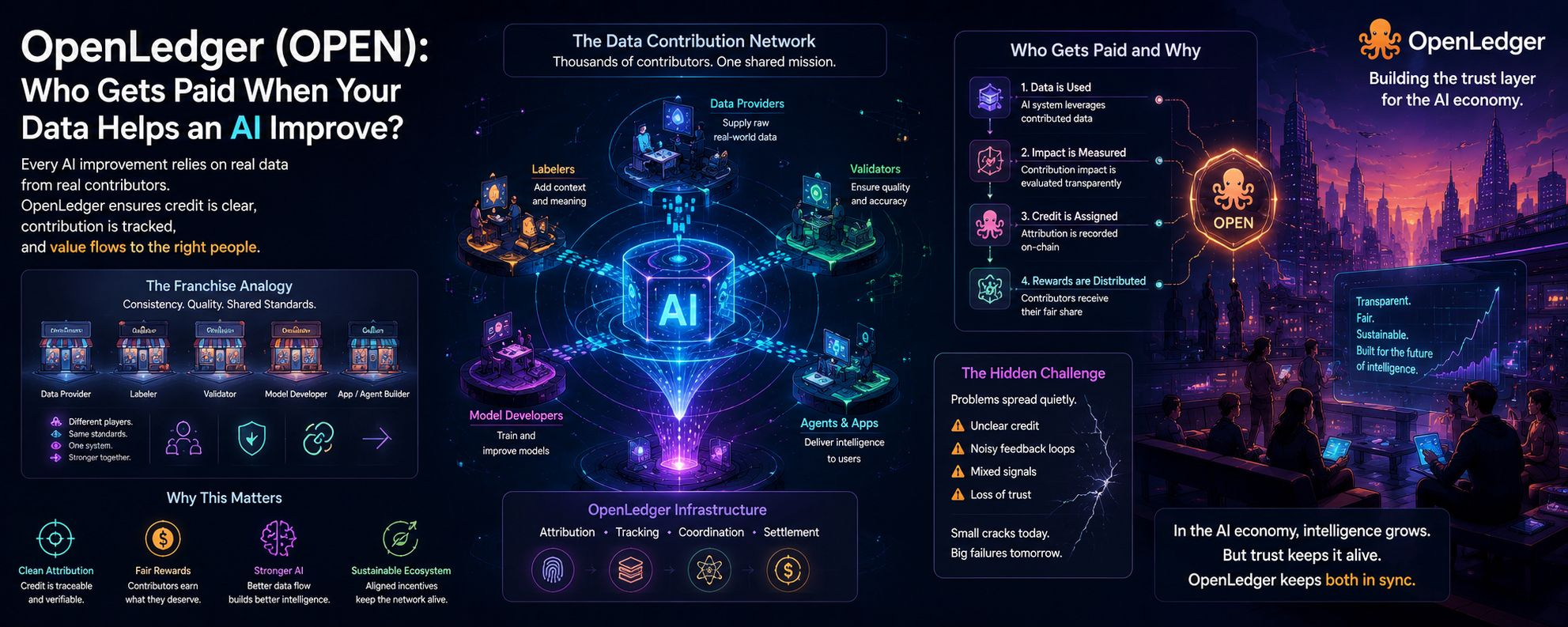

Je n'arrêtais pas de penser aux systèmes de franchise en lisant plus profondément sur la structure autour d'OpenLedger.
Pas à cause du branding ou de l'expansion, mais parce que tout le système dépend de la cohérence entre des milliers de participants séparés opérant sous des règles partagées.
Une franchise ne survit que lorsque différents points de vente peuvent produire des résultats fiables sans avoir besoin d'une supervision constante depuis le centre. Une fois que cette cohérence s'affaiblit, la confiance dans l'ensemble du réseau commence à s'estomper—même si les points de vente individuels fonctionnent toujours bien.
Cette même pression commence à apparaître à l'intérieur des environnements IA.
Les modèles ne sont plus des outils isolés assis à un endroit. Ils deviennent des systèmes distribués connectés à des ensembles de données extérieurs, à l'activité des contributeurs, à des boucles de rétroaction, à des agents autonomes et à des couches d'exécution interagissant continuellement sous la surface.
La partie difficile n'est plus l'intelligence elle-même.
La partie difficile est de garder tous ces éléments en mouvement alignés dans le temps sans créer d'instabilité - et sans transformer le crédit en conjecture.
C'est une des raisons pour lesquelles @OpenLedger (OPEN) se distingue différemment pour moi par rapport aux projets IA habituels.
Le projet continue d'évoluer vers une structure opérationnelle au lieu de se concentrer uniquement sur les résultats visibles. L'attribution, le flux de contribution, les couches de coordination et l'interaction entre les systèmes deviennent de plus en plus importants une fois que les environnements autonomes cessent de sembler expérimentaux et commencent à se comporter comme une infrastructure sur laquelle les gens comptent quotidiennement, sans prêter attention à ce qui se passe en dessous.
La chose étrange à propos des systèmes hautement connectés est qu'ils échouent rarement de manière dramatique au début.
Les problèmes se répandent discrètement.
Un ensemble de données utile est absorbé sans un crédit clair.
Une boucle de rétroaction devient plus bruyante qu'elle n'en a l'air.
Le signal d'un contributeur est mélangé dans le système sans trace claire.
Les résultats continuent d'apparaître, mais la fiabilité commence à glisser de manière subtile et difficile à cerner. De petites incohérences circulent dans le réseau, la coordination s'affaiblit, et finalement l'environnement devient plus difficile à faire confiance, même si aucun échec unique ne semble catastrophique en soi.
Une fois que suffisamment de couches dépendent les unes des autres simultanément, les problèmes simples cessent d'être simples.
Donc, la question « Qui est payé lorsque vos données aident une IA à s'améliorer ? » n'est pas qu'une question de paiement.
C'est une question structurelle.
Parce que si la contribution ne peut pas être mesurée clairement, elle ne peut pas être récompensée équitablement. Et si elle ne peut pas être récompensée équitablement, le système peut toujours croître, mais il devient plus difficile à maintenir sans friction et fuite discrète au fil du temps.
C'est pourquoi OpenLedger (OPEN) reste sur mon radar d'un point de vue structurel.
À long terme, les projets qui comptent peuvent être ceux qui maintiennent la contribution, l'attribution et la coordination constantes, tandis que tout en dessous continue de bouger.#OpenLedger $OPEN