@OpenLedger There is a strange pattern I keep noticing in how people interact with tools, especially in AI workflows. The weakest piece rarely reveals itself immediately. At first, it just feels inconvenient or slightly off, so the instinct is to blame it outright. But after spending enough time with it, something shifts. The problem does not always lie in the tool being useless. Sometimes it is simply misplaced, misunderstood, or judged against expectations it was never meant to meet. That thought keeps pulling me back toward OpenLedger and the idea behind $OPEN. While most of the AI space is busy chasing the best possible models, the fastest systems, and the most refined outputs, there is a quieter layer forming underneath. Markets do not only revolve around excellence. They also evolve around what is incomplete, overlooked, or imperfect but still functional in the right context.
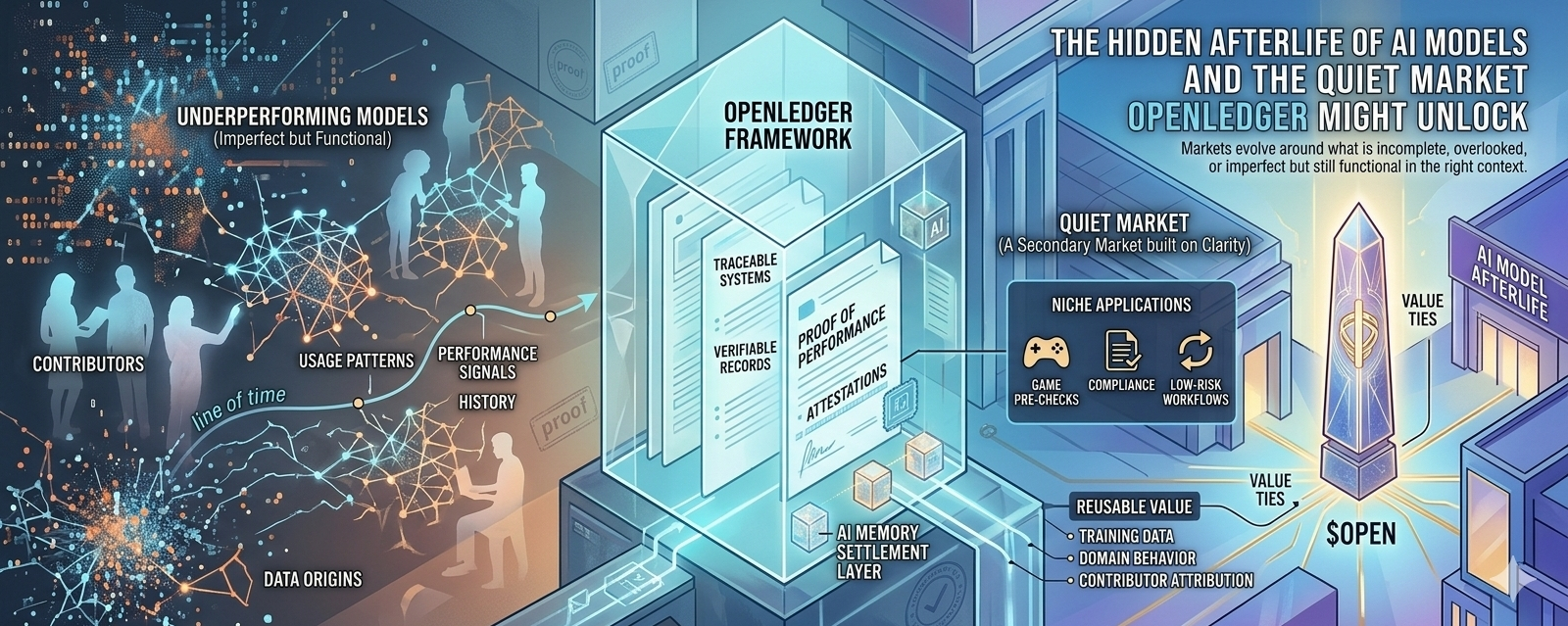
An underperforming AI model sounds like something that should naturally fade away. It lacks accuracy, struggles across broad use cases, and cannot compete with stronger alternatives. But that assumption feels too simple. Not every weak model is equally disposable. Some fail broadly but still perform reliably in narrow environments. Others carry value in ways that are less obvious, like the data they were trained on, the contributors who shaped them, or the consistency of their behavior over time. In that sense, the model itself becomes more than just an output engine. It starts to resemble an asset with a history, even if that history includes flaws. If OpenLedger can capture and structure that history through contribution records, data origin, usage patterns, and performance signals, then these models stop being black boxes. They become traceable systems that can be examined, compared, and potentially reused.
What makes this idea compelling is not the celebration of weak models, but the recognition that failure is not always absolute. There is a meaningful difference between something that is completely broken and something that works within limits. A model that cannot function as a general assistant might still be valuable in repetitive workflows, low-risk classifications, content filtering, localized datasets, or even controlled environments like gaming or compliance pre-checks. In these scenarios, perfection is not the goal. Predictability, cost-efficiency, and known limitations matter more. The missing piece has always been proof. It is easy to claim what a model can do, but much harder to show a verifiable record of how it has performed, who has used it, and whether its results hold up over time. If that layer of proof becomes accessible and structured, then the conversation shifts from belief to inspection.
This is where the idea of a secondary market begins to take shape. Not a market driven by hype, but one built around clarity. Instead of asking whether a model is the best, it asks where it still works and why. It looks at repeated usage rather than one-time activity, at dependency rather than temporary incentives, and at whether its limitations are manageable in a specific role. That kind of market would not treat all underperforming models as equal. Some would still fade into irrelevance, but others might find a second life in niches where their flaws are acceptable or even predictable. It is a subtle shift, but an important one, because it acknowledges that value in AI does not always come from dominance. Sometimes it comes from fit.
At the same time, this opens the door to a slightly uncomfortable reality. If underperforming models can still carry value, then builders might begin optimizing for what can be salvaged rather than what can truly excel. That instinct is not new. It already exists across different industries, where failed ideas are repackaged, repurposed, or sold for parts. Intellectual property survives even when products do not. Communities outlive the platforms that created them. Narratives are recycled long after their original momentum fades. AI could follow a similar path, except the reusable value might live in training data, contributor attribution, domain-specific behavior, and historical records instead of branding alone. It may not look clean, but markets rarely are.
For $OPEN, the deeper question is whether it becomes tied to this emerging layer of AI infrastructure. Not every interaction within a marketplace creates meaningful demand for a token. Activity can be misleading, especially when incentives are involved. What matters more is whether the system becomes necessary. If OpenLedger’s framework is required for tracking model histories, verifying contributions, managing permissions, and preserving attestations, then it begins to function as a settlement layer for AI memory rather than just another platform. That kind of dependency is harder to fake and more difficult to replace. Still, it is not guaranteed. The gap between a working marketplace and a necessary one is where most ideas struggle.
None of this feels fully formed yet, and that is part of the reason it stands out. Underperforming models are not easy to value. Their usefulness depends on context, and their limitations can be difficult to communicate clearly. It would be easy for the market to misprice them or inflate their importance. But that uncertainty is also where new systems tend to emerge. The focus in AI has been heavily tilted toward identifying the winners, as if everything else simply disappears. In reality, there is always a middle ground where things do not win, but also do not vanish. That in-between space is often where unexpected markets begin to grow, quietly shaping the next layer of how value is understood.