ou d'une autre remplacer l'immobilier. Les chaînes modulaires allaient régler les problèmes d'échelle. La crypto AI est maintenant la dernière étape où chaque projet découvre soudainement qu'il a toujours été question d'intelligence artificielle.
Alors quand quelque chose se présente comme une « blockchain IA », le premier instinct n'est pas l'excitation. C'est la suspicion.
Vous lisez la phrase une fois et votre cerveau se prépare immédiatement à la pile habituelle de mots à la mode : intelligence décentralisée, agents ouverts, souveraineté des données, infrastructure évolutive, propriété communautaire, alignement des incitations. Tous les ingrédients familiers. Tous les mots qui semblent importants jusqu'à ce que vous demandiez ce qui se passe réellement en dessous.
Mais OpenLedger pointe au moins vers un problème qui compte.
L'IA a un problème de contribution.
Pas un problème de marque. Pas un problème de jeton. Un problème de contribution.
Chaque système IA utile est construit sur les données, les connaissances, les exemples, les retours, les documents, les flux de travail, les étiquettes, les corrections et l'expérience de domaine de quelqu'un d'autre. C'est la partie que les gens aiment sauter. Le modèle est présenté comme le produit, mais le modèle est en réalité le résultat final d'une longue chaîne d'entrées invisibles.
Quelqu'un a créé les données. Quelqu'un les a nettoyées. Quelqu'un les a organisées. Quelqu'un savait assez sur le sujet pour rendre l'information utile. Puis le tout est absorbé dans un modèle, et une fois à l'intérieur, la contribution originale devient presque impossible à voir.
C'est le marché étrange de l'IA moderne. Tout le monde contribue à la couche d'intelligence, mais seules quelques plateformes capturent la plupart de la valeur.
OpenLedger essaie de construire autour de cette lacune.
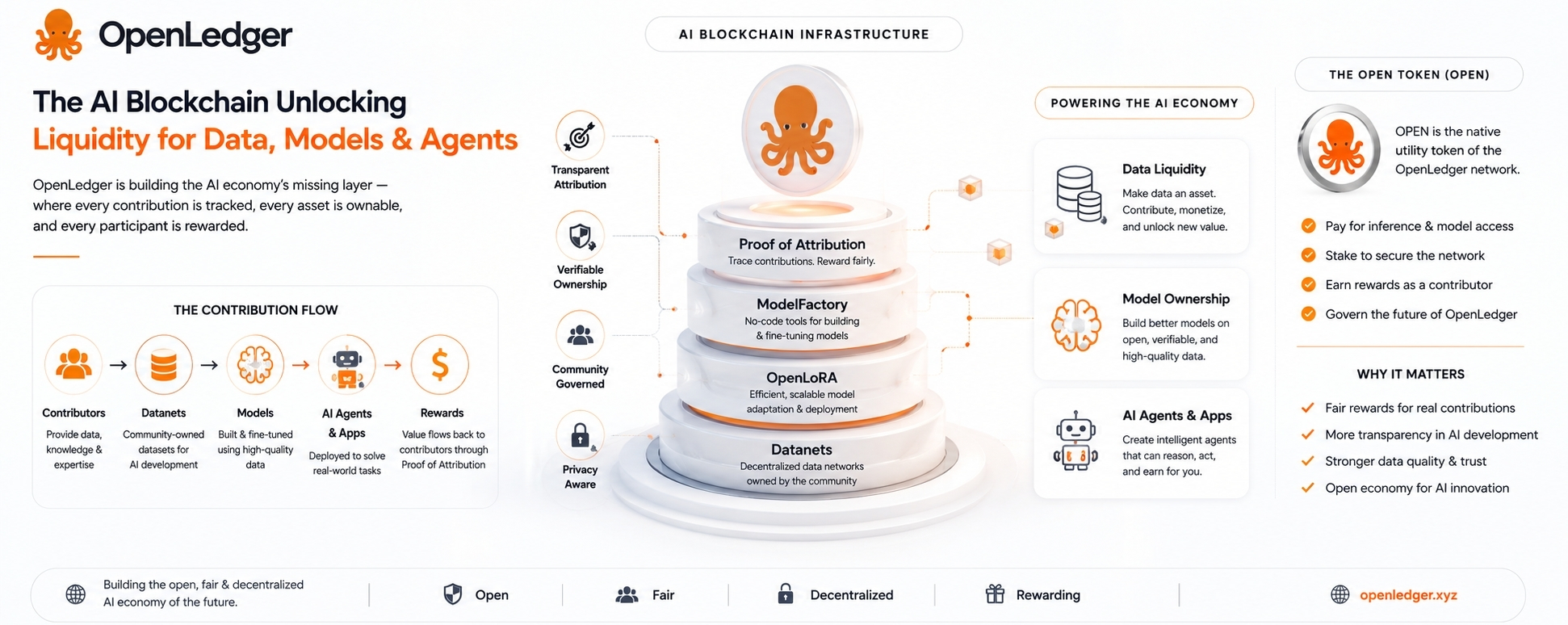
L'idée de base est que les données, les modèles et les agents IA ne devraient pas simplement flotter comme des objets numériques vagues. Ils devraient être traçables. Ils devraient avoir une provenance. Ils devraient être connectés aux personnes ou communautés qui les ont créés. Et s'ils génèrent de la valeur plus tard, il devrait y avoir un mécanisme pour récompenser les contributeurs qui les soutiennent.
