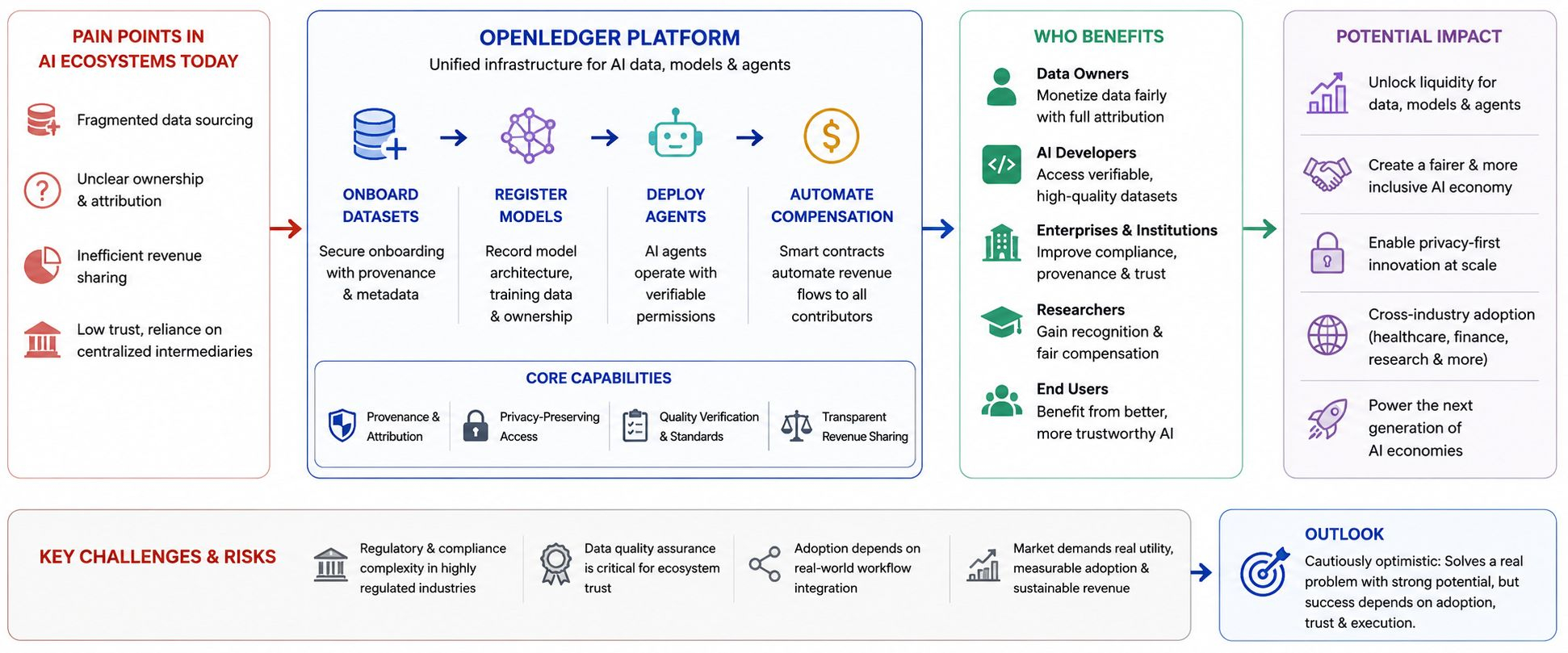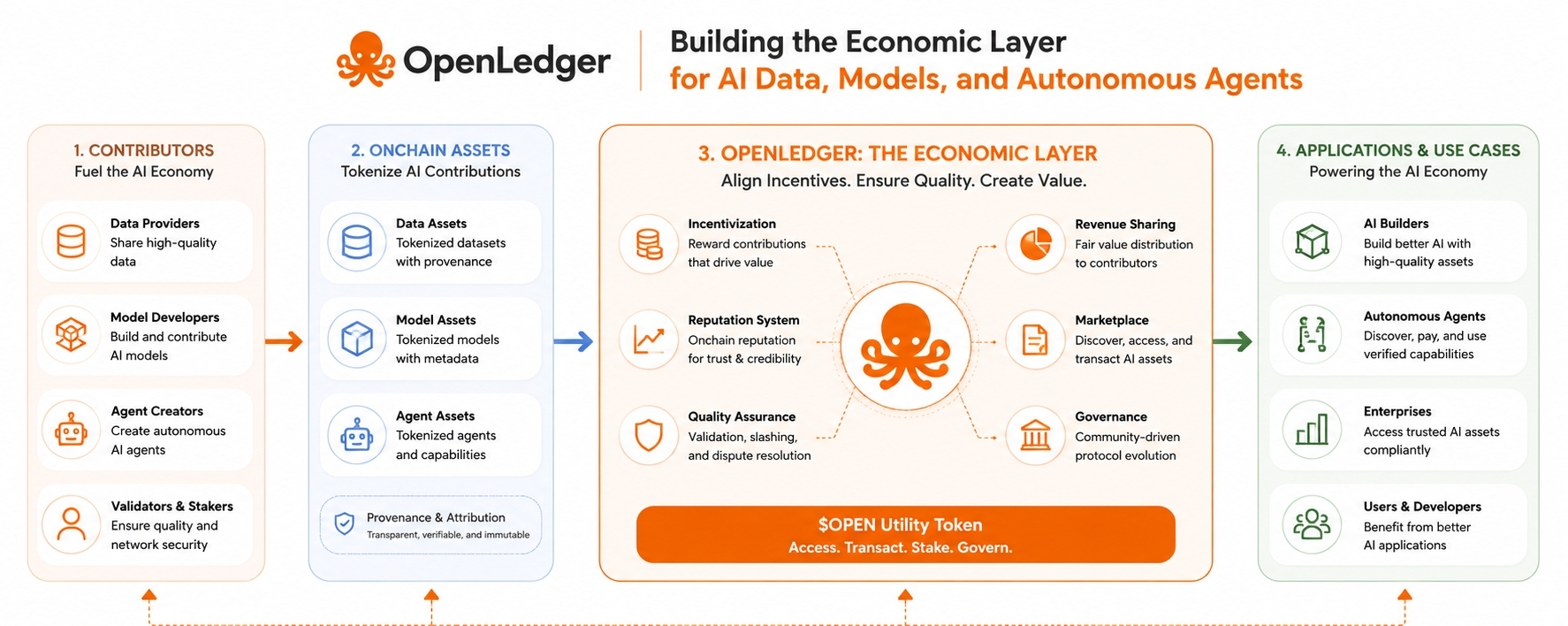
Quand je regarde OpenLedger, je ne le vois pas juste comme une autre blockchain essayant de s'accrocher au récit de l'IA. Je pense que le projet essaie de s'attaquer à l'un des plus gros problèmes structurels qui émergent dans l'économie de l'IA : le fait qu'il existe d'énormes quantités de données précieuses, de modèles et d'agents intelligents, mais que les personnes et les organisations créant cette valeur n'ont souvent pas de moyen transparent pour la monétiser, prouver la propriété ou contrôler son utilisation. L'idée centrale derrière OpenLedger semble être de créer une couche d'infrastructure où les contributeurs de données, les constructeurs de modèles et les opérateurs d'agents IA peuvent recevoir des récompenses économiques pour la valeur qu'ils génèrent tout en maintenant un meilleur contrôle sur la propriété et l'attribution.
