Je pensais que le plus gros défi pour l'IA était l'intelligence.
Meilleurs modèles, agents plus rapides, prompts plus clairs, coûts informatiques réduits — cela semblait être tout le jeu. Mais plus je vois de vraies entreprises expérimenter avec l'IA, plus je pense que le problème le plus difficile n'est pas l'intelligence. C'est la responsabilité.
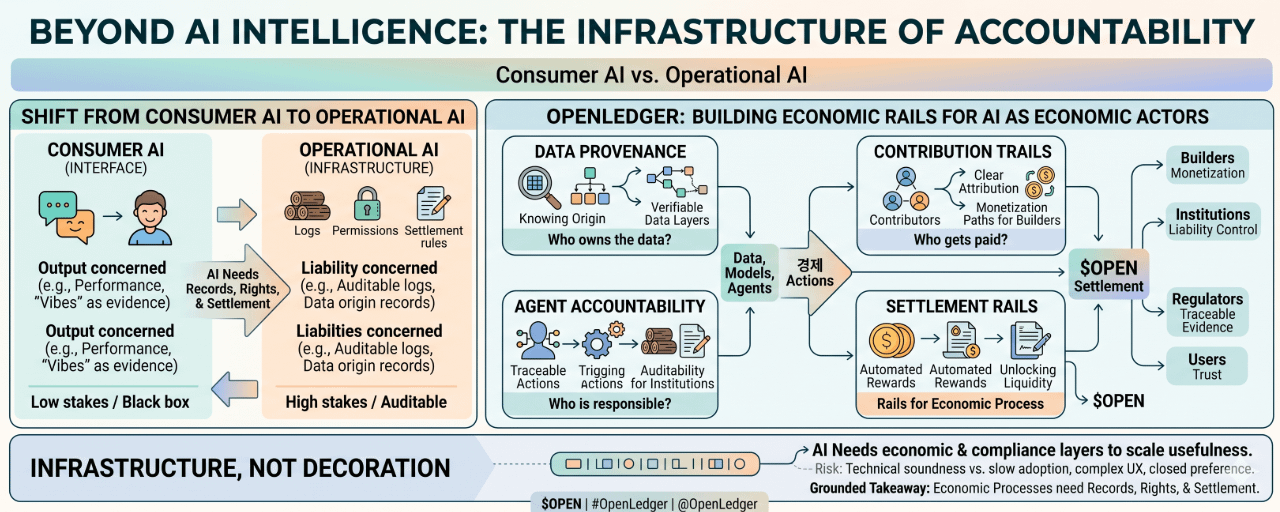
Qui possède les données derrière une réponse ?
Qui est payé quand un modèle utilise un dataset ?
Qui est responsable quand un agent IA prend une décision ?
Et comment prouver ce qui s'est réellement passé après coup ?
C'est là que la conversation autour de @OpenLedger commence à me sembler plus pratique. Pas parce que ça résout magiquement tous les problèmes de l'IA, mais parce qu'OpenLedger se penche sur la partie de l'infrastructure IA qui devient inévitable une fois que l'IA commence à toucher l'argent, les contrats, les utilisateurs et les flux de travail réglementés.
Le véritable problème n'est pas seulement la sortie de l'IA

Une banque ne peut pas simplement dire : "L'IA a dit que ça avait l'air bien." Une entreprise de santé ne peut pas ignorer d'où viennent les données d'entraînement. Une société de trading ne peut pas laisser un agent agir sans journaux, autorisations, règles de règlement et auditabilité. Un régulateur n'acceptera pas des impressions comme preuve.
C'est le fossé entre l'IA des consommateurs et l'IA opérationnelle.
Pour les utilisateurs, la préoccupation est la confiance.
Pour les créateurs, la préoccupation est la monétisation et l'attribution.
Pour les institutions, la préoccupation est la responsabilité.
Pour les régulateurs, la préoccupation est de savoir si les décisions peuvent être retracées, examinées et contestées.
Les systèmes d'IA centralisés peuvent bien fonctionner lorsque les enjeux sont faibles. Mais quand les données, les modèles, les agents et les paiements interagissent, le système a besoin de plus que de la performance. Il a besoin de traces.
Pourquoi le règlement est important dans l'IA

C'est là que l'infrastructure basée sur la blockchain devient pertinente.
Si un modèle utilise un ensemble de données, il doit y avoir un moyen clair de savoir si cet ensemble de données a apporté de la valeur. Si un agent effectue une tâche, il doit y avoir un moyen de vérifier ce qu'il a consulté, ce qu'il a déclenché, et qui doit recevoir une compensation. Si plusieurs parties contribuent des données, des modèles ou de la logique d'agent, la distribution de la valeur ne peut pas dépendre uniquement de feuilles de calcul privées.
C'est là que l'infrastructure basée sur la blockchain devient pertinente.
L'accent mis par OpenLedger sur le déblocage de la liquidité autour des données, des modèles et des agents n'est pas seulement une question de création d'une autre histoire d'actif crypto. L'idée plus intéressante est que les ressources d'IA pourraient devenir traçables, possédables et monétisables de manière plus structurée.
Dans ce contexte, $OPEN représente plus qu'un simple ticket de campagne. Cela pointe vers une économie où les contributions liées à l'IA pourraient nécessiter des rails pour la propriété, l'accès, le règlement et les incitations.
OpenLedger comme infrastructure, pas décoration

