Market felt off today. Not crash-off, just that kind of flat, directionless energy where everyone's refreshing the same charts and nothing's really moving. I ended up doing what I usually do in those moments — falling down a rabbit hole on something I'd been meaning to look at properly.
So I started poking around OpenLedger. $OPEN . I'd seen it mentioned a few times in passing, filed it under "AI plus blockchain, probably vague," and mostly moved on. But I had time today, so I actually sat with it.
Here's the thing that shifted for me.
Most of the AI infrastructure conversation right now is about who builds the models. Which lab, which team, which compute cluster. And OpenLedger is doing something that sits completely outside that frame — it's focused on who owns the data that trains those models. The provenance layer. The attribution chain that says: this output exists partly because of this contribution, from this person, at this point in time.
I thought that was a governance feature. A nice-to-have for regulatory optics.
But actually it might be the whole point.
Because the real bottleneck in AI development isn't the model architecture anymore. Most serious teams can access capable base models. The actual constraint is high-quality, domain-specific, traceable data. And right now that data flows in one direction — users generate it, platforms absorb it, and there's no mechanism for value to move back upstream. OpenLedger is essentially trying to instrument that upstream path. Tag contributions at origin, maintain the chain, and theoretically allow value to route back to whoever made the data useful.
That's the realization that stuck. The blockchain layer isn't there to make AI sound more interesting. It's there because attribution at scale — across millions of contributors, across time — isn't a database problem you can solve cheaply any other way.
But here's the part that actually bothers me.
The system rewards legibility. Your contribution has to be structured in a way the network can index and weight meaningfully. Which sounds neutral until you think about who is capable of doing that at the start. It's not the broad base of everyday users the project talks about in its vision. It's technically fluent early participants who understand how to package inputs, how to work with the contribution interface, how to make their data legible to a system that hasn't fully defined its own standards yet.
Those early contributors aren't just earning early — they're shaping the weighting logic. They're establishing what "good contribution" looks like before most participants even arrive. And once those patterns calcify, late participants are essentially playing a game where the scoring rubric was written by someone else.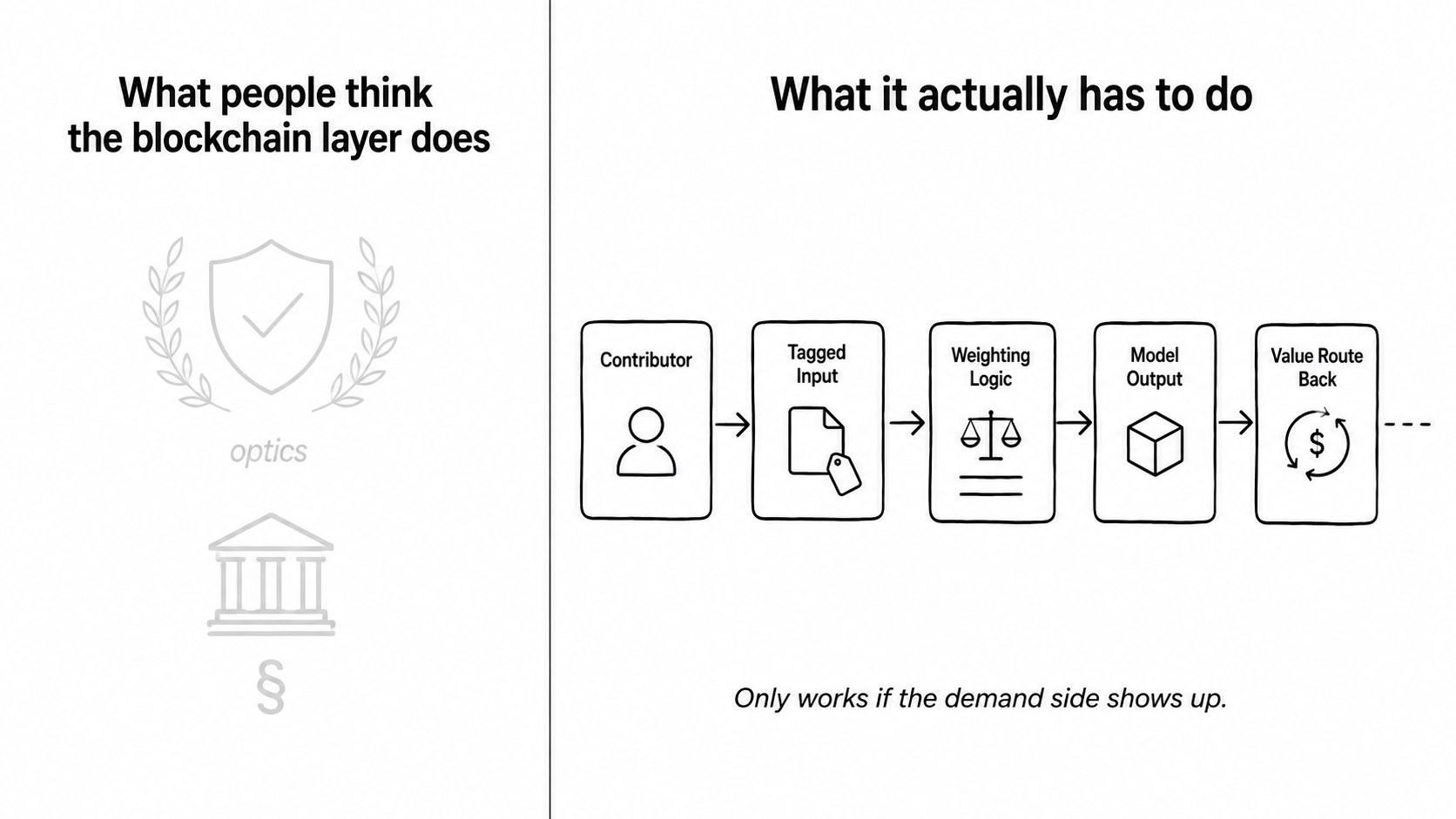
I'm not saying that's intentional. I'm not even sure it's avoidable in a bootstrapping phase. But I haven't seen OpenLedger address it directly, and that absence sits with me a little.
The other thing I keep turning over: this model only works if AI developers actually integrate the network as a sourcing and attribution layer, rather than just building their own data pipelines and ignoring the whole thing. That adoption dependency is real. A provenance layer nobody queries is just a ledger. The value of the infrastructure is entirely contingent on whether the demand side shows up. $OPEN's token dynamics are presumably built around that assumption, which means you're not just betting on the tech — you're betting on a coordination outcome between parties with very different incentive structures.
Maybe that happens. The economics of traceable, licensed training data are getting more interesting fast, especially with the legal pressure building around how models are trained. There's a version of this where OpenLedger ends up sitting in a genuinely necessary position.
But there's also a version where it becomes very good infrastructure for a market that fragments before it consolidates, and the early contributor base that shaped the weighting logic ends up holding a more complicated position than anyone anticipated.
I'll probably just watch how the data sourcing conversation evolves over the next few months. That's the actual tell. If you start seeing AI teams cite provenance requirements in their data acquisition, something is shifting. If you don't, the timeline on this is longer than the current energy around it suggests.
Anyway. Charts are still flat. Probably nothing happens today.