I've been in a weird headspace this week, the kind where the market is doing things but none of it feels meaningful, so I end up reading sideways instead of watching charts. I found myself going deep on AI data infrastructure — not the exciting consumer-facing stuff, just the boring underneath-layer that nobody talks about at conferences. And then I spent a few hours with OpenLedger, which I'd been putting off, and something about the angle they're working from kept scratching at me in a way I couldn't immediately name.
The angle is standards. Specifically, transparent standards for how AI data gets contributed, verified, attributed. And I thought, yeah, that's clearly necessary, of course that should exist. Obvious good. I moved past it quickly.
Then I circled back and the thing that was bothering me finally landed.
Transparent and standardized are not the same thing. And I think most of the conversation around $OPEN is treating them as if they are.
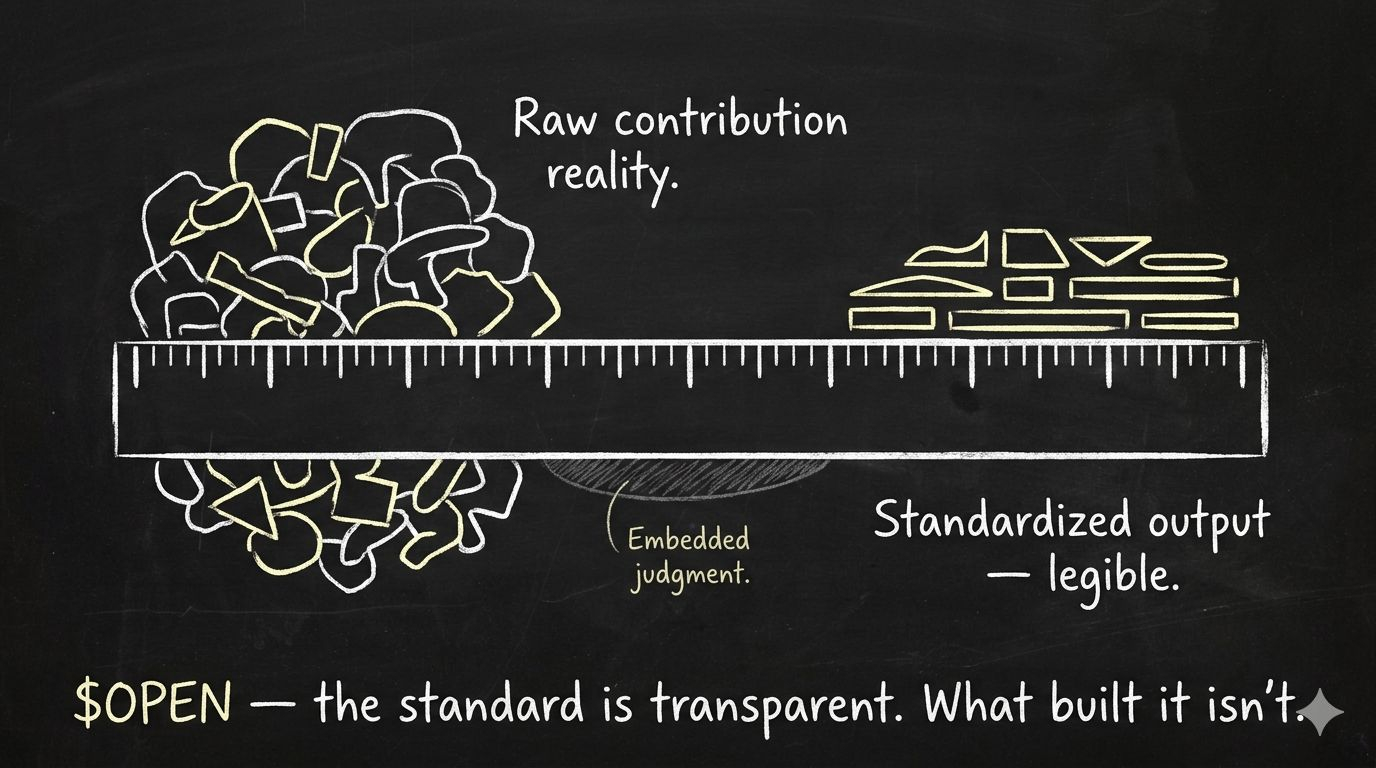
Here's what I mean. A standard, by definition, compresses. It takes complicated, varied, contextual inputs — in this case, human-generated data contributions of wildly different types, quality levels, contexts, and purposes — and reduces them to a common format that can be measured, compared, and traded. That reduction is the entire point. Without it you can't have a market, can't have verification, can't have attribution. The compression is what makes the thing work.
But the compression also hides things. Every standard embeds judgment about what to include and what to drop, what counts as quality and what doesn't, which context is relevant and which gets stripped away. Once the standard exists and people start operating within it, those judgment calls become invisible. You see the output — the labeled, verified, attributed data contribution — but you don't see the dozens of choices that went into how the standard decided to measure it.
That's the accounting problem. GAAP is transparent — every public company uses the same rules, anyone can read the filings. But GAAP is also the most argued-over, lobbied-over, politically contested system in finance, because the standard gives enormous discretion inside the rules, and companies and their auditors use that discretion constantly. The transparency is real. The judgment inside the transparent system is invisible.
When I was going through how #OpenLedger structures its contribution standards — specifically the layer where data gets attributed and quality gets assessed — what struck me wasn't that the system is opaque. It's that the system will eventually be legible while remaining not fully transparent, and those are different things that sound the same.
But here's the part that genuinely bothers me.
Whoever sets the initial standard doesn't just set the rules for today. They set the reference point that everything after gets measured against. If @OpenLedger establishes the dominant framework for AI data contribution standards, they're not just building infrastructure. They're making a series of consequential judgment calls — about what quality means, what attribution means, what verifiability requires — that will become essentially invisible once the standard is adopted and assumed. The standard will be cited as neutral because it's consistent. The values embedded in it won't get revisited.
I've watched this happen in other industries. Credit rating methodologies. Environmental accounting frameworks. Nutritional labeling standards. In every case, the initial framers had enormous influence on what the market ended up optimizing for — not because they were malicious, but because once you build the measuring stick, everything gets measured against it and the measuring stick stops getting questioned.
This doesn't make what $OPEN is building wrong. Actually the opposite — building a standard is one of the most impactful things you can do in an emerging market. The concern is whether the standard-building process itself is as transparent as the standard it produces, and whether there's a genuine mechanism for revising the framework as the understanding of what "quality AI data" actually means continues to evolve.
I haven't found a clear answer to that in how OpenLedger presents itself. Maybe it exists somewhere in the governance layer I haven't fully dug into yet.
Anyway, the charts recovered a little this afternoon and I stopped reading things. I'll probably come back to this when there's more to actually look at in terms of how the standards get applied in practice.