L'argument le plus fort est que les systèmes d'IA deviennent des acteurs économiques. Les agents peuvent réserver des services, exécuter des trades, gérer des flux de travail, acheminer des données, comparer des fournisseurs ou déclencher des paiements. Une fois cela fait, l'infrastructure qui les soutient doit répondre à des questions de base.
Quelles données l'agent a-t-il utilisées ?
Le modèle était-il autorisé à y accéder ?
Qui a contribué à la sortie ?
Comment les revenus doivent-ils être répartis ?
Le processus peut-il être audité plus tard ?
OpenLedger pourrait avoir de l'importance car il traite les données, les modèles et les agents comme des actifs avec des relations économiques, et non comme de simples ingrédients invisibles à l'intérieur d'une boîte noire.
Cela est particulièrement pertinent pour les bâtisseurs. De nombreux bâtisseurs créent des ensembles de données, des modèles ajustés, des outils, des automatisations ou des agents, mais ont du mal à les monétiser au-delà des abonnements, des clés API ou des contrats de licence ponctuels. Une couche d'infrastructure plus ouverte pourrait permettre à ces contributions d'être découvertes, utilisées, vérifiées et récompensées avec des règles plus claires.
Un exemple pratique

Imaginez une startup de conformité construisant un agent IA pour la révision des factures transfrontalières.
L'agent vérifie les documents des fournisseurs, les compare aux règles de la politique, signale des comportements de paiement inhabituels, et recommande si une facture doit être approuvée. Pour bien faire cela, il peut s'appuyer sur plusieurs choses : un ensemble de données de fournisseurs vérifiés, un modèle de détection de fraude, un modèle de risque spécifique à l'industrie, et des règles internes de l'entreprise.
Dans une configuration normale, beaucoup de cela devient difficile à retracer. L'entreprise peut connaître la recommandation finale, mais pas toujours la chaîne de contribution complète qui la sous-tend.
Avec une infrastructure comme OpenLedger, la startup pourrait théoriquement créer un système où chaque source de données, modèle et interaction d'agent a des enregistrements de propriété et d'utilisation plus clairs. L'institution obtient une meilleure auditabilité. Les créateurs obtiennent un meilleur chemin vers la capture de valeur. Les régulateurs obtiennent une trace plus révisable. Les utilisateurs obtiennent un système moins dépendant de la confiance aveugle.
Cela ne rend pas l'IA parfaite. Mais cela rend la couche économique et de conformité plus visible.
Le Risque : L'adoption ne sera pas automatique

Le risque est que ce type d'infrastructure puisse être techniquement solide mais socialement lent.
Les institutions avancent prudemment. Les régulateurs peuvent ne pas comprendre immédiatement les nouvelles couches de règlement pour l'IA. Les créateurs peuvent résister à une complexité supplémentaire si l'expérience utilisateur n'est pas simple. Les entreprises peuvent préférer des systèmes fermés car elles semblent plus faciles à contrôler.
Il y a aussi une question de coût. Si le suivi, la vérification et le règlement ajoutent trop de friction, les équipes peuvent les éviter à moins que la régulation ou la demande des clients ne forcent la question.
Le défi d'OpenLedger n'est pas seulement de construire une infrastructure utile. Il doit également prouver que la confiance, la liquidité et l'attribution ajoutées valent l'effort opérationnel.
C'est une barre élevée.
Les personnes les plus susceptibles de se soucier d'OpenLedger ne sont pas seulement les traders surveillant #OpenLedger . Ce sont des créateurs qui essaient de monétiser le travail de l'IA, des institutions qui ont besoin de flux de travail d'IA vérifiables, des utilisateurs qui veulent plus de confiance dans les systèmes automatisés, et des régulateurs qui ont besoin de preuves plus claires lorsque les choses tournent mal.
Cela pourrait fonctionner parce que l'IA passe des fenêtres de chat à de réels processus économiques, et les processus économiques ont besoin de traces, de droits et de règlements.
Cela pourrait échouer si l'infrastructure semble trop complexe, si les institutions restent à l'aise avec des systèmes fermés, ou si les créateurs ne voient pas assez d'avantages pratiques.
Pour moi, la partie intéressante de @OpenLedger n'est pas la promesse que tout devient décentralisé du jour au lendemain. C'est la possibilité plus discrète que l'IA puisse avoir besoin d'une infrastructure financière et juridique avant de pouvoir devenir véritablement utile à grande échelle.
Ce n'est pas un conseil financier.
Que pensez-vous qui compte le plus pour l'adoption de l'IA : de meilleurs modèles ou de meilleurs systèmes de confiance, de propriété et de règlement ?