
AI has become very good at showing the final answer.
A clean response appears.
An image gets generated.
An agent completes a task.
A model gives useful output in seconds.
But one thing is still missing.
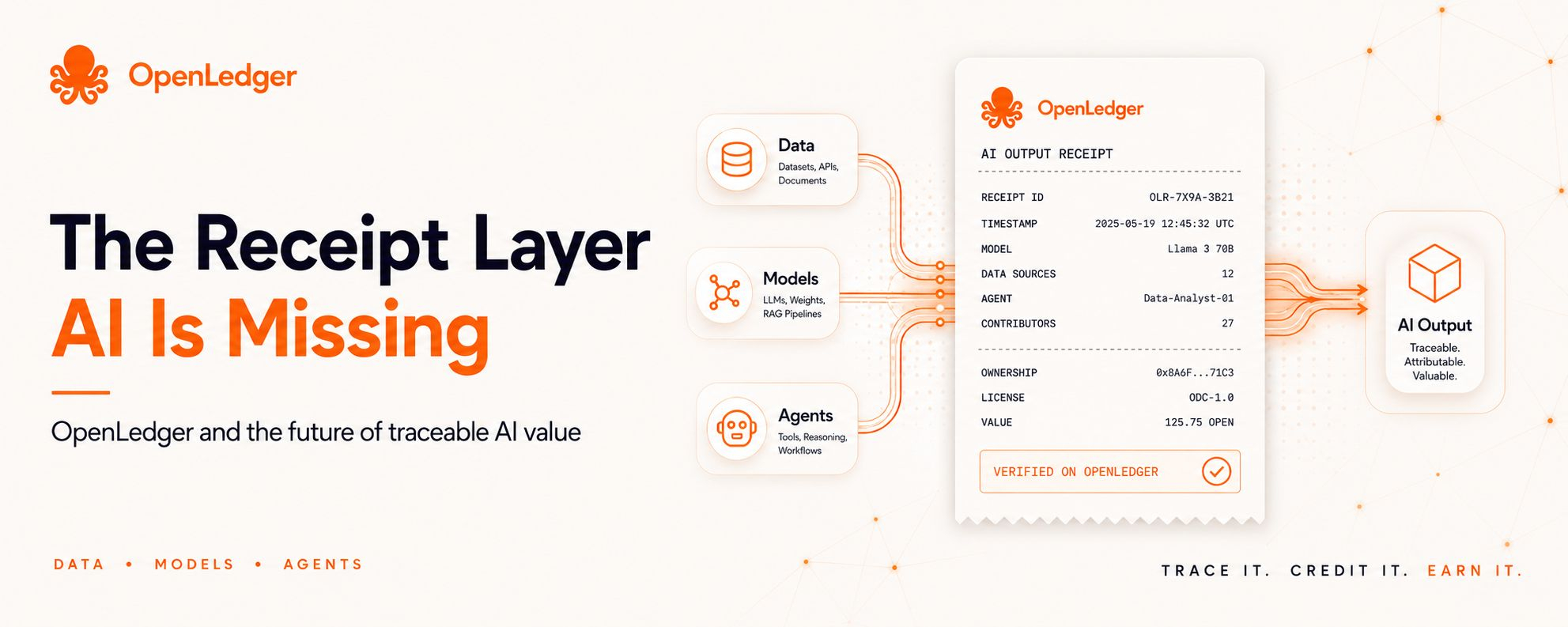
The receipt behind that output.
In normal digital life, almost every serious action leaves a record. A payment has a transaction ID. A trade has an order history. An onchain transfer has a hash. These records matter because they show what happened, where value moved, and who was involved.
AI does not work like that yet.
A user sees the final answer, but the path behind that answer is often unclear. Which data made it better? Which model shaped the result? Which agent handled the task? Which contributor added value in the background?
This is not just a technical question. It is an economic one.
If AI keeps becoming part of apps, trading systems, research tools, agents, and daily workflows, then the value behind AI needs stronger records. Otherwise, the final output gets all the attention while the contributors behind it stay invisible.
That is where OpenLedger becomes interesting.
OpenLedger is not only trying to attach blockchain to AI for a trend. Its core idea is closer to building rails for AI-native assets: data, models, applications, and agents. The project’s official positioning is about unlocking liquidity to monetize data, models, and agents, while its docs describe infrastructure for training and deploying specialized models using community-owned datasets.
This matters because AI assets are not always easy to value.
A dataset can be extremely useful, but hard to price.
A model can create value, but its real inputs may be hidden.
An agent can complete work, but the source of its performance may be unclear.
Without attribution, these assets stay blurry.
