

L'Avenir des Applications et Agents IA sur OpenLedger
Sujet
Openledger
Tags
OpenLedger
Aperçu du Post
Des modèles spécialisés aux agents capables de voir, de raisonner et d'agir — ce blog décompose comment OpenLedger définit l'avenir des agents et des applications IA, avec contexte, outils, mémoire et logique intégrés dans la chaîne.
Dans les premières phases de l'apprentissage automatique, la plupart des systèmes étaient construits comme des modèles monolithiques, entraînés une fois puis figés. Au fil du temps, l'industrie a évolué vers le fine-tuning et des variantes spécifiques à des tâches. Ces modèles ont posé les bases de l'adaptation au domaine, mais construire des applications IA utiles aujourd'hui consiste à dynamiser le modèle pour qu'il fasse plus.
Un modèle puissant n'est qu'une partie de l'équation. Pour que les systèmes d'IA fonctionnent de manière significative dans le monde réel, ils doivent comprendre leur domaine problématique, interagir avec des données en direct, récupérer le contexte historique et exécuter une logique déterministe. Tout comme les GPU ont libéré l'échelle pour l'entraînement, le prochain saut concerne le déverrouillage de l'interaction, de l'attribution et de l'alignement économique au niveau de l'application.
C'est l'infrastructure qu'OpenLedger fournit.
OpenLedger est la blockchain d'IA. Elle n'est pas conçue comme une chaîne à usage général, mais comme une couche d'exécution et d'attribution pour les systèmes intelligents. Elle fournit le substrat où les modèles, les données, la mémoire et les agents deviennent des composants interopérables. Ce blog détaille les outils qui étendront les modèles pour permettre une grande variété d'agents et d'applications en ajoutant le contexte, le comportement et la mémoire dont ils ont besoin.
