Je pensais que les agents IA autonomes seraient principalement évalués sur la qualité brute de leur output. Je pensais que tant que la tâche était réalisée, que le trade était réglé ou que la recommandation fonctionnait, le boulot était fait. Ça semblait assez évident, mais dernièrement, je ne suis pas sûr que ce soit même le bon niveau à considérer maintenant.
Au moment où ces agents commencent à toucher au capital, aux APIs, aux contrats ou même les uns aux autres, la sortie cesse d'être la seule chose qui compte, car l'histoire commence à prendre le devant de la scène.
Ce n'est pas seulement une question d'historique de transactions simples. Nous parlons d'historique comportemental et de fiabilité sous des conditions changeantes et des motifs d'erreurs spécifiques. Je regarde comment ces machines gèrent la discipline des permissions ou la récupération après un échec.
Que l'agent ait fait quelque chose de mal une fois est presque moins important que de savoir si le système environnant peut rendre cette erreur lisible pour que quelqu'un d'autre la voie plus tard. C'est là que le Grand Livre commence à ressembler moins à une infrastructure standard et plus à quelque chose de beaucoup plus étrange.
On dirait beaucoup une agence de crédit. Je sais que cette comparaison semble un peu plus propre qu'elle ne l'est en réalité. Une agence de crédit ne décide pas si vous êtes digne de confiance dans un sens philosophique, mais elle compresse plutôt des fragments de comportement antérieur en un signal utilisable. Les prêteurs consomment ce signal parce que reconstruire votre passé entier à chaque fois est tout simplement trop coûteux.
Le score devient un substitut parfait pour le travail désordonné de véritable enquête.
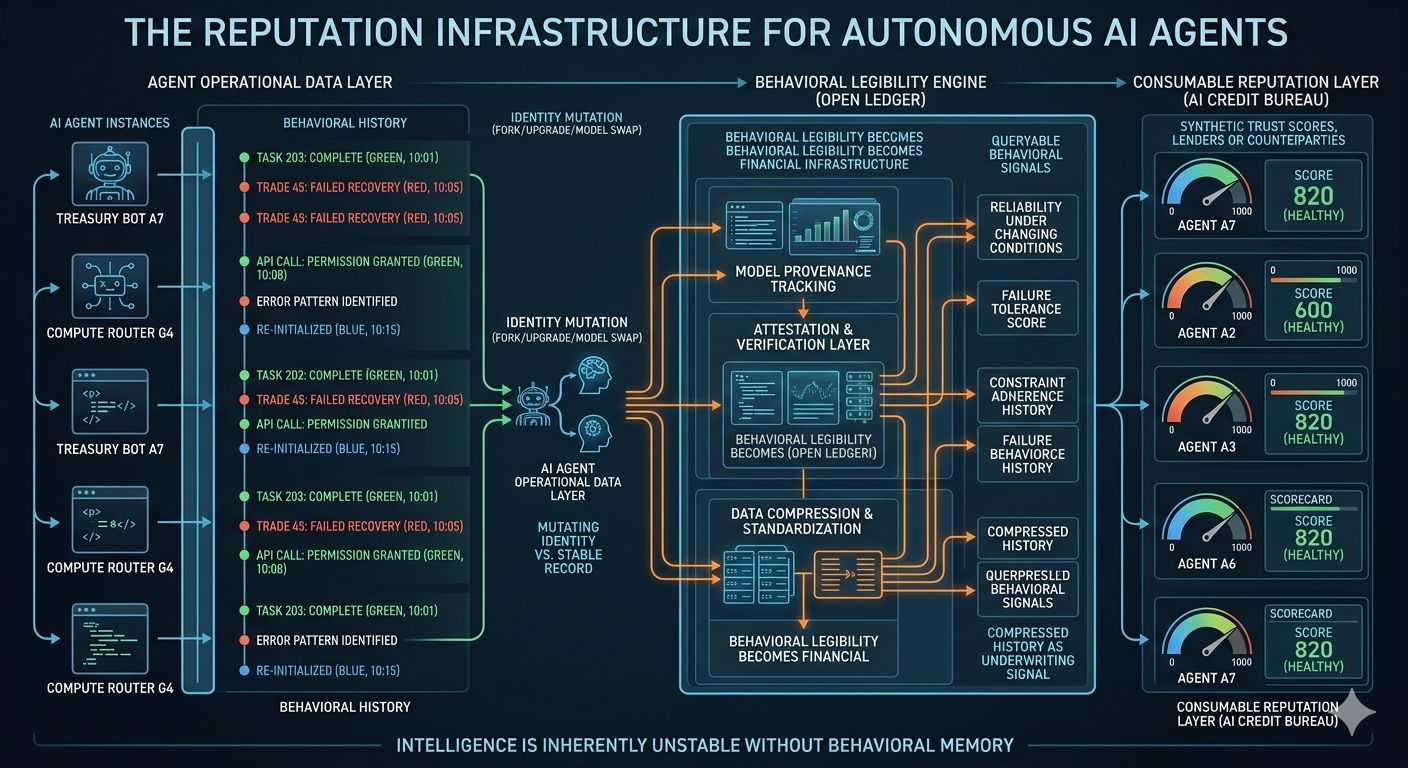
Cette différence semble petite quand tu le dis vite, mais ce n'est pas le cas. Les agents autonomes créent un énorme problème de coordination, car si un agent exécute un rééquilibrage de trésorerie ou négocie des prix de services ou dirige la demande de calcul, que doit exactement évaluer la contrepartie ? Cela pourrait être de l'intelligence, mais l'intelligence sans mémoire comportementale est intrinsèquement instable.