And blurry value is hard to monetize.
That is why I like the “receipt layer” idea for understanding OpenLedger. A receipt does not just prove that something happened. It connects action with source. It gives value a trail.
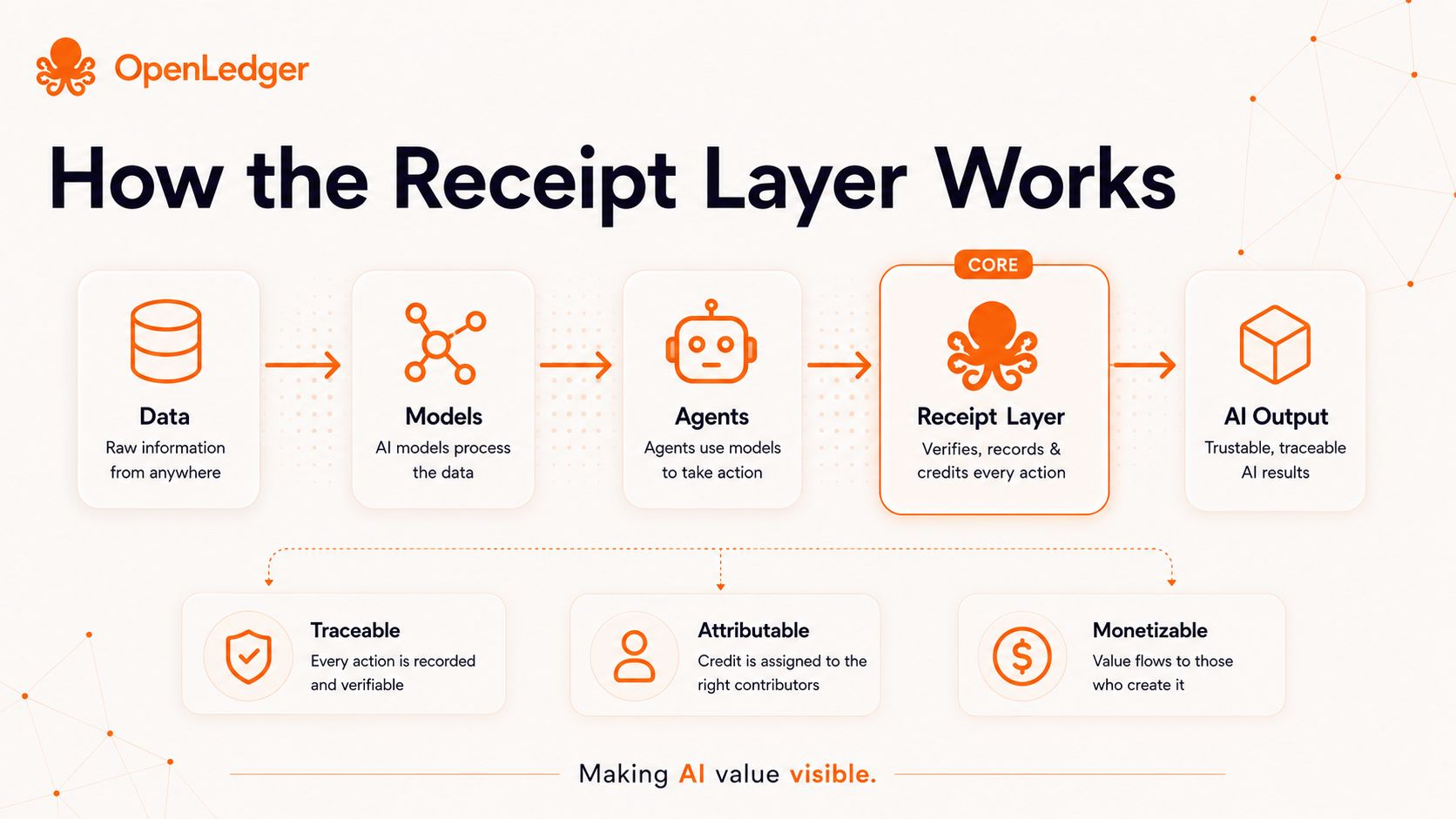
For AI, that trail can become important.
If a dataset improves a model, there should be a clearer record.
If a model powers an app, usage should not disappear silently.
If an agent creates value, the system should be able to show what helped create that value.
This is where OpenLedger’s focus on attribution, data, models, and agents feels relevant. It is trying to make the hidden parts of AI more visible, measurable, and rewardable.
But this is not a guaranteed story.
Execution still matters. OpenLedger needs useful datasets, real builders, quality models, active agents, and demand from users. If these pieces do not grow, the idea can stay theoretical. In AI infrastructure, a strong narrative is not enough. The network has to become useful.