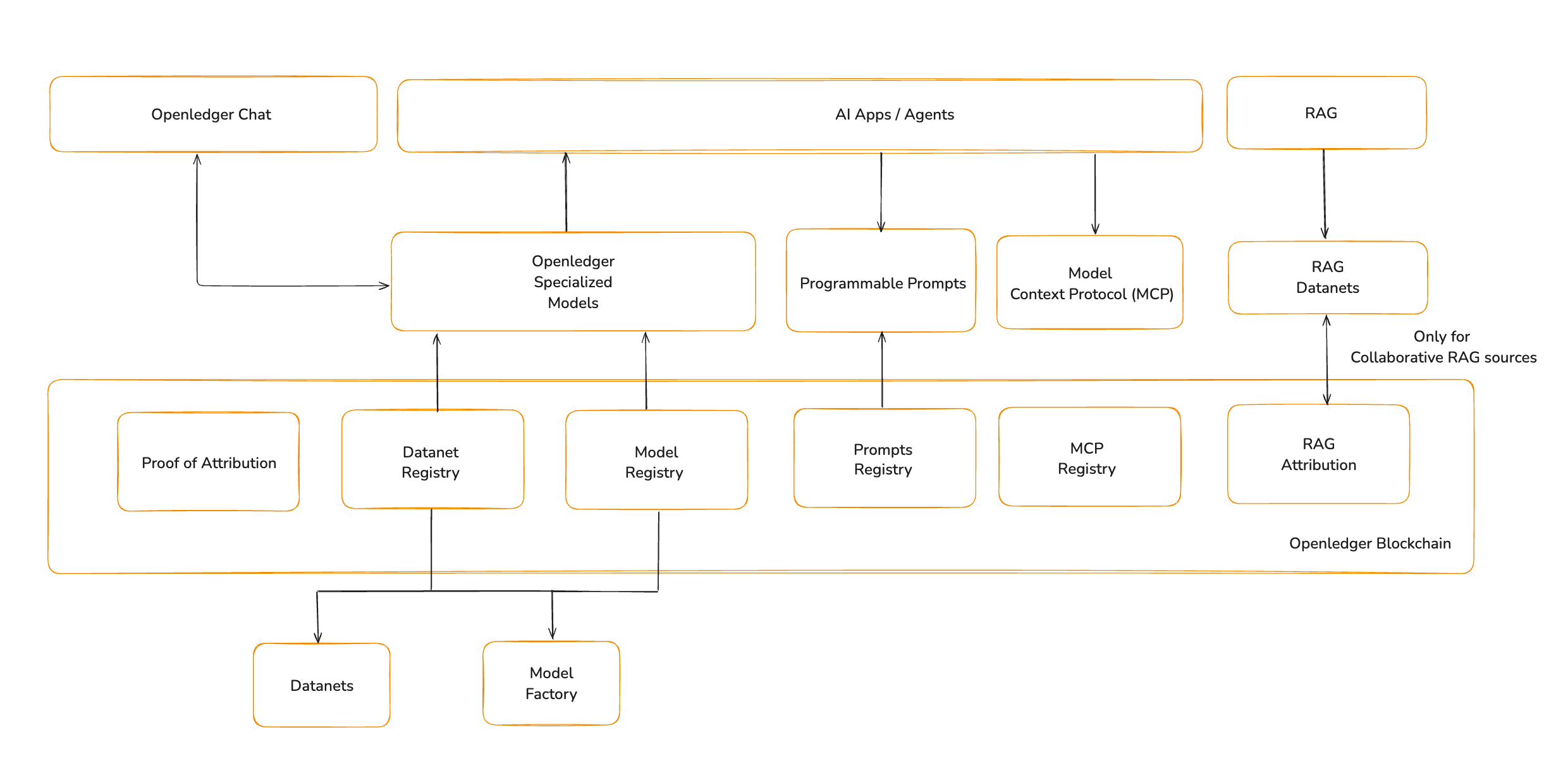
Modèles Spécialisés (Un Bref Récapitulatif)
La base de toute application intelligente est un modèle. Les modèles à usage général offrent de la flexibilité, mais lorsqu'ils sont appliqués à des domaines spécialisés, ils bénéficient grandement de l'affinage et de l'adaptation. OpenLedger améliore ce processus grâce à un pipeline dédié :
-> Datanets qui sont des dépôts de données curés, collaboratifs et attribuables construits par la communauté
-> Usine de Modèles qui simplifie l'affinage en utilisant des flux de travail sans code
-> OpenLoRA qui héberge des variantes d'adaptateurs économiques pouvant être échangées en temps réel, rendant l'inférence légère et composable
Ces composants ont été largement discutés dans des articles précédents. Ils servent de fondation. Et avec les bonnes extensions, ils permettent l'émergence d'agents robustes et intelligents.
Protocole de Contexte de Modèle (MCP)
Pour qu'un modèle puisse ouvrir un fichier, lire une base de données ou invoquer un outil, il doit avoir accès à l'état et au contexte externes. Pour donner aux modèles cette capacité, OpenLedger introduit le Protocole de Contexte de Modèle (MCP).
Le MCP définit la structure pour fournir un contexte à un modèle et recevoir des réponses structurées pouvant être exécutées. Il se compose de trois parties : un client qui fournit des données, un serveur qui traite les appels d'outils, et un routeur qui gère le flux entre eux.
