
Au début, je pensais honnêtement que @OpenLedger n'était qu'un autre coin d'IA.
Et pour être juste, le marché crypto est inondé d'eux en ce moment.
Chaque semaine, il y a un nouveau projet qui parle d'« infrastructure IA », « intelligence décentralisée » ou « l'avenir des agents autonomes ». La plupart semblent excitants au lancement, mais après avoir creusé un peu, beaucoup sont encore à la recherche d'une réelle utilité.
C'est pourquoi je n'ai pas prêté beaucoup attention à OpenLedger au début.
Mais après avoir passé quelques jours à rechercher son système de Preuve d'Attribution et le marché Datanets, je me suis rendu compte d'une chose importante :
OpenLedger essaie au moins de résoudre un vrai problème d'infrastructure.
Et à mon avis, ça le rend immédiatement plus intéressant que la plupart des narrations IA dans la crypto aujourd'hui.
Parce que l'actif le plus précieux en IA pourrait ne pas être le modèle lui-même.
Ça pourrait être les données.
Tout le monde parle de systèmes comme ChatGPT, d'agents IA et de modèles de milliards de dollars. Mais très peu de gens discutent sérieusement de l'énorme quantité de données requises pour entraîner ces systèmes.
D'où viennent ces données ?
Qui l'a contribué ?
Qui en est le propriétaire ?
Une permission a-t-elle été donnée ?
Et surtout...
Qui est récompensé quand les produits IA génèrent des milliards de valeur ?
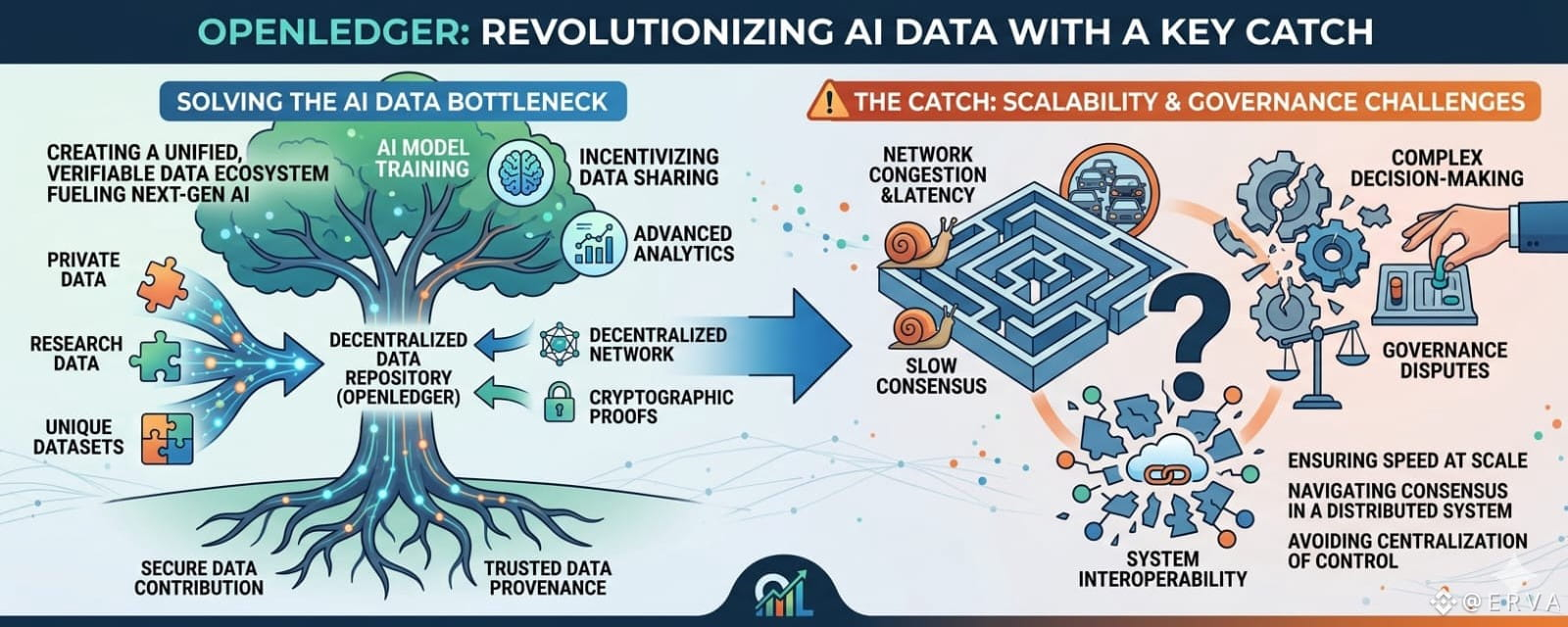
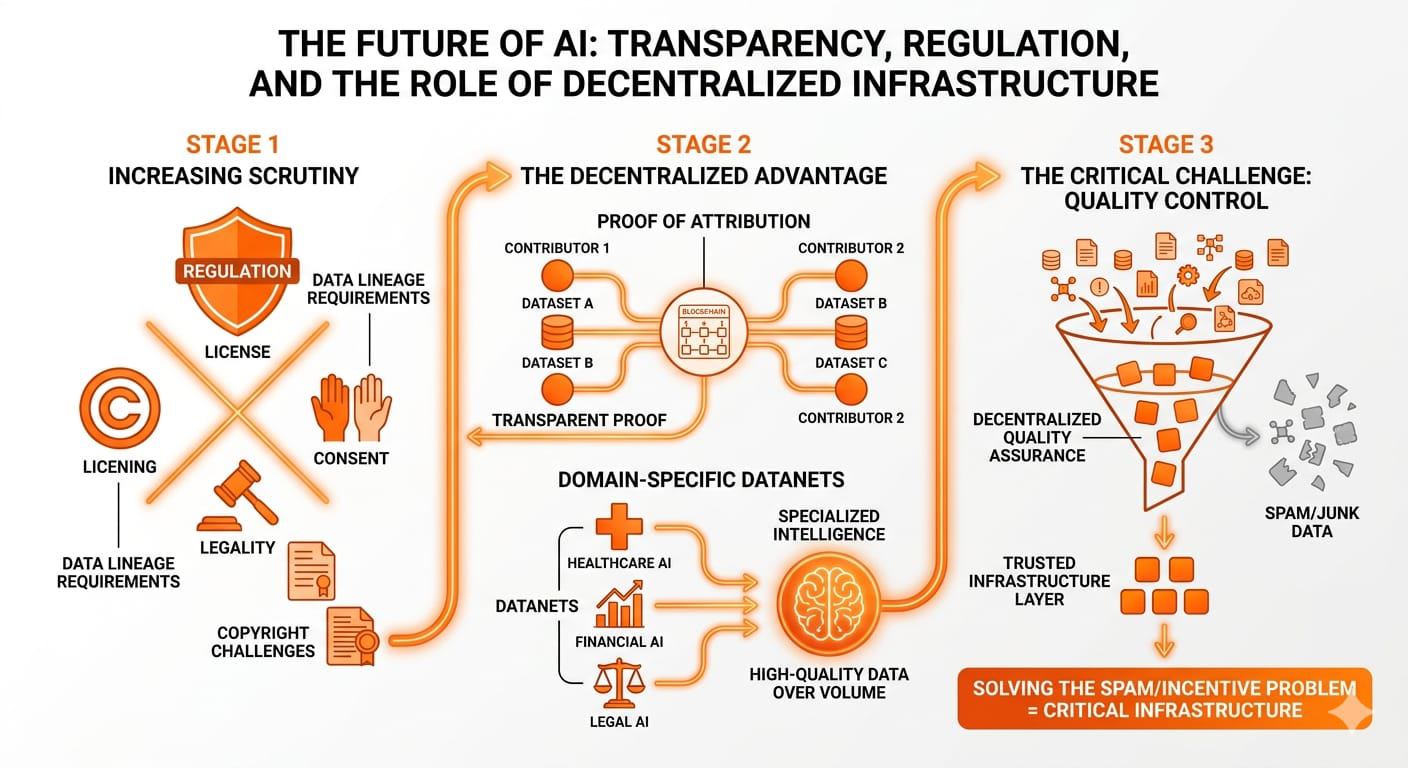
C'est le fossé qu'OpenLedger veut combler.