Still, the direction makes sense.
AI is moving from simple outputs into real economic activity. Agents will not only answer questions. They may trade, research, automate tasks, manage workflows, and interact with apps.
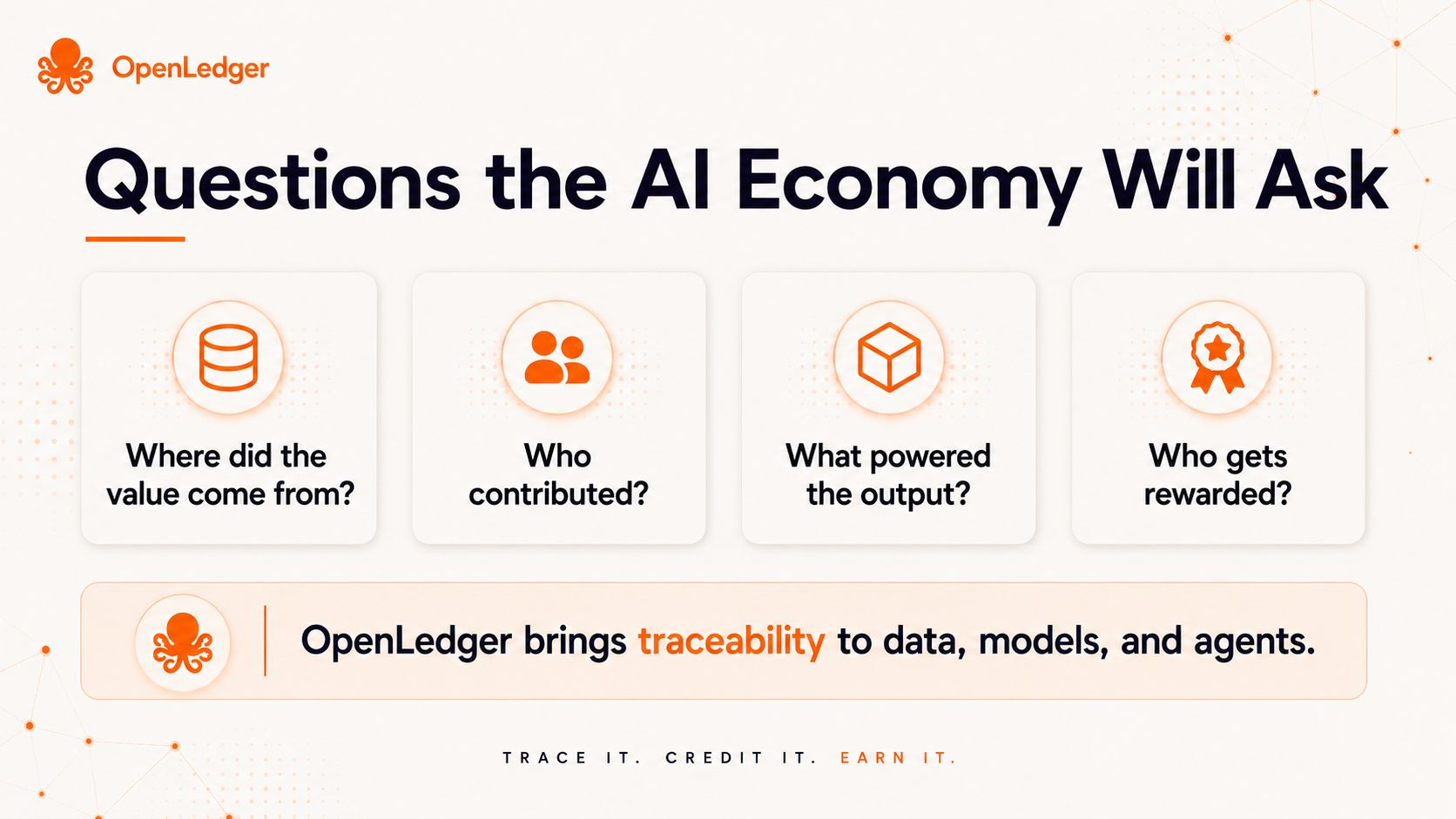
When that happens, the market will ask better questions.
Not only:
How smart is this AI?
But also:
Where did its value come from?
Who contributed to it?
Who should be rewarded?
Can that value be tracked?
OpenLedger is interesting because it is trying to answer those questions onchain.
AI already knows how to produce outputs.
Now it needs a better way to show the receipt behind those outputs.
That is the OpenLedger angle I think more people will understand with time.