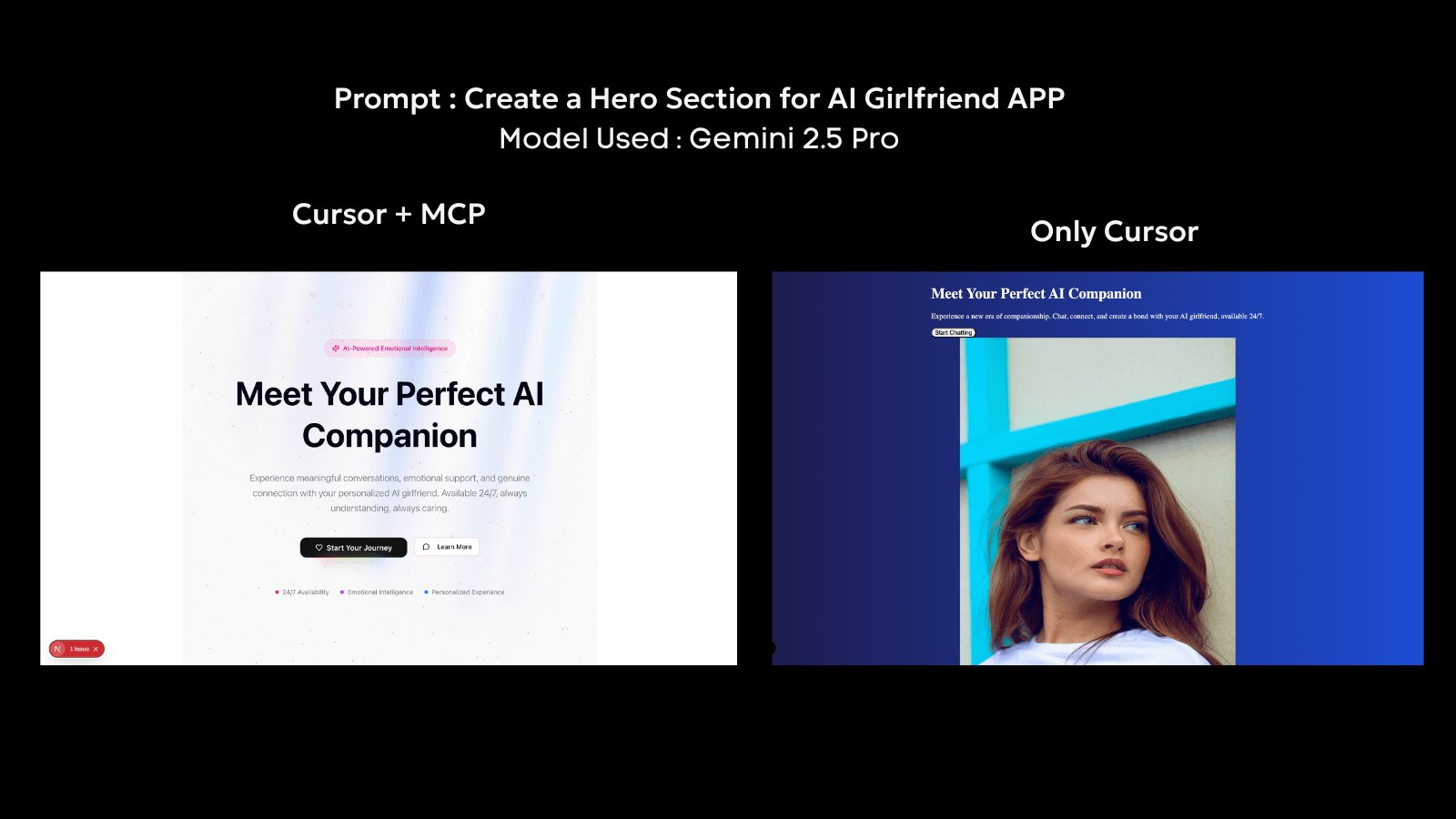
En pratique, le MCP a déjà été adopté dans des systèmes comme Cursor, où un agent peut lire des fichiers locaux, modifier des bases de code et effectuer des tâches basées sur des outils à l'intérieur de l'environnement de développement. Des outils comme 21.dev agissent comme des clients MCP qui peuvent être ajoutés à Cursor pour créer des interfaces dynamiques et en temps réel. En utilisant 21.dev, les agents obtiennent la capacité d'opérer sur des composants d'interface utilisateur en direct, générant des sorties qui reflètent l'état en temps réel avec une couche visuellement riche.
Vision Futuriste pour MCP avec OpenLedger
OpenLedger envisage que le MCP évolue en un registre onchain. Chaque outil MCP peut être enregistré, versionné et attribué. Les outils deviennent des composants composables que n'importe quel agent peut invoquer, avec un usage enregistré et récompensé sur la chaîne. Cela permet aux développeurs de publier des lecteurs de fichiers, des rendus ou des clients API, et de les faire appeler par n'importe quel agent basé sur OpenLedger avec une attribution et une traçabilité complètes.
