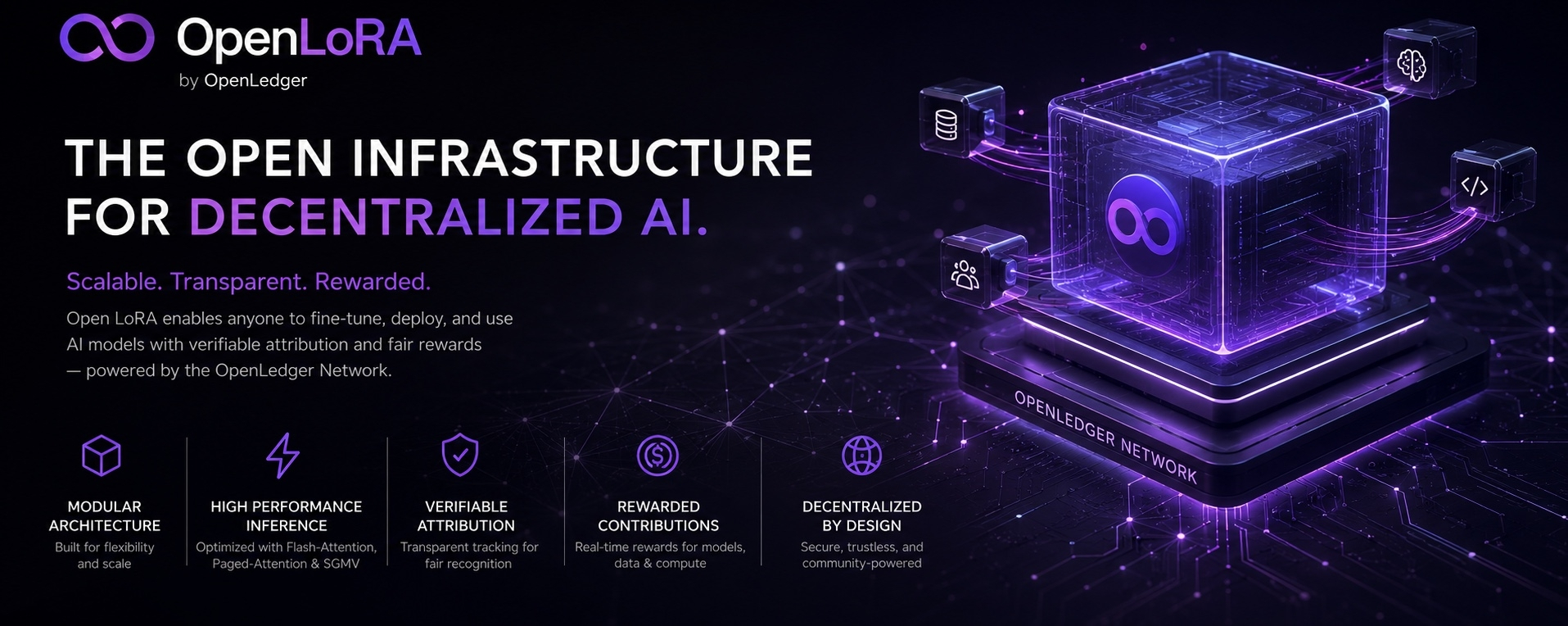
Composants principaux
Le cadre Open LoRA est conçu autour d'une architecture modulaire et évolutive qui permet un déploiement efficace des modèles, une inférence dynamique et une attribution transparente dans l'écosystème OpenLedger.
Stockage des adaptateurs LoRA
Les adaptateurs LoRA affinés sont stockés en toute sécurité dans l'infrastructure décentralisée d'OpenLedger. Au lieu de charger chaque adaptateur en mémoire simultanément, les adaptateurs sont récupérés et activés dynamiquement en fonction des exigences d'inférence, améliorant ainsi considérablement l'évolutivité et l'efficacité des ressources.
Hébergement de modèle & Fusion dynamique d'adaptateurs
Le système fonctionne sur une architecture de modèle fondamental partagé, où les adaptateurs LoRA sont fusionnés en temps réel lors de l'inférence. Cette approche minimise l'hébergement redondant de modèles tout en permettant une personnalisation rapide pour différentes tâches et domaines.
Open LoRA prend également en charge la fusion de style ensemble de plusieurs adaptateurs, permettant aux couches de connaissances combinées d'améliorer la qualité d'inférence et la performance globale du modèle.
Moteur d'inférence haute performance
La couche d'inférence est optimisée à l'aide de techniques d'accélération avancées basées sur CUDA, y compris :
Attention Flash — réduit l'overhead mémoire et améliore l'efficacité des transformateurs.
Attention Paginée — permet un traitement efficace de séquences de long contexte.
Optimisation SGMV (Multiplication de Matrices Vecteurs Générales Ésparses) — accélère le débit d'inférence tout en réduisant les coûts computationnels.
Ensemble, ces optimisations offrent des performances d'inférence de qualité production à faible latence.
Routage de requêtes & Diffusion de jetons
Une couche de routage de requêtes dédiée dirige dynamiquement les appels API vers les configurations d'adaptateurs appropriées pendant l'exécution. Les sorties générées sont diffusées efficacement à l'aide de noyaux de livraison de jetons optimisés, assurant des interactions en temps réel réactives et fluides.
Moteur d'attribution
La couche d'attribution suit et enregistre automatiquement chaque composant impliqué dans un processus d'inférence — y compris les modèles, adaptateurs, ensembles de données, ressources de calcul et contributeurs.
Cela crée un cadre d'attribution transparent et vérifiable qui :
Assure une reconnaissance équitable des contributeurs
Permet une distribution précise des récompenses
Maintient des enregistrements d'utilisation immuables en temps réel
Réseau OpenLedger
Le réseau OpenLedger agit comme la couche de coordination décentralisée connectant le stockage, l'inférence, l'attribution et les systèmes d'exécution en une infrastructure IA unifiée.
Les contrats intelligents gèrent :
Permissions d'accès
Journalisation des attributions
Vérification de l'utilisation
Distribution d'incitations tokenisées
Cette architecture permet une coordination sécurisée, évolutive et sans confiance à travers tout le cycle de vie de l'IA.
#OpenLedger #TradersShiftBTCToStablecoins #Jefferies$1TCryptoIPOMarket
#CashAppUSDCFor60MUsers
@OpenLedger $OPEN $BTC $ETH