Cela semble évident quand vous le dites lentement. Cela semble aussi extrêmement difficile quand vous pensez à la façon dont l'IA fonctionne réellement.
Parce que l'attribution de l'IA est compliquée.
Un modèle ne répond pas à une question en tirant simplement un fichier d'une étagère. Il ne dit pas : « Cette réponse vient à 12 % du jeu de données d'Ali, 8 % de ce rapport d'audit, et 3 % de ce post de forum. » Pas naturellement, en tout cas. Les sorties sont façonnées par les données d'entraînement, l'affinage, les poids, les prompts, les embeddings, les systèmes de récupération, les adaptateurs et tout ce qui a été ajouté à la pile.
Donc, lorsque OpenLedger parle de Preuve d'Attribution, c'est la partie qu'il vaut la peine de surveiller, mais aussi celle qui mérite le plus de scepticisme.
L'idée est d'identifier quelles données ont influencé une sortie IA et de récompenser les contributeurs en fonction de cette influence. Si cela fonctionne, c'est significatif. Si cela devient une gesticulation vague, c'est juste un autre système de points tokenisés avec un meilleur langage.
C'est la ligne que doit suivre OpenLedger.
Cependant, le cadre n'est pas vide. L'IA a besoin d'une meilleure couche de comptabilité. En ce moment, Internet est plein de valeur que les systèmes IA consomment, compressent et monétisent. La sortie semble propre, mais l'historique des entrées est flou. Et à mesure que les agents IA deviennent plus courants, ce flou devient un problème plus grand.
Si un agent IA aide à auditer un contrat intelligent, d'où vient sa connaissance en matière de sécurité ?
Si un assistant de trading IA reconnaît un modèle, quelles données l'ont aidé à l'enseigner ?
Si un outil IA légal examine un contrat, quels documents ont façonné son raisonnement ?
Si un assistant médical donne une suggestion, quelle connaissance se cachait derrière cette réponse ?
Ce ne sont plus des questions philosophiques. Elles deviennent des questions économiques au moment où les gens commencent à payer pour la sortie.
C'est pourquoi les Datanets d'OpenLedger sont intéressants.
Un Datanet est essentiellement un réseau de données détenu par la communauté, construit autour d'un sujet ou d'un cas d'utilisation spécifique. Au lieu que les données soient silencieusement collectées par une entreprise centralisée, les contributeurs peuvent ajouter des informations utiles dans une couche de données partagée. Ces données peuvent ensuite être utilisées pour former ou affiner des modèles.
En théorie, vous pourriez avoir un Datanet pour les exploits de contrats intelligents, un autre pour les documents juridiques, un autre pour les flux de travail de santé, un autre pour la cartographie des données, un autre pour l'analyse des risques DeFi, et ainsi de suite.
L'idée n'est pas seulement de collecter des données. Tout le monde collecte des données. L'idée est de garder une trace de qui a contribué quoi, puis de connecter cette contribution à l'utilisation future du modèle.