L'idée derrière le projet est étonnamment simple.
Les utilisateurs contribuent des ensembles de données au réseau. Les modèles IA s'entraînent sur ces ensembles de données. Le système suit quelles données ont influencé le modèle, et les contributeurs reçoivent des récompenses à travers un mécanisme appelé Preuve d'Attribution.
Honnêtement, conceptuellement, c'est une idée intelligente.
Au lieu que les données deviennent invisibles après téléchargement, OpenLedger veut que les contributeurs restent connectés à la valeur économique que leurs données aident à créer.
Et si l'IA continue de croître à ce rythme, l'attribution des données pourrait finalement devenir une industrie massive à part entière.
Mais c'est là que les choses deviennent compliquées.
Parce que construire un marché est facile.
Construire un marché de haute qualité ne l'est pas.
Et c'est la plus grande question que j'ai encore à propos d'OpenLedger.
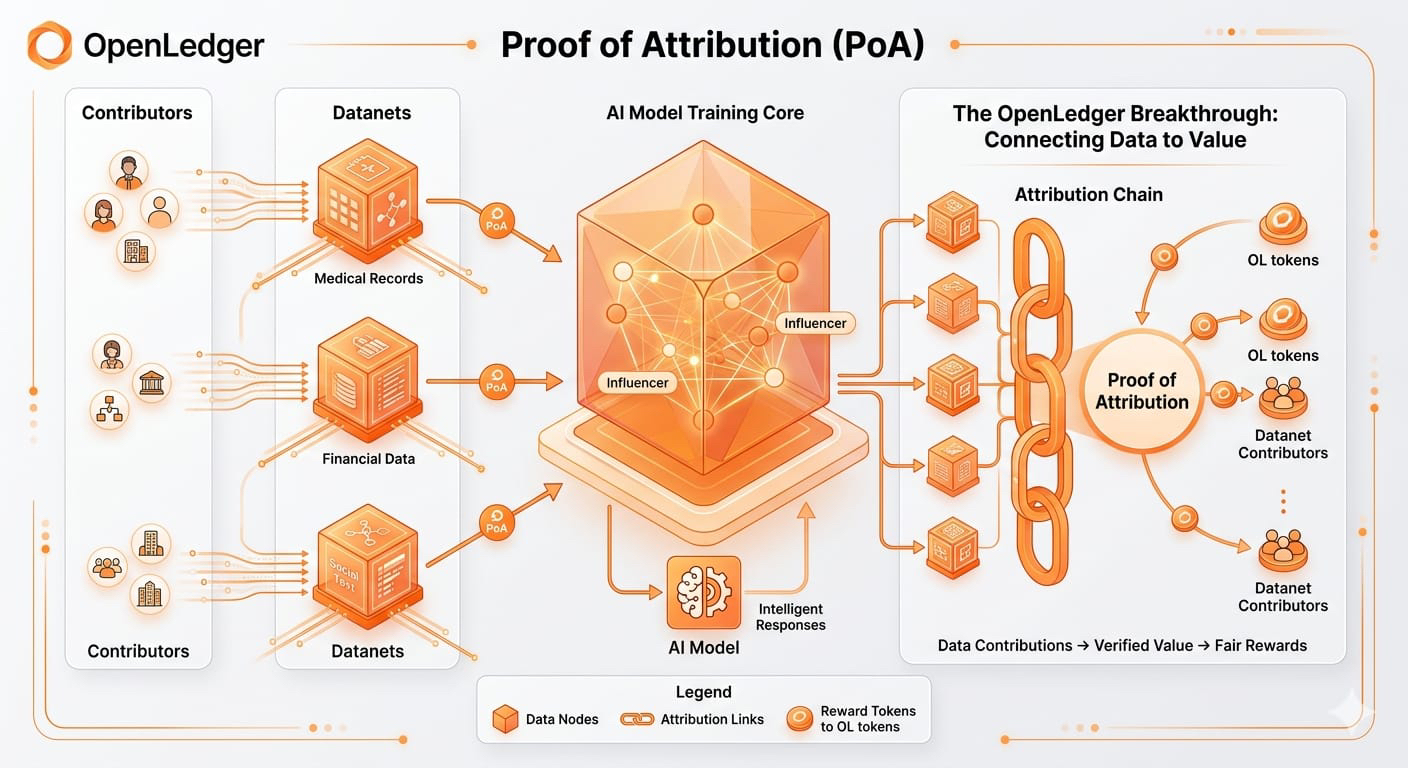
Le vrai problème n'est pas la propriété... c'est la qualité.