Génération Augmentée par Récupération
Certaines connaissances sont trop vastes, trop détaillées ou mises à jour trop fréquemment pour être intégrées directement dans les poids du modèle. Pourtant, elles sont fondamentales pour le raisonnement. La Génération Augmentée par Récupération (RAG) étend la capacité d'un modèle en introduisant une mémoire spécifique à la requête en temps réel.
RAG sépare le stockage de l'inférence. Les documents sont intégrés dans des vecteurs, indexés sémantiquement et récupérés à l'exécution en fonction de la requête de l'utilisateur. Le contenu récupéré est ensuite injecté dans la fenêtre de prompt, ancrant la réponse du modèle.
Cette méthode est particulièrement pertinente pour les agents spécifiques à un domaine. Un agent entraîné pour comprendre un domaine particulier pourrait accéder à des articles de blog, à de la documentation, à des propositions et à des fils de discussion communautaires. Au lieu de mémoriser tout ce contenu, il interroge un système RAG construit à partir de sources fiables. La réponse est précise, à jour et ancrée dans des preuves réelles. Cette structure permet aux agents d'éviter les hallucinations, tout en leur permettant de rechercher, récupérer et raisonner à travers du contenu dynamique.
Vision Futuriste pour RAG avec OpenLedger
OpenLedger étend RAG en une couche collaborative et attribuable. Tout comme avec les ensembles de données et les modèles, chaque document stocké dans un index RAG est attribué à son contributeur. Lorsque le document est récupéré, cette utilisation est enregistrée. Cela transforme RAG d'un système de mémoire en un mécanisme incitatif.
À l'avenir, les contributeurs pourront enregistrer des documents on-chain dans le cadre d'un graphe de connaissances distribué. Chaque événement de récupération déclenchera des micro-attributions, créant un flux transparent de crédit et de valeur économique lié à l'influence informationnelle.
Un agent basé sur OpenLedger formé sur du contenu spécifique à la plateforme tel que des articles de blog, de la documentation, des propositions de gouvernance et des conversations d'utilisateurs n'aura pas besoin de mémoriser tout le contexte. Il peut interroger un système RAG décentralisé construit à partir de sources communautaires vérifiées. Chaque segment récupéré renvoie à son auteur, permettant une distribution de récompense même au moment de l'inférence.
Avec l'infrastructure d'OpenLedger, RAG devient un système de raisonnement vérifiable et incitatif. Chaque paragraphe, citation ou point de données peut être tracé, réutilisé et monétisé de manière à refléter une véritable influence à travers l'écosystème des agents.
Prompts comme Logique de Comportement
La couche finale d'un agent intelligent est son comportement. Cela n'est pas codé dans les poids ou les données. Il est défini par des prompts.
Un prompt structure l'interaction. Il dit au modèle comment penser, comment formater sa sortie et quelles contraintes suivre. Il agit comme la couche logique qui gouverne comment les entrées sont interprétées et comment les outils sont invoqués. Dans les agents complexes, la conception des prompts n'est pas une instruction unique. Elle peut impliquer des chaînes de modèles structurés, des champs de contexte dynamiques et des instructions de planification.
L'ingénierie des prompts permet aux développeurs de définir le comportement de l'agent sans changer le modèle lui-même. Avec le bon design, les agents deviennent déterministes dans leurs étapes de raisonnement. Leurs sorties restent cohérentes, l'utilisation des outils est limitée, et les réponses reflètent à la fois le contexte donné et l'objectif prévu.
Vision Futuriste pour les Prompts avec OpenLedger
OpenLedger considère les prompts comme des actifs programmables. À l'avenir, cela pourrait conduire à une norme de contrat intelligent pour les prompts, permettant de les déployer, de les versionner et de les référencer directement sur la chaîne. Les prompts deviendraient des éléments de construction de première classe dans le développement d'agents, avec attribution et réutilisabilité intégrées dans leur conception.