C'est la partie qui semble plus sérieuse que le pitch habituel « IA plus jeton ».
Parce que si l'IA spécialisée est vraiment vers où le marché va, alors les données spécialisées deviennent extrêmement précieuses. Les modèles généraux sont déjà suffisamment bons pour des tâches larges. Le prochain combat n'est pas de savoir qui peut faire dire des choses agréables à un chatbot. C'est de savoir qui peut construire des modèles qui comprennent profondément des domaines spécifiques.
Une IA générale peut expliquer le risque des contrats intelligents. Un modèle spécialisé formé sur des données d'exploitation réelles pourrait vraiment aider à le détecter.
Une IA générale peut parler de finance. Un modèle spécialisé formé sur des comportements de marché structurés et des données de risque peut devenir plus utile.
Une IA générale peut résumer du contenu de santé. Un modèle clinique spécialisé, en supposant que la confidentialité et la conformité soient correctement gérées, pourrait faire quelque chose de beaucoup plus précieux.
Donc, OpenLedger vise une vraie tendance : le passage de l'IA générale à l'intelligence spécifique au domaine.
Mais encore une fois, l'exécution compte.
La crypto a l'habitude de transformer chaque problème valide en une économie de jetons sur-conçue. Parfois, le jeton est essentiel. Parfois, c'est juste du ruban adhésif sur un marché qui aurait pu fonctionner sans.
OPEN, le jeton natif, est censé s'insérer dans l'économie d'OpenLedger. Il peut être utilisé pour les frais de réseau, l'accès aux modèles, les paiements d'inférence, le staking, la gouvernance et les récompenses des contributeurs. Cela a du sens structurellement. Si le réseau est effectivement utilisé, le jeton a un rôle.
Mais la phrase « si le réseau est effectivement utilisé » fait beaucoup de travail ici.
Un jeton ne crée pas de demande en existant. Un marché ne devient pas précieux parce qu'un tableau de bord dit que les contributeurs peuvent gagner. La partie difficile est de faire en sorte que les gens contribuent des données de haute qualité, que les développeurs construisent des modèles à partir de ces données, que les utilisateurs paient pour ces modèles et que les récompenses circulent d'une manière qui semble juste plutôt qu'arbitraire.
C'est là que de nombreux projets crypto échouent.
Ils peuvent concevoir des incitations pour la première vague. Ils peuvent attirer des contributeurs précoces. Ils peuvent rendre les graphiques vivants. Mais la valeur à long terme ne vient que si le système produit quelque chose que les personnes en dehors de la boucle d'incitation veulent réellement.
L'avenir d'OpenLedger dépend de sa capacité à produire des systèmes IA utiles, pas seulement des ensembles de données bien étiquetés.
ModelFactory fait partie de cette tentative. Il est destiné à rendre l'affinage plus facile, surtout pour les personnes qui ne veulent pas s'occuper d'infrastructures lourdes en apprentissage automatique. C'est une bonne direction parce que la plupart des experts en domaine ne sont pas des ingénieurs ML.
La personne qui comprend les contrats légaux ne sait peut-être pas comment affiner un modèle.
Le trader qui comprend la structure de marché ne sait peut-être pas comment déployer une infrastructure d'inférence.
Le chercheur en sécurité qui comprend les exploits ne veut peut-être pas gérer des adaptateurs et des GPU.
Si OpenLedger peut faciliter la transformation des connaissances en actifs IA utilisables, cela compte.
OpenLoRA est un autre morceau pratique. Les modèles spécialisés sont utiles, mais les faire fonctionner peut devenir coûteux. L'affinage basé sur LoRA est déjà l'un des chemins les plus réalistes pour créer de nombreuses variations de modèles légers. Si OpenLedger peut soutenir le déploiement efficace de nombreux modèles affinés, cela donne à l'écosystème une base plus pratique.
C'est là que le projet commence à sembler moins comme un pur jeu narratif et plus comme une tentative de construire une pile de production IA complète.
Les données arrivent à travers les Datanets.
Les modèles sont créés ou affinés grâce à des outils comme ModelFactory.
OpenLoRA aide au déploiement.
Les agents et applications IA se trouvent au-dessus.