Ce qui rend le concept intéressant pour moi, c'est qu'il se situe à l'intersection de deux tendances puissantes qui ont été en accélération jusqu'en 2025 et au-delà en 2026. D'un côté, les modèles d'IA deviennent de plus en plus dépendants d'ensembles de données de haute qualité et spécifiques au domaine plutôt que simplement de volumes plus importants de contenu public sur Internet. De l'autre côté, la technologie blockchain cherche une utilité pratique au-delà de la spéculation. OpenLedger tente de connecter ces tendances en traitant les données et les résultats d'IA comme des actifs économiques qui peuvent être suivis, vérifiés et monétisés grâce à une infrastructure décentralisée.
D'un point de vue pratique, le problème qu'il aborde est étonnamment simple. Aujourd'hui, si un hôpital contribue des données d'imagerie médicale pour former un modèle de diagnostic IA, l'institution peut ne recevoir que peu de bénéfices économiques à long terme après l'accord initial. Si un groupe de recherche développe un modèle d'IA spécialisé qui devient partie d'un écosystème d'IA plus large, l'attribution peut devenir floue. Si un agent IA effectue un travail utile de manière autonome, déterminer comment la valeur devrait être répartie entre les fournisseurs de données, les créateurs de modèles, les opérateurs d'infrastructure et les utilisateurs finaux devient extrêmement difficile. OpenLedger demande essentiellement si la blockchain peut fournir un système de comptabilité transparent pour la création de valeur IA.
Je pense que la partie la plus forte de la vision n'est pas en fait l'aspect de tokenisation. C'est la possibilité de créer des enregistrements de contribution vérifiables. En théorie, chaque participant à un flux de travail d'IA pourrait recevoir un crédit et une compensation proportionnels à leur contribution. Cela semble abstrait jusqu'à ce que vous imaginiez un véritable environnement de soins de santé. Supposons qu'un modèle de détection du cancer soit formé à l'aide d'ensembles de données d'imagerie provenant d'hôpitaux de plusieurs pays. Certaines institutions contribuent à des millions de scans, d'autres contribuent à des cas de maladies rares qui sont statistiquement plus précieux. Un système comme OpenLedger pourrait potentiellement enregistrer ces contributions et créer un mécanisme par lequel les récompenses reviennent aux fournisseurs de données d'origine chaque fois que le système d'IA généré génère une valeur commerciale. Sans une telle infrastructure, les plus grandes entreprises technologiques capturent souvent la majeure partie du potentiel économique tandis que les contributeurs de données restent largement invisibles.
Un autre exemple que je trouve convaincant concerne la recherche pharmaceutique. La découverte de médicaments repose de plus en plus sur des modèles d'IA formés sur des ensembles de données moléculaires, génomiques et cliniques très sensibles. Les organisations sont compréhensiblement réticentes à exposer des informations brutes en raison des réglementations sur la confidentialité et des préoccupations relatives à la propriété intellectuelle. Dans un monde où les mécanismes de divulgation sélective mûrissent, une entreprise pourrait prouver que certaines conditions concernant un ensemble de données sont vraies sans exposer l'ensemble de données lui-même. Le résultat serait une plus grande collaboration sans forcer les organisations à sacrifier la confidentialité. Ce type de capacité devient particulièrement précieux à mesure que les soins de santé, la biotechnologie et l'IA deviennent plus interconnectés.
Les bénéficiaires ciblés sont plus larges que ce que beaucoup de gens supposent au départ. Les propriétaires de données sont des bénéficiaires évidents car ils gagnent des opportunités de monétisation potentielles. Les développeurs d'IA en bénéficient car ils ont accès à des sources de données vérifiables et à des cadres de licence transparents. Les entreprises en bénéficient car elles peuvent suivre la provenance et la conformité de manière plus efficace. Les chercheurs en bénéficient car l'attribution devient plus transparente. Même les utilisateurs finaux peuvent potentiellement en bénéficier car ils peuvent mieux comprendre d'où proviennent les résultats de l'IA et comment les modèles ont été formés.
