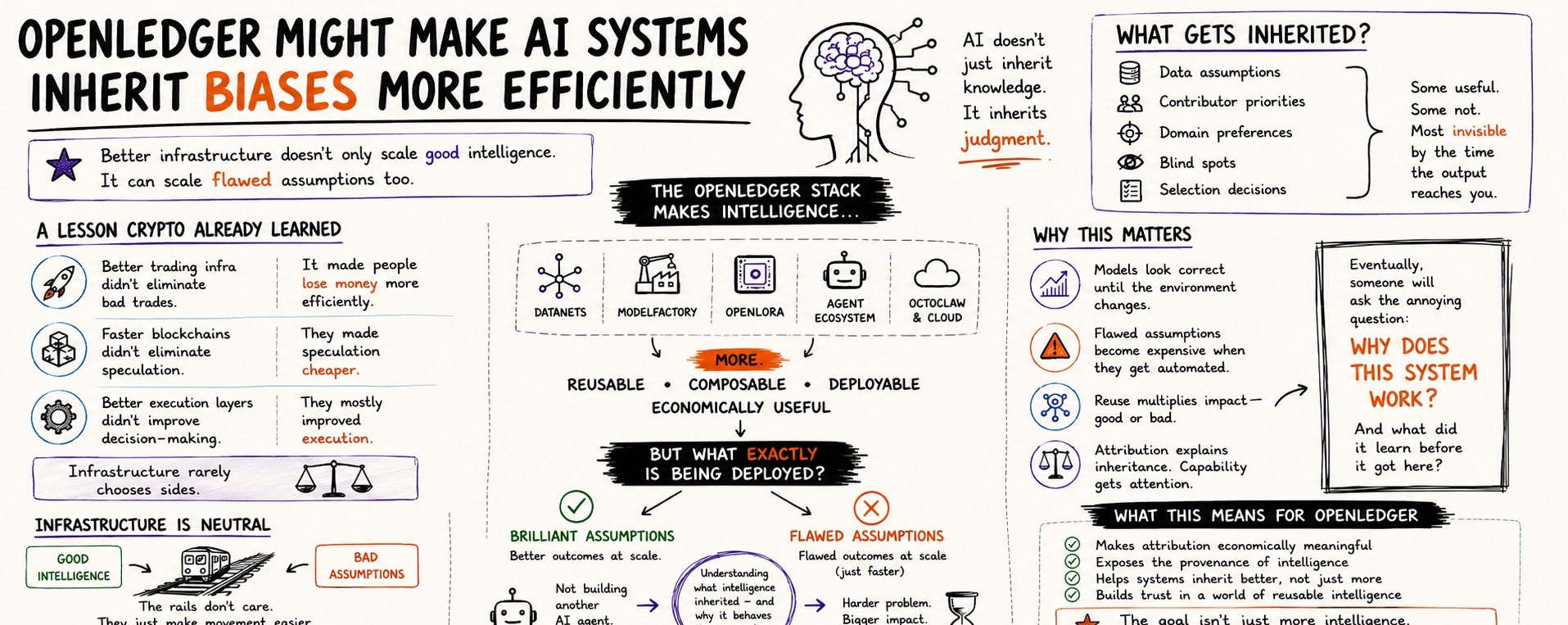
Une chose que je trouve drôle sur les marchés d'infrastructure, c'est que les gens supposent automatiquement que de meilleures infrastructures signifient de meilleurs résultats.
Parfois, ça le fait.
Parfois, ça fait juste que le comportement existant évolue plus vite.
La crypto a appris cette leçon il y a des années. Une meilleure infrastructure de trading n'a pas éliminé les mauvaises transactions. Ça a juste fait perdre de l'argent aux gens plus efficacement. Des blockchains plus rapides n'ont pas éliminé la spéculation. Elles ont rendu la spéculation moins chère. De meilleures couches d'exécution n'ont pas magiquement amélioré la prise de décision. Elles ont surtout amélioré l'exécution.
La même pensée me revient à l'esprit quand je regarde OpenLedger.
Parce qu'une grande partie de la conversation se concentre sur ce que l'infrastructure permet.
Datanets.
ModelFactory.
OpenLoRA.
Agents de trading.
Couches de déploiement.
D'accord.
La pile devient plus facile à utiliser.
Mais un déploiement plus facile soulève une question différente.
Qu'est-ce qui est exactement déployé ?
Cela semble évident jusqu'à ce que vous pensiez à la façon dont l'intelligence est réellement construite.
Aucun modèle n'apparaît de nulle part.
Il hérite de choses.
Assumptions de données.
Priorités des contributeurs.
Préférences de domaine.
Angles morts.
Décisions de sélection.
Certaines de ces choses sont utiles.
Certains ne le sont pas.
La plupart sont invisibles au moment où le résultat final atteint un utilisateur.
C'est pourquoi je pense que les gens simplifient parfois trop la conversation sur l'IA.
Un modèle n'hérite pas seulement de connaissances.
Il hérite du jugement.
Ou du moins sa version de jugement.
Un système de trading entraîné autour de certaines conditions de marché peut hériter silencieusement de la confiance dans des environnements où elle n'est plus méritée.
Un modèle de recherche peut hériter de préférences sources qui semblent complètement raisonnables jusqu'à ce qu'elles ne le soient plus.
Un agent spécialisé peut hériter d'assumptions si profondément que personne ne les remarque plus parce que les résultats continuent de sembler corrects.
C'est la partie inconfortable.
Plus le résultat semble bon, plus il devient difficile d'inspecter ce qui l'a produit.
Et OpenLedger se situe directement dans cette tension.
Parce que l'infrastructure rend l'intelligence plus réutilisable.
Plus composable.
Plus déployable.
Plus économiquement utile.
Tout cela est positif.
Mais l'infrastructure est généralement neutre.
Les rails se moquent de savoir si la chose qui se déplace dessus est brillante ou défaillante.
Ils rendent simplement le mouvement plus facile.
La crypto comprend cela instinctivement.
La liquidité peut soutenir de bons actifs et de terribles.
Le levier peut amplifier des idées fortes et désastreuses.
La distribution peut diffuser des signaux et des absurdités en même temps.
L'infrastructure choisit rarement des côtés.
L'IA suit probablement le même schéma.
C'est en partie pourquoi je trouve l'attribution plus intéressante que la capacité.
La capacité attire l'attention.
L'attribution explique l'héritage.
Et l'héritage devient important une fois que l'intelligence commence à être réutilisée à travers plusieurs systèmes, contributeurs, agents et environnements économiques.
Parce qu'éventuellement, quelqu'un pose la question ennuyeuse.
Pas si le système fonctionne.
Mais pourquoi cela fonctionne.
Et plus important encore...
Ce qu'il a exactement appris avant d'arriver ici.
Cela semble être un problème beaucoup plus difficile que de construire un autre agent IA.
On dirait aussi que c'est le genre de problème qui ne devient visible qu'après le succès de l'infrastructure.
C'est généralement à ce moment-là que les choses deviennent intéressantes.