La chaîne enregistre les contributions, l'utilisation et les récompenses.
C'est la carte, au moins.
Que le territoire ressemble à cela est une autre question.
La partie la plus difficile reste l'attribution. Il est facile d'écrire « Preuve d'Attribution » dans un livre blanc. Il est beaucoup plus difficile de faire en sorte que les contributeurs aient confiance que le système mesure avec précision l'influence. Si les récompenses sont trop vagues, les gens perdront de l'intérêt. Si le système peut être manipulé, des données de mauvaise qualité afflueront. Si seuls les grands contributeurs en bénéficient, l'angle communautaire s'affaiblit. Si l'attribution est trop coûteuse ou trop lente, les développeurs peuvent l'éviter.
Il y a aussi le problème de la confidentialité. Certaines des données IA les plus précieuses sont sensibles. Les données de santé, les dossiers financiers, le matériel juridique, les flux de travail d'entreprise — ce ne sont pas des choses que les gens jettent par hasard dans un réseau ouvert. OpenLedger aura besoin de chemins de permissionnement, de confidentialité et de conformité solides s'il veut une adoption sérieuse au-delà des ensembles de données propres à la crypto.
Puis il y a le problème de marché. La crypto IA est saturée. Chaque semaine, il y a une nouvelle plateforme d'agent, un marché de données, un réseau d'inférence, une couche de calcul décentralisée ou un protocole de propriété de modèle. Certains sont réfléchis. Beaucoup sont des enveloppes narratives. Les investisseurs et utilisateurs sont fatigués, même s'ils continuent à poursuivre la prochaine rotation.
Donc, OpenLedger doit prouver que son mécanisme central compte réellement.
Pas en théorie.
Dans l'utilisation.
Quelqu'un peut-il construire un meilleur modèle grâce à OpenLedger ?
Un contributeur peut-il gagner parce que ses données ont réellement amélioré une sortie ?
Un développeur peut-il lancer un agent IA plus vite ou moins cher ?
Un utilisateur peut-il faire confiance à la provenance de ce avec quoi il interagit ?
Le système peut-il attirer des données qui n'apparaîtraient ailleurs ?
Ce sont les questions qui comptent.
Et peut-être que c'est pourquoi OpenLedger vaut la peine d'être surveillé sans se laisser emporter.
Ce n'est pas automatiquement révolutionnaire. Ce n'est pas garanti de devenir la couche de base de la propriété de l'IA. Ce n'est pas à l'abri des problèmes crypto habituels de spéculation, d'activité sur-incitée et d'inflation narrative.
Mais cela tourne autour d'un vrai problème.
L'IA crée une valeur énorme à partir d'entrées invisibles. Le système actuel n'a pas de moyen juste ou transparent de suivre ces entrées. OpenLedger essaie de construire cette couche manquante en utilisant les rails de la blockchain, la logique d'attribution et des incitations en jetons.
Cela peut fonctionner. Cela peut ne pas fonctionner.
Mais le problème est suffisamment réel pour que la tentative mérite plus qu'un simple rejet rapide.
La manière la plus claire de penser à OpenLedger est la suivante : il veut donner à l'IA une mémoire économique.
Pas seulement la mémoire dans le sens du modèle, mais la mémoire de la contribution. Qui a ajouté les données ? Qui a façonné le modèle ? Qui a construit l'agent ? Qui mérite une part lorsque le système devient utile ?
C'est une idée convaincante, surtout dans un monde où l'IA devient plus puissante et plus centralisée en même temps.
Le sceptique en moi veut toujours des preuves. Utilisation réelle. Contributeurs réels. Modèles réels. Demande réelle. Pas seulement des campagnes, des points, des émissions de jetons et des captures d'écran de partenaires de l'écosystème.
Mais le chercheur en moi comprend pourquoi cette catégorie est importante.
Si la prochaine phase de l'IA est construite sur des données spécialisées et des agents autonomes, alors la propriété et l'attribution ne sont pas des caractéristiques annexes. Elles deviennent des infrastructures.
OpenLedger parie là-dessus.
Et après avoir lu suffisamment de livres blancs pour savoir à quelle fréquence ces choses s'effondrent dans le bruit, celui-ci laisse au moins derrière une question qui reste :