La blockchain est très bonne pour vérifier la propriété.
Ça peut suivre les transactions.
Ça peut automatiser les récompenses.
Ça peut créer de la transparence.
Mais la blockchain ne peut pas automatiquement déterminer si les données sont réellement utiles.
Et en IA, la qualité des données change tout.
Un modèle puissant formé sur des données faibles peut produire des résultats terribles.
En même temps, même un ensemble de données relativement petit mais de haute qualité peut améliorer considérablement la performance du modèle.
C'est pourquoi des entreprises comme OpenAI, Anthropic et DeepMind dépensent d'énormes sommes d'argent sur :
nettoyage des données
réduction de biais
filtrage
dé-duplication
évaluation de la sécurité
prévention des hallucinations
Ce processus est coûteux, lent et hautement centralisé.
OpenLedger essaie de décentraliser des parties de ce système à travers des mécanismes de réputation, des scores de validation, des modèles de staking et l'attribution des contributions.
Mais je pense toujours que la question la plus difficile
Qui décide si un ensemble de données est réellement précieux ?
Parce que la valeur des données IA n'est pas toujours évidente.
Certains ensembles de données semblent simples mais améliorent considérablement l'exactitude du modèle.
D'autres ont l'air professionnels mais n'ajoutent presque aucune réelle intelligence.
Et cela devient dangereux une fois que les incitations financières entrent dans le système.
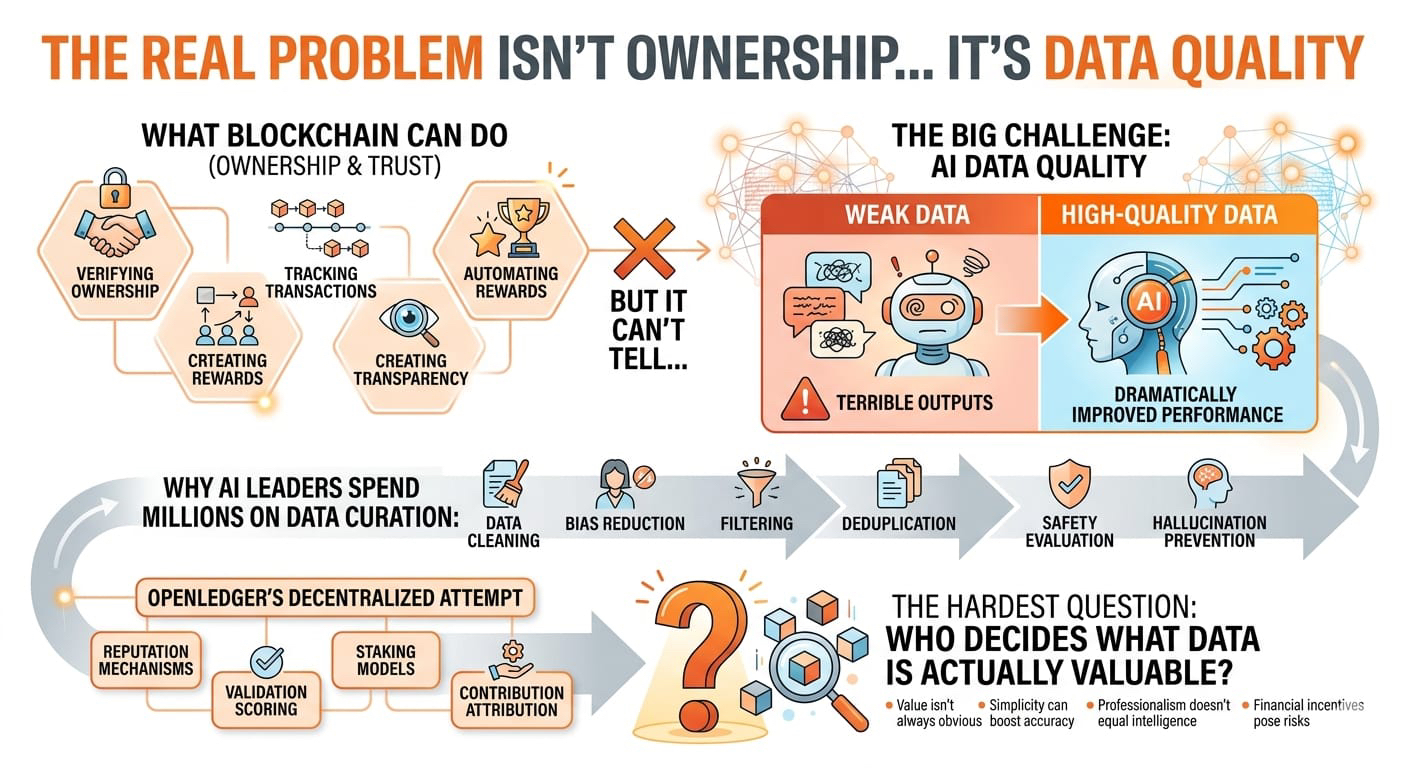
La crypto nous a déjà montré ce qui se passe avec les incitations.
Au moment où des récompenses existent, les gens optimisent pour les récompenses.
Nous avons déjà vu cela dans presque tous les secteurs de la crypto.