Un registre de prompts sur OpenLedger permettrait aux développeurs de créer et de publier des modèles réutilisables liés à des tâches, outils ou modèles spécifiques. Ces modèles pourraient être liés à des agents, mis à jour au fil du temps et monétisés en fonction de leur utilisation.
Chaque prompt utilisé par un agent pourrait être retracé jusqu'à son auteur. L'attribution serait appliquée au niveau de l'infrastructure, permettant des récompenses équitables, une coordination transparente et une interopérabilité au niveau du comportement entre agents. Les prompts ne seraient plus de simples chaînes statiques, mais des composants dynamiques et vérifiables de systèmes intelligents.
Étude de Cas : Construire un Agent de Trading Entraîné par la Communauté sur OpenLedger
C'est ainsi qu'un véritable agent de trading peut être construit en utilisant OpenLedger. Il commence avec des données, construit le modèle, ajoute des outils en direct, et se transforme en une application fonctionnelle.
Étape 1 : Collecte de Données Communautaires
Le processus commence avec un Datanet. Un Datanet est une plateforme de collaboration de données communautaires. Les traders de Discord, Twitter et d'autres communautés contribuent des stratégies de trading, des annotations de graphiques, des analyses de tokens et des décisions de trading. Le propriétaire du Datanet examine et vérifie chaque soumission. Une fois approuvé, les données sont ajoutées au Datanet et deviennent partie d'un ensemble de données d'instructions en croissance. Chaque contributeur est enregistré sur la chaîne.
Étape 2 : Entraîner un Modèle Spécialisé
En utilisant les données vérifiées du Datanet, un modèle est affiné pour comprendre les motifs de trading, comment les traders pensent et comment les décisions sont prises. Le modèle est déployé en utilisant OpenLoRA. Cela garde le modèle léger, moins cher à exécuter et facile à mettre à jour.
Étape 3 : Ajouter un Contexte en Temps Réel avec MCP
L'agent a besoin de données de marché en direct pour prendre des décisions. Grâce au Protocole de Contexte de Modèle (MCP), il se connecte à :
-> CoinMarketCap pour les prix des tokens
-> Binance et Coinbase pour les trades en temps réel
-> Kaito pour la tendance d'opinion sur Twitter
-> Uniswap ou PancakeSwap pour la liquidité on-chain
Chaque fois qu'un outil est utilisé, l'attribution est enregistrée sur la chaîne.
Étape 4 : Utiliser RAG pour la Mémoire de Marché
L'agent a aussi besoin de contexte historique. En utilisant la Génération Augmentée par Récupération (RAG), il extrait des informations telles que :
-> Livres blancs de tokens
-> Propositions de DAO
-> Décisions de gouvernance
-> Calendriers d'émission
-> Archives des exploits passés ou événements majeurs
Cela donne à l'agent une connaissance complète des tokens qu'il analyse.
Étape 5 : Définir les Règles de l'Agent comme Prompts
Les prompts disent à l'agent comment combiner toutes les données et prendre des décisions. L'agent vérifie les prix, la liquidité, le sentiment et l'historique des tokens.
-> Si le sentiment est élevé mais que la gouvernance est faible ou s'il y a des problèmes passés, cela signale un risque élevé
-> Si la volatilité est élevée et que le sentiment est incertain, cela attend.
-> Si les fondamentaux et le sentiment sont forts, cela suggère une entrée possible.
Les prompts sont versionnés, réutilisables et entièrement attribués.
Étape 6 : Attribuer Tout Onchain
Chaque ensemble de données, outil, prompt et document utilisé par l'agent est enregistré sur OpenLedger. Les contributeurs reçoivent automatiquement du crédit chaque fois que leur travail alimente une décision d'agent.
Le Résultat
Les données communautaires deviennent un agent de trading pleinement fonctionnel. Il lit les marchés en direct, comprend l'historique des tokens, applique le raisonnement et prend des décisions claires. Tout ce qu'il fait est transparent, traçable et récompense chaque contributeur impliqué. C'est ainsi que les agents sont construits sur OpenLedger.