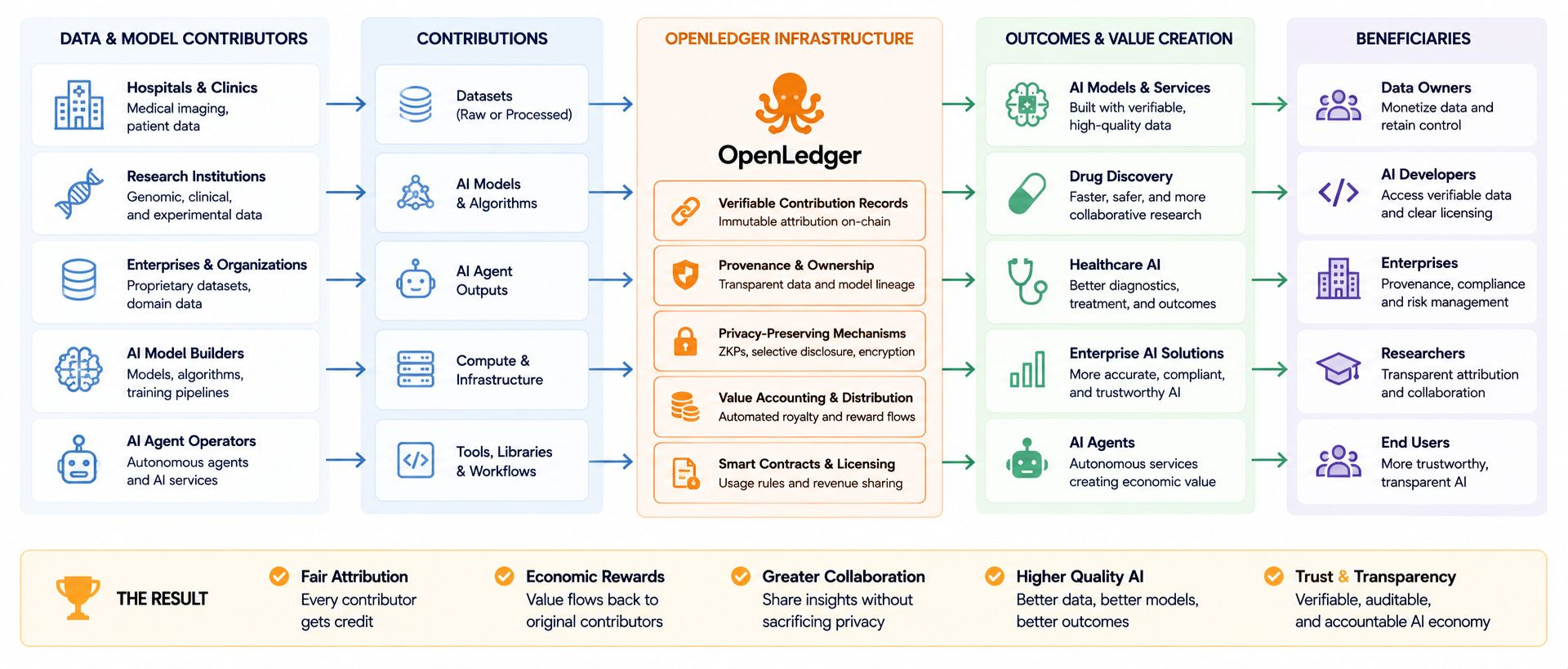
Opérationnellement, je pense qu'OpenLedger essaie de réduire plusieurs formes de friction qui existent actuellement au sein des écosystèmes d'IA. L'approvisionnement en données est fragmenté. Les enregistrements de propriété sont souvent peu clairs. Les mécanismes de partage des revenus sont inefficaces. La confiance entre les participants dépend souvent d'intermédiaires centralisés. Si OpenLedger réussit, les organisations pourraient théoriquement intégrer des ensembles de données, enregistrer des modèles, déployer des agents et automatiser les flux de compensation au sein d'un cadre unifié. Cela simplifierait la coordination entre plusieurs parties qui peuvent ne pas se faire entièrement confiance.
