La plupart des gens évaluent les services d'IA à partir de la couche superficielle vers l'extérieur.
La réponse est-elle arrivée rapidement ? La sortie semblait-elle convaincante ? Le flux de travail s'est-il terminé sans échec évident ? Si les trois se produisent, l'infrastructure sous-jacente disparaît généralement complètement de la conversation.
Mais plus l'IA commence à gérer des décisions économiques, l'exécution automatisée et l'activité on-chain, moins cette évaluation superficielle semble convaincante en elle-même.
Parce qu'une sortie bien polie n'est pas nécessairement la preuve que le processus sous-jacent était responsable.
C'est pourquoi la collaboration d'OpenLedger avec DGrid a retenu mon attention différemment des autres annonces d'infrastructure AI.
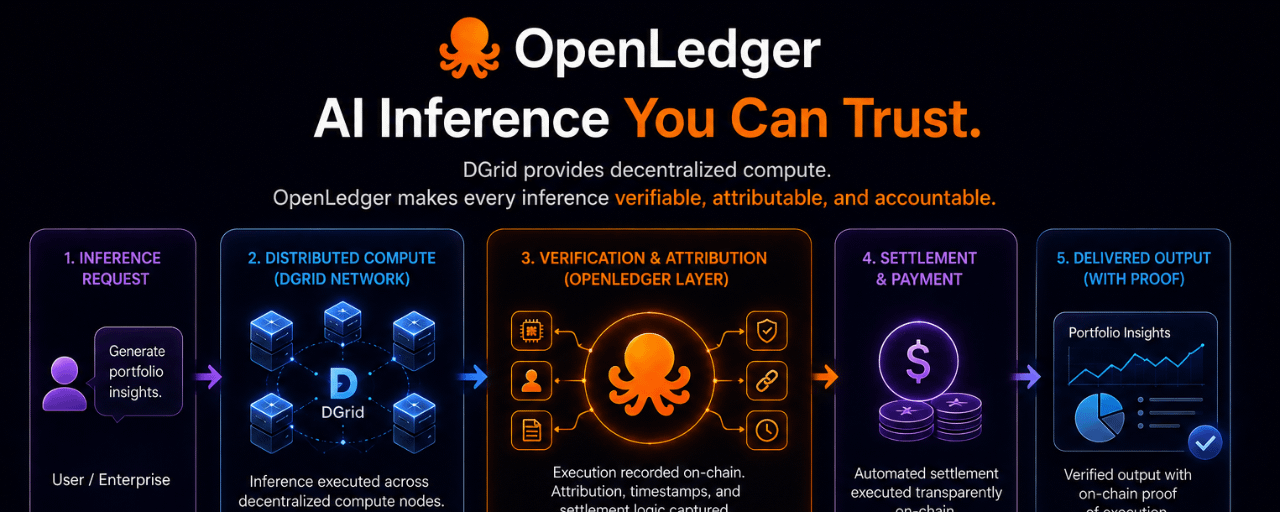
DGrid distribue les charges de travail d'inférence AI à travers un réseau de calcul décentralisé. Sur le papier, cela semble déjà utile. Au lieu de dépendre d'un seul fournisseur centralisé, le travail d'inférence est distribué entre plusieurs participants au calcul.
Mais honnêtement, la décentralisation seule ne résout pas grand-chose si l'acheteur ne peut toujours pas vérifier de manière significative ce qui s'est passé après que le résultat soit revenu.
Une boîte noire distribuée reste une boîte noire.
La partie intéressante est là où OpenLedger entre dans le flux.
Le réseau se positionne comme la couche de coordination et d'attribution autour du processus d'inférence lui-même. Les enregistrements d'exécution, la logique de règlement et l'attribution sont destinés à rester visibles sur la chaîne aux côtés de la demande d'inférence au lieu d'être séparés dans des systèmes de comptabilité backend invisibles que tout utilisateur normal ne peut pas inspecter.
Cela change complètement la structure de confiance.
Normalement, une entreprise qui achète l'inférence AI reçoit deux choses séparément : la sortie elle-même et une facture prouvant que le calcul a eu lieu quelque part. Tout ce qui se passe entre ces deux points nécessite généralement la confiance dans le fournisseur qui a opéré l'infrastructure.
OpenLedger semble pousser vers un modèle différent où l'événement d'inférence, le chemin de règlement et l'enregistrement d'exécution restent connectés à l'intérieur du même environnement vérifiable.
Et honnêtement, je pense que cela compte beaucoup plus pour les systèmes AI à enjeux élevés que la plupart des gens ne le réalisent encore.
Si l'IA commence à participer aux flux de travail financiers, aux systèmes juridiques, aux agents autonomes ou à la coordination des soins de santé, alors la sortie seule n'est plus suffisante. L'acheteur doit finalement comprendre si le processus derrière cette sortie était fiable, attribuable et économiquement responsable.
Pas parce que chaque utilisateur va auditer manuellement les enregistrements blockchain eux-mêmes.
La plupart ne le feront pas.
Mais parce que l'infrastructure qui préserve ces enregistrements crée la possibilité de responsabilité quand quelque chose tourne mal plus tard.
Cette distinction semble importante.
Beaucoup de récits autour de l'IA parlent de transparence de manière très vague. L'approche d'OpenLedger semble plus étroite et plus opérationnelle que cela. Le système ne cherche pas à rendre l'IA magiquement compréhensible à chaque niveau. Il essaie de rendre la trace d'exécution autour de l'activité AI suffisamment lisible pour que les acheteurs ne soient pas forcés de faire confiance à une coordination invisible entre des systèmes déconnectés.
C'est un problème d'infrastructure beaucoup plus réaliste à résoudre.
Et honnêtement, probablement un problème commercialement plus précieux aussi.
Le défi plus difficile à partir de maintenant est l'utilisabilité. Les enregistrements d'exécution sur la chaîne n'importent que si les entreprises et les développeurs peuvent réellement les interpréter sans avoir besoin d'une équipe d'infrastructure spécialisée chaque fois qu'une décision doit être examinée.
Si la responsabilité existe techniquement mais reste inaccessible opérationnellement, alors la plupart des acheteurs continueront à compter sur la confiance de toute façon.
Pourtant, la direction vers laquelle OpenLedger se dirige semble importante car elle traite l'inférence non pas comme une sortie isolée mais comme un processus qui devrait rester économiquement et opérationnellement traçable de la demande à la liquidation.
C'est une philosophie très différente de "fais juste confiance à la réponse AI parce qu'elle semble correcte."
Et plus les systèmes AI deviennent grands, plus je pense que les acheteurs finiront par se soucier du processus presque autant que du résultat lui-même.