Le gaming play-to-earn est devenu du farming.
Les Airdrops sont devenus des chasses aux sybils.
Les plateformes de contenu sont devenues des machines à farming d'engagement.
Il existe donc naturellement le même risque pour les marchés de données IA.
Que se passe-t-il si des milliers d'utilisateurs commencent à télécharger des textes générés par IA de basse qualité simplement pour gagner des récompenses ?
Le marché pourrait rapidement être inondé de bruit synthétique.
Et contrairement au spam des réseaux sociaux, de mauvaises données d'entraînement IA peuvent réellement nuire à la performance des modèles.
Des ensembles de données faibles peuvent :
augmenter les hallucinations
amplifier le biais
réduire la fiabilité
déstabiliser les résultats
affaiblir les applications en aval
C'est pourquoi je pense que le succès à long terme d'OpenLedger dépend beaucoup plus du contrôle de la qualité que du prix du jeton.
Parce que si la couche de données sous-jacente devient faible, l'ensemble du cycle économique
Des données de basse qualité conduisent à des modèles plus faibles.
Des modèles faibles réduisent l'adoption.
Une adoption plus faible réduit les récompenses.
Et finalement l'écosystème perd de la valeur.
C'est la dure réalité des systèmes IA décentralisés.
Pourtant, il y a une chose que je respecte vraiment chez OpenLedger.
Ils se concentrent sur l'infrastructure plutôt que sur le pur battage.
La plupart des projets IA sur le marché crypto se vendent autour de promesses futures. OpenLedger essaie réellement de construire des systèmes autour de :
attribution des données
suivi de propriété
explicabilité
distribution transparente des récompenses
systèmes de contribution IA vérifiables
Ce ne sont pas des sujets flashy.
