La course moderne à l'intelligence artificielle fait face à un goulot d'étranglement critique, souvent non dit : l'approvisionnement en données de haute qualité et spécifiques au domaine. Alors que des géants de la tech valant des trillions construisent des modèles de langage avancés (LLMs) entraînés sur des données publiques d'internet, les créateurs individuels, les experts du domaine et les communautés qui ont initialement produit ces données ne reçoivent aucun crédit, aucune compensation et aucun contrôle sur l'utilisation de leur propriété intellectuelle.
C'est ici que @OpenLedger entre en jeu pour redéfinir fondamentalement l'économie de l'intelligence artificielle. En construisant le premier "AI Blockchain," @OpenLedger pionnier une infrastructure de confiance décentralisée conçue pour monétiser les données, les modèles et les agents AI sur la chaîne.
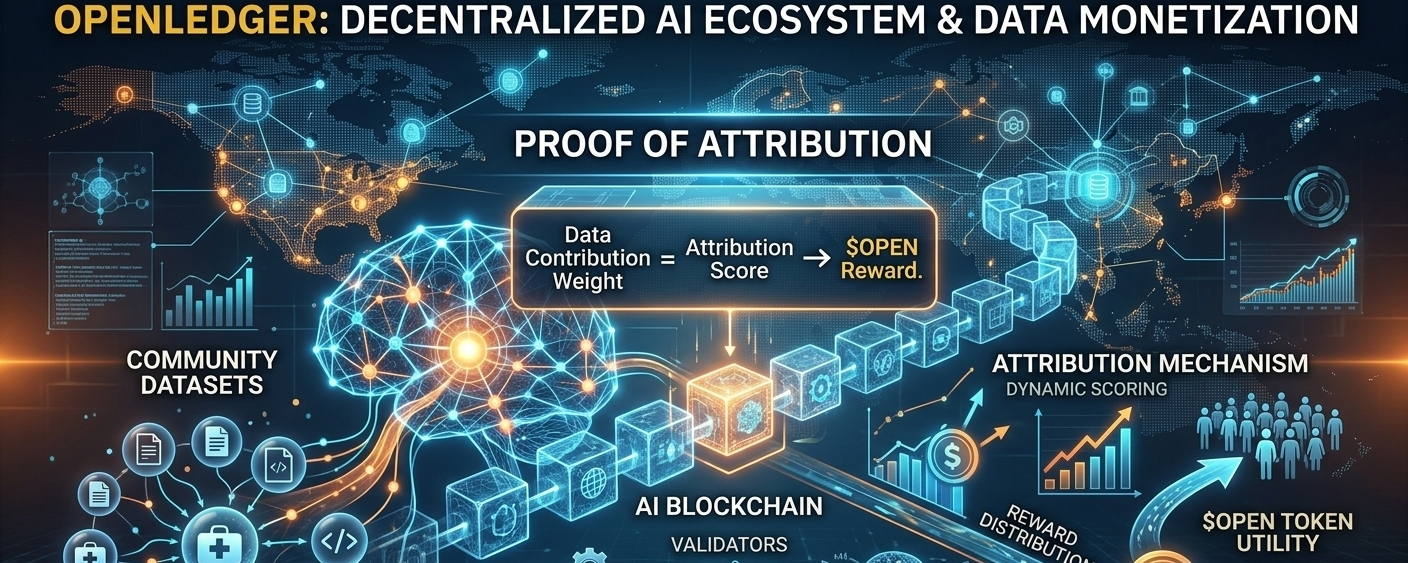
Le Changement de Jeu : Qu'est-ce que la "Proof of Attribution" ?
Pour que l'IA décentralisée réussisse, nous devons dépasser les simples pools de partage de données. Nous avons besoin d'un moyen de prouver exactement combien une pièce de données spécifique a contribué à la sortie d'un modèle IA. @OpenLedger accomplit cela grâce à son mécanisme révolutionnaire de Proof of Attribution.
Au lieu de traiter les données comme un fichier statique qui est acheté une fois et oublié, la Proof of Attribution transforme les données en un actif dynamique sur la blockchain. Ce mécanisme fonctionne sur deux couches principales :
Influence au niveau des fonctionnalités : Pour des modèles plus petits et hautement spécialisés, le système mesure cryptographiquement comment l'ajout ou la suppression d'un point de données spécifique affecte la perte d'entraînement.
Provenance au niveau du token : Pour les grands modèles de langage, les sorties sont comparées à des représentations compressées du corpus d'entraînement afin d'identifier les segments de données mémorisés.
En termes simples, chaque fois qu'un modèle IA exécute une inférence, le moteur on-chain d'@OpenLedger calcule le poids de contribution des données sous-jacentes. Si vos données étaient le facteur clé dans une décision cruciale, votre score d'attribution augmente, se traduisant directement par des récompenses en temps réel sur la blockchain.
Propulsé par des "DataNets" spécialisés
Plutôt que de se concentrer sur des ensembles de données massifs et génériques qui conduisent à des "hallucinations" en IA, @OpenLedger introduit les DataNets. Ce sont des ensembles de données modulaires, pilotés par la communauté, spécifiques à un domaine, adaptés à des niches hautement spécialisées—comme les transcriptions médicales, les contrats juridiques, ou le code développeur précis.
Parce que ces ensembles de données sont structurés sur la blockchain, ils créent une traçabilité vérifiable et auditable. Les développeurs peuvent retracer le comportement des modèles directement à leur source, résolvant le problème de la boîte noire de l'IA moderne et offrant un niveau d'explicabilité que les modèles web2 traditionnels ne peuvent tout simplement pas égaler.
Le Moteur Économique : Le $OPEN Token
Au cœur de cette économie IA décentralisée se trouve le token utilitaire et de gouvernance natif, $OPEN. Il agit comme le tissu conjonctif financier à travers le réseau :
Incitations & Récompenses : Les contributeurs de données de haute qualité, les validateurs et les développeurs IA sont payés dynamiquement en : $OPEN en fonction de l'impact mesuré de leurs données.
Gaz du Réseau : $OPEN sert de token de gaz natif pour le traitement des transactions sur le réseau Layer 2 d'OpenLedger, garantissant des micro-règlements fluides et rentables pour les inférences IA à haute fréquence.
Agent Staking : Pour garantir la responsabilité en termes de performance, les agents IA opérant sur le réseau doivent staker $OPEN, qui peut être slashed s'ils sous-performent ou s'engagent dans un comportement malveillant.
Pensées Finales
En réduisant la granularité de l'attribution à la couche d'inférence, OpenLedger s'attaque au problème de "cold start" de l'approvisionnement en données IA décentralisées. Cela aligne parfaitement les incitations : les contributeurs de données sont incités à fournir des données de haute qualité pour maximiser leurs scores d'influence, tandis que les développeurs IA ont accès à des ensembles de données premium et conformes.
Gardez un œil attentif sur cet écosystème alors que le récit de l'IA décentralisée continue de mûrir !
Quels sont vos avis sur la Proof of Attribution ? Discutons-en dans les commentaires ! 👇

