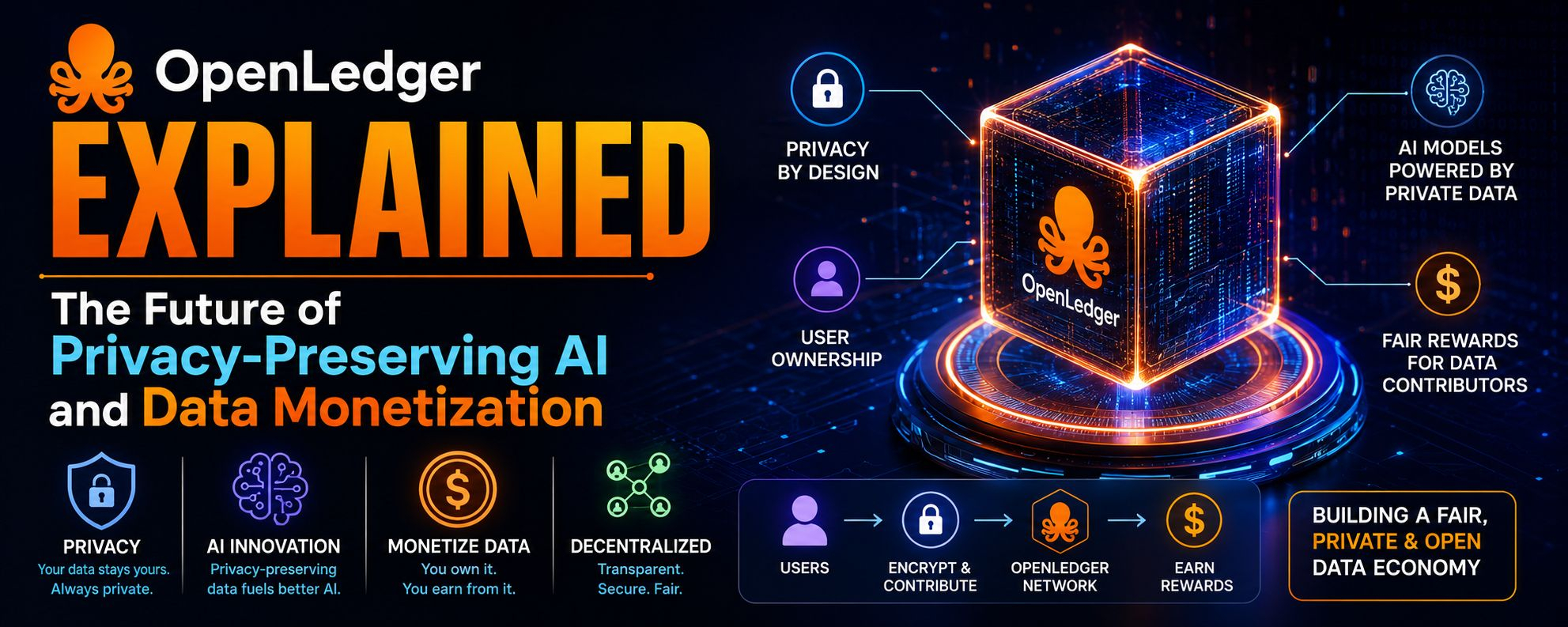
J'ai vu OpenLedger plus comme un changement de narration que simplement un autre projet « IA + blockchain », et ma première impression est qu'il essaie de se situer exactement à l'intersection où se trouve la plus grande tension d'aujourd'hui : l'IA veut plus de données pour devenir utile, mais le monde réel se déplace dans la direction opposée où les données deviennent plus verrouillées, réglementées, et sensibles à la vie privée.
Sur le plan émotionnel, je trouve l'idée vraiment excitante mais aussi un peu trop optimiste quant à la façon dont le monde va s'accorder sur la monétisation des données. L'excitation vient d'une frustration très réelle que l'on observe déjà dans des secteurs comme la santé, la finance, et l'IA d'entreprise. Tout le monde a des données, tout le monde veut utiliser l'IA, mais presque personne ne veut plus exposer des ensembles de données brutes. Donc, un système qui promet « vous pouvez prouver la valeur, entraîner des modèles, ou utiliser des agents sans révéler les données sensibles sous-jacentes » semble être une évolution naturelle. En même temps, je reste sceptique car les incitations liées à la propriété des données sont compliquées, et amener les hôpitaux, les gouvernements, ou les grandes entreprises à se standardiser autour d'une couche de liquidité on-chain partagée pour les données est historiquement extrêmement difficile.
En termes simples et concrets, imagine un hôpital utilisant l'IA pour détecter le cancer à un stade précoce à partir de scans. Aujourd'hui, soit l'hôpital envoie des données à un fournisseur d'IA centralisé, soit il gère tout en interne. Les deux options ont des inconvénients : un risque de confidentialité d'un côté, une amélioration limitée des modèles de l'autre. Dans un système comme celui qu'OpenLedger propose, l'hôpital pourrait théoriquement permettre aux modèles d'IA d'apprendre des motifs dans ses données sans jamais exposer les dossiers bruts des patients, et ne partager que des preuves ou des confirmations cryptographiques qu'un modèle a été correctement entraîné ou utilisé de manière appropriée. Ça a l'air puissant, surtout dans des domaines comme le diagnostic, la découverte de médicaments ou la génomique, où la sensibilité des données est extrêmement élevée.
Un autre exemple est la détection de fraude en assurance. Les compagnies d'assurance ont d'énormes ensembles de données, mais elles les partagent rarement car elles contiennent des informations personnelles et réglementées. Une couche d'exécution d'IA préservant la confidentialité pourrait permettre à plusieurs assureurs de contribuer à un modèle de détection de fraude partagé tout en gardant les données au niveau client cachées. Ce genre de divulgation sélective est là où le concept devient plus qu'une simple théorie et commence à avoir une valeur opérationnelle.
Ce qu'OpenLedger essaie d'aborder au fond, ce sont trois problèmes qui se chevauchent. Le premier est la sous-utilisation des données, où des ensembles de données précieux restent inactifs parce qu'ils ne peuvent pas être partagés en toute sécurité. Le deuxième est l'attribution de modèles d'IA, c'est-à-dire qui a réellement contribué aux données, à la computation ou à l'effort d'entraînement d'un système d'IA. Le troisième est le frottement de la monétisation, où aujourd'hui il n'existe pas de marché propre où les données, les modèles et les agents peuvent être tarifés, suivis et récompensés de manière transparente sans complications légales et de confidentialité qui bloquent constamment le processus.
Les utilisateurs visés ne sont pas des utilisateurs occasionnels du tout. Cela cible clairement les entreprises, les développeurs d'IA, les fournisseurs de données et les opérateurs d'infrastructure. En théorie, les hôpitaux, les laboratoires de recherche, les entreprises fintech et même les développeurs d'agents d'IA autonomes seraient les principaux bénéficiaires. La commodité qu'il promet est essentiellement une couche de coordination où il n'est pas nécessaire de négocier manuellement chaque accord de partage de données ou de construire des pipelines d'IA isolés pour chaque partenaire. Au lieu de cela, tu te connectes à un système partagé où l'accès, la preuve et l'échange de valeur sont gérés de manière programmatique.
D'un point de vue fonctionnel, l'idée la plus importante est la "visibilité contrôlée". Au lieu que des données brutes soient partagées, ce qui est partagé ce sont des résultats de computation vérifiables, des preuves d'utilisation, ou des sorties de modèles liées à une responsabilité cryptographique. Si cela fonctionne comme prévu, cela réduit les frictions dans les environnements réglementés tout en permettant aux systèmes d'IA de s'améliorer grâce à des signaux d'apprentissage plus larges. C'est un avantage conceptuel très fort dans un monde où les réglementations sur la confidentialité comme les cadres de style GDPR deviennent plus strictes à l'échelle mondiale.
En examinant les tendances plus larges à l'heure actuelle en 2026, l'infrastructure de l'IA se déplace rapidement vers une computation préservant la confidentialité, et pas seulement un entraînement centralisé. Des techniques comme l'apprentissage fédéré, les enclaves sécurisées et les preuves à divulgation nulle passent d'expérimentales à une utilisation en production précoce, surtout dans les soins de santé et l'analyse financière. En même temps, les systèmes blockchain peinent à trouver une réelle utilité au-delà de la spéculation, donc tout projet qui connecte la blockchain à une charge de travail réelle d'IA comme l'attribution de données ou le licensing de modèles a un meilleur récit que le pur DeFi. Cependant, la réalité est que l'adoption est encore précoce. La plupart des entreprises expérimentent, mais ne s'engagent pas encore dans des marchés d'IA entièrement décentralisés.
L'upswing futur, si OpenLedger exécute bien, pourrait être significatif. Cela pourrait créer une couche où les données d'entraînement d'IA deviennent une classe d'actifs traçable et compensable. Cela changerait fondamentalement les incitations pour les créateurs de données et pourrait même conduire à de nouveaux modèles économiques où de petits ensembles de données deviennent précieux s'ils sont de haute qualité et légalement utilisables. Cela pourrait également rendre les agents d'IA plus dignes de confiance dans des environnements réglementés car leurs pipelines de décision seraient audités sans exposer des données sensibles.
Mais les limitations sont tout aussi sérieuses. La plus grande est la complexité de la coordination. Faire en sorte que des institutions du monde réel s'accordent sur des normes partagées pour la confidentialité des données, les systèmes de preuves et les incitations tokenisées est extrêmement difficile. Un autre risque est la surcharge de performance. La computation préservant la confidentialité est encore plus coûteuse et plus lente que le traitement centralisé traditionnel. Ensuite, il y a le problème classique de la blockchain : si la couche de token ou d'incitation devient plus importante que l'utilité réelle, le système peut dériver vers la spéculation plutôt que vers une adoption réelle. Et enfin, il y a l'incertitude réglementaire. Même si les données ne sont pas directement exposées, les régulateurs peuvent toujours avoir des préoccupations concernant l'inférence transfrontalière ou la fuite indirecte de données.
Donc, ma conclusion honnête est la suivante. OpenLedger semble pointer vers un véritable avenir structurel des infrastructures d'IA où les données ne sont pas partagées directement mais deviennent néanmoins économiquement actives grâce à des preuves, des permissions et une computation contrôlée. L'idée est alignée avec la direction que prennent les soins de santé, la finance et l'IA d'entreprise. Mais l'écart entre la vision et le déploiement dans le monde réel est encore large, et le succès dépendra moins de l'élégance de la technologie et plus de la confiance des institutions et de leur intégration dans leurs opérations quotidiennes. Dans ce sens, ce n'est pas encore un produit fini aujourd'hui, mais plutôt un pari sur la façon dont les normes de la prochaine génération d'infrastructures d'IA seront définies.
\u003cm-34/\u003e \u003ct-36/\u003e \u003cc-38/\u003e