Mais ils sont extrêmement importants.
Surtout quand on considère où la régulation de l'IA se dirige à l'échelle mondiale.
La régulation pourrait tout changer.
En ce moment, les gouvernements du monde entier commencent à prêter beaucoup plus attention aux systèmes de formation IA.
Les questions autour des droits d'auteur, des licences, du consentement et de la légalité des ensembles de données deviennent de plus en plus importantes chaque année.
Les grandes entreprises IA font déjà face à des critiques concernant la façon dont les données d'entraînement sont collectées et utilisées.
Et honnêtement, cela pourrait devenir l'un des plus grands avantages d'OpenLedger à l'avenir.
Parce que si la régulation de l'IA exige finalement une transparence de la lignée des données, alors des systèmes comme la Preuve d'Attribution deviennent soudainement très précieux.
Être capable de prouver :
d'où viennent les données
qui l'a contribué
comment elles ont été utilisées
et qui devrait être récompensé
pourrait devenir une infrastructure critique pour des écosystèmes IA conformes.
C'est une narrative beaucoup plus grande que simplement être 'un autre jeton IA.'
Et je pense que c'est là qu'OpenLedger devient vraiment intéressant.
Pas parce que le succès est garanti.
Mais parce que le problème qu'il essaie de résoudre est réel.
Les Datanets pourraient être la partie la plus intelligente de tout le projet.
Une partie d'OpenLedger que j'aime vraiment est son focus sur les Datanets spécifiques au domaine.
Internet contient déjà d'énormes quantités de données d'entraînement génériques.
L'avantage futur en IA pourrait ne plus venir de qui a le plus grand modèle.
Cela peut venir de qui a la meilleure intelligence spécialisée.
L'IA dans la santé a besoin de données de qualité médicale.
L'IA financière a besoin d'ensembles de données financières structurées.
L'IA légale nécessite des cadres juridiques précis.
Le contenu général d'internet est déjà saturé.
Des données spécialisées de haute qualité sont là où la vraie valeur pourrait exister à l'avenir.
Et OpenLedger semble comprendre ça.
Si le projet peut construire avec succès des Datanets de niche de confiance avec un contrôle qualité fort, alors il pourrait finalement créer des effets de réseau puissants autour d'une infrastructure IA spécialisée.
Mais encore...
Tout revient à la même question :
Les systèmes décentralisés peuvent-ils maintenir de manière cohérente des données de haute qualité sans s'effondrer dans le spam motivé par les incitations ?
En ce moment, je ne pense pas que quelqu'un dans la crypto ait entièrement résolu ce problème.
Pas OpenLedger.
Pas Bittensor.
Pas n'importe quel marché IA décentralisé.
Et honnêtement, je pense que le premier projet qui résout vraiment ce problème pourrait devenir l'une des couches d'infrastructure IA les plus importantes dans le Web3.
Dernières réflexions
Personnellement, je ne suis pas encore complètement haussier sur OpenLedger.
Mais je fais définitivement attention maintenant.
Parce que contrairement à de nombreux projets IA qui dépendent entièrement des cycles de battage, OpenLedger essaie de résoudre quelque chose de fondamental.
Le projet essaie de construire une infrastructure économique autour des données IA elles-mêmes.
Et si l'IA devient le secteur technologique dominant de la prochaine décennie, alors la propriété des données, l'attribution et la transparence pourraient devenir des conversations de trillions de dollars.
L'opportunité est massive.
La difficulté d'exécution est encore plus grande.
Et à mon avis, l'avenir d'OpenLedger dépendra d'une chose avant tout :
Que les marchés IA décentralisés puissent récompenser la qualité sans être détruits par les incitations au spam.
Le jour où je verrai une réponse convaincante à cette question, je pourrais arrêter de voir OpenLedger comme juste un autre jeton IA.
Peut-être que cela devient alors une véritable infrastructure.