Un agent brillant qui enfreint parfois des contraintes ou ignore des frontières devient difficile à évaluer et, bien qu'il ne soit pas inutilisable, il est définitivement coûteux à faire confiance.
Le système décide de ce qu'il a le droit de voir et cette ligne me dérange toujours. Un système de crédit ne concerne pas vraiment la vérité mais plutôt les résidus visibles de comportements qui ont survécu à suffisamment de standardisation pour devenir consommables par les systèmes en aval.
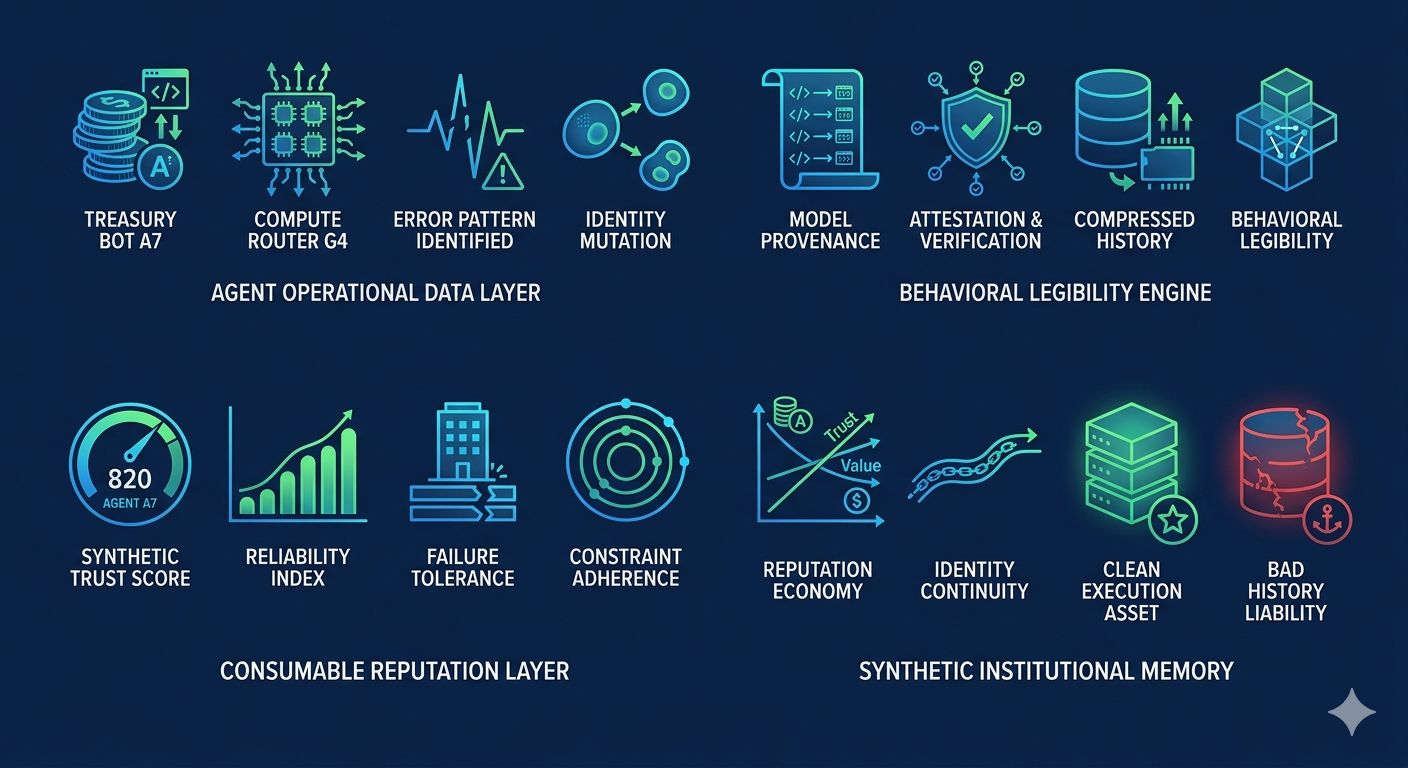
Cela compte plus pour l'IA que les gens ne l'admettent, car les humains ont des identités légales et des structures institutionnelles tandis que les agents IA ne viennent pas avec cette structure. Si le Grand Livre construit des couches d'attestation autour de la provenance des modèles et des preuves de comportement, alors le produit plus profond n'est pas seulement l'attribution mais la lisibilité comportementale.
La lisibilité comportementale devient très rapidement une infrastructure financière. Imagine deux agents autonomes demandant accès à la même réserve de capital où l'un a des milliers de tâches antérieures avec des frontières traçables et des modèles d'échec connus, tandis que l'autre prétend avoir une intelligence plus forte mais a des preuves opérationnelles plus minces.
La plupart des systèmes financiers prennent déjà des décisions de cette manière en consommant une histoire compressée plutôt qu'en comprenant l'ensemble de l'entité. C'est essentiellement de la souscription.
Je reste coincé sur un malaise structurel, car les agences de crédit fonctionnent parce que l'identité humaine reste relativement cohérente dans le temps. Un agent autonome pourrait ne pas l'être. Que se passe-t-il lorsque les agents se forkent, mettent à jour ou échangent des modèles ou changent de couches de contrôle ?
À quel moment ce n'est plus le même agent ? Cette question est plus importante que le score lui-même, car si l'objet d'identité sous-jacent au dossier continue de muter, alors qu'est-ce qui est exactement digne de confiance ?
L'objet est stable tandis que la conséquence ne l'est pas. Ou peut-être que la conséquence est traitée comme stable même lorsque l'objet a changé, et cela semble dangereux. Un protocole en aval pourrait voir un historique attesté soigné et supposer une continuité où il n'en existe en réalité aucune.
Le Grand Livre peut probablement améliorer la visibilité, mais je suis moins sûr qu'il puisse résoudre le problème de continuité. Peut-être que ce n'est pas une critique, car les systèmes d'infrastructure sont toujours incomplets de cette manière.
Un créateur est classé en ligne parce que certains signaux comme l'engagement ou la cohérence survivent au filtre, mais le travail invisible disparaît toujours. Le score consomme le résidu. Le risque avec les agents IA est qu'une fois qu'un score de confiance devient utilisable, les gens cesseront de se demander ce qui a été rejeté. La plupart de la complexité interne, comme l'évolution des invites ou les branches de raisonnement échouées, ne sera jamais suffisamment lisible pour une consommation en temps réel.
Le Grand Livre pourrait devenir une partie de cette couche de compression, non pas parce qu'il prouve la vérité, mais parce qu'il rend le comportement antérieur suffisamment interrogeable pour que les systèmes puissent prétendre avoir effectué une diligence raisonnable.
Si la réputation comportementale devient économiquement significative, alors des marchés secondaires autour de la confiance elle-même émergeront probablement. Un historique d'exécution propre deviendra un actif tandis qu'un mauvais historique deviendra une responsabilité. C'est à ce moment-là que cela cesse de ressembler à une infrastructure de provenance simple et commence à ressembler à une mémoire institutionnelle synthétique. Le choix de conception caché n'est pas de savoir si les agents ont besoin de réputation, mais combien de complexité comportementale est rejetée avant que cette réputation ne devienne suffisamment lisible pour être consommée.
Je ne pense tout simplement pas que nous ayons encore admis que l'IA autonome pourrait avoir besoin d'une couche d'identité financière bien avant qu'elle n'ait besoin d'une meilleure intelligence.