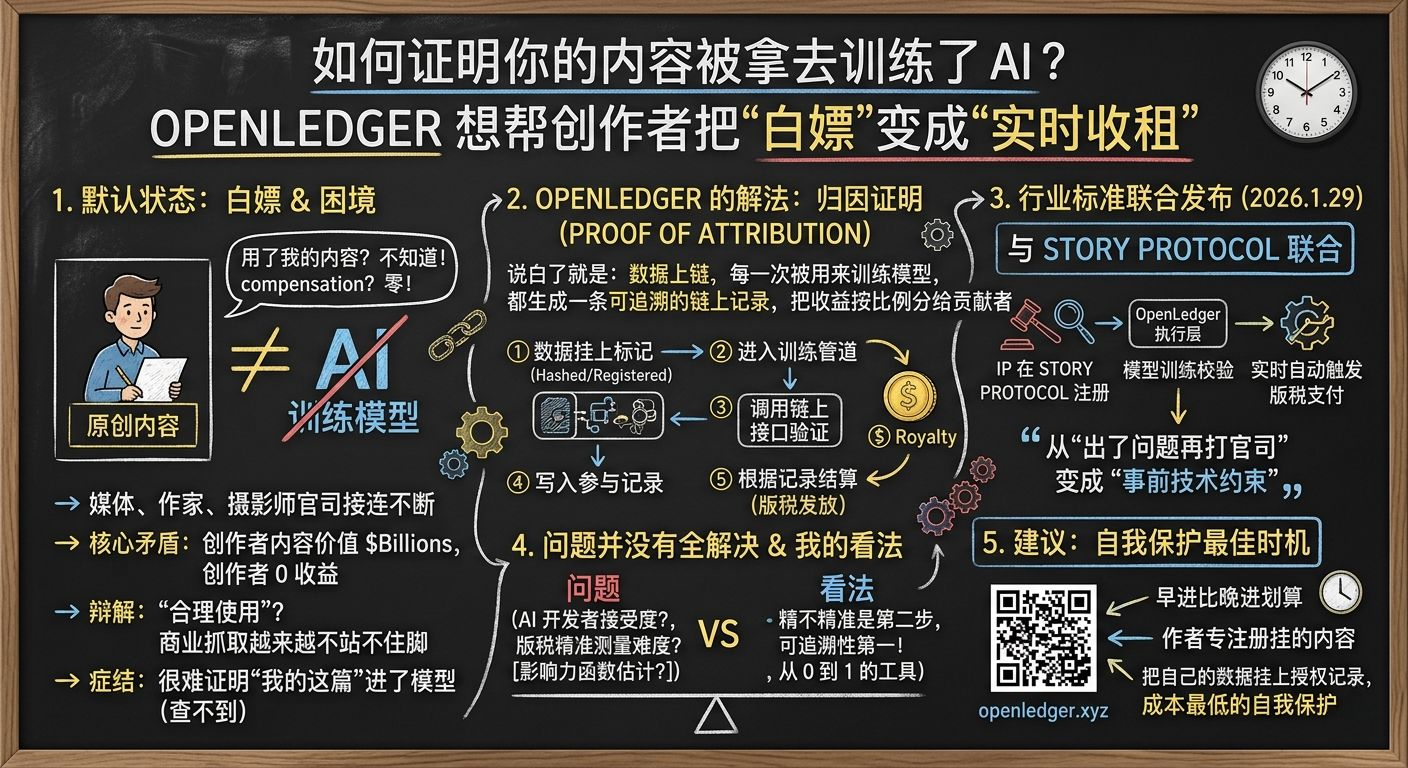
如果你在平台上发过原创内容,你大概率无法知道它有没有被拿去训练 AI,更谈不上任何补偿,这不是个别人的困境,而是整个内容生态目前面对 AI 训练数据问题的默认状态。
过去几年,围绕 AI 训练数据版权的官司一场接一场,作家、摄影师、媒体机构都在状告各大 AI 公司。这些案件的核心矛盾很简单:创作者的内容被用来训练了价值数十亿美元的模型,但创作者拿到的是零。AI 公司的常见辩解是“这属于合理使用”,但合理使用本来是为了学术研究和评论这类场景设计的,拿来给商业 AI 公司大规模抓取训练数据,这个解释越来越站不住脚了。而且真实情况是,即使你想起诉,你也很难证明“我的这篇文章”确实进了某个模型的训练集,因为根本查不到。这才是问题的症结所在,不是法律不够用,而是技术层面根本没有工具去证明“谁的数据、被怎么用了”。
@OpenLedger 想解决的就是这个。它的核心机制叫 Proof of Attribution(归因证明),说白了就是:数据上链,每一次被用来训练模型,都生成一条可追溯的链上记录,然后根据这条记录,把模型产生的收益按比例分给数据贡献者。你的文章用了多少,贡献了多少,能查到,能结算。如果你想知道这在技术上是怎么发生的:数据进入训练管道前,会先经过哈希标记并注册上链;训练框架在读取数据时调用链上接口验证授权状态,同时写入这条数据参与本次训练的记录。这条记录不可篡改,事后可查,版税结算以此为依据。
2026 年 1 月 29 日,OpenLedger 和 Story Protocol 联合发布了一套更完整的行业标准。这套标准的思路是:IP 先在 Story Protocol 注册,明确授权条款和版税比例,然后 OpenLedger 作为执行层,在模型训练和推理的过程中实时校验 IP 使用是否合规,并自动触发版税支付。OpenLedger 的联合创始人 Ram Kumar 在发布会上谈到,这套标准的核心转变是:从"先训练、出了问题再打官司"变成"只使用你能事先证明有权用的数据",把版权执行从事后补救变成事前的技术约束。
当然,也不是所有问题都解决了。#OpenLedger 这套标准目前主要面向的是那些愿意主动接入 OpenLedger 体系的 AI 开发者,那些本来就不在乎版权的大公司会不会采用,这还是个问号。更现实的担忧是:链上证明的是数据有没有进入训练管道,但 AI 输出里到底有多少是你那篇文章的贡献,这个测量本身就极其复杂,PoA 白皮书里提到了影响力函数估算这个方法,但准确性和可操作性还需要真实场景的检验。
我个人觉得,版税精不精准是第二步的问题,就像音乐版权的起点不是“Spotify 给我的分成算法对不对”,而是“我的歌有没有出现在他们的库里,有没有人有权使用它”。可追溯性先于计算精度,没有前者,后者没有意义。对于创作者来说,最重要的先是知道自己的数据有没有被用、有没有授权记录。从这个角度看,OpenLedger 做的这件事确实在帮创作者从零到一地拿到一个之前完全没有的工具。
如果你也在这些平台上发内容,建议去 openledger.xyz 看一下他们的数据注册流程。不用等所有问题都解决再行动,先把自己的数据挂上授权记录,是当前成本最低的自我保护方式。我盯了一段时间,这件事目前是真的在跑,不是 PPT。早进比晚进划算。$OPEN