L'attrait émotionnel du projet est facile à comprendre. Il y a quelque chose d'intrinsèquement attrayant dans l'idée que les créateurs devraient être compensés équitablement pour la valeur qu'ils génèrent. Beaucoup de gens croient que l'économie actuelle de l'IA récompense de manière disproportionnée les propriétaires de plateformes tout en dévaluant les contributeurs de données. OpenLedger puise directement dans ce sentiment. Je pense que ce récit émotionnel résonnera fortement avec les développeurs, les chercheurs et les institutions qui se sentent exclus du potentiel économique de l'IA.
En même temps, je reste prudent. L'histoire des projets blockchain est remplie de visions ambitieuses qui semblent convaincantes en théorie mais rencontrent des défis d'adoption en pratique. Le problème le plus difficile n'est que rarement la technologie elle-même. Le problème le plus difficile est de convaincre les institutions de changer des workflows établis. Les hôpitaux, les entreprises pharmaceutiques, les gouvernements et les entreprises opèrent sous des cadres réglementaires stricts. Intégrer une infrastructure basée sur la blockchain dans ces environnements est beaucoup plus difficile que de déployer une nouvelle application décentralisée.
Il existe également une réalité de marché plus large. En mai 2026, l'investissement en IA reste extrêmement fort à l'échelle mondiale, les entreprises continuant de privilégier l'infrastructure d'IA, les modèles spécifiques au domaine et les agents autonomes. Pendant ce temps, les marchés de la blockchain sont devenus plus sélectifs. Les investisseurs exigent de plus en plus une véritable utilité, une adoption mesurable et des revenus durables plutôt que de pures narrations de tokens spéculatifs. Cet environnement pourrait en fait jouer en faveur d'OpenLedger s'il démontre une demande réelle liée à l'IA. Cependant, cela signifie également que les attentes sont beaucoup plus élevées qu'elles ne l'étaient lors des cycles blockchain précédents.
Une autre préoccupation que j'ai concerne la qualité des données. Un marché pour les données d'IA ne fonctionne que si les participants font confiance à la valeur des ensembles de données sous-jacents. Des données de mauvaise qualité peuvent nuire à la performance des modèles, peu importe à quel point le cadre économique semble élégant. OpenLedger fait donc face à un défi qui va au-delà de l'ingénierie blockchain. Il doit aider à établir la crédibilité, les normes de vérification et les mécanismes d'évaluation de la qualité. Sinon, le réseau risque de devenir un marché rempli de données dont la valeur économique est difficile à déterminer objectivement.
La dimension de la confidentialité est là où je pense que le projet pourrait devenir particulièrement pertinent. À travers le monde, les organisations deviennent plus prudentes quant à la manière dont les informations sensibles sont partagées. Les dossiers de santé, les informations financières, les ensembles de données de recherche propriétaires et les données d'identité personnelle nécessitent tous des protections solides. Les systèmes qui soutiennent l'accès contrôlé, la divulgation sélective et les permissions vérifiables seront probablement de plus en plus importants. Si OpenLedger peut réussir à combiner la monétisation avec une infrastructure préservant la confidentialité, il pourrait occuper un créneau significatif qui va au-delà des applications conventionnelles de la blockchain.
Mon avis général est prudemment optimiste. Je pense qu'OpenLedger cible un véritable problème plutôt que d'inventer un cas d'utilisation artificiel pour la blockchain. L'idée de débloquer la liquidité autour des données, des modèles d'IA et des agents autonomes s'aligne avec la direction générale du paysage technologique. Cependant, le succès ultime du projet dépendra moins de l'architecture technique et plus de la décision des véritables organisations de lui faire confiance avec des données précieuses et des workflows d'IA de production. Si cette adoption se matérialise, OpenLedger pourrait devenir une partie de l'infrastructure fondamentale soutenant la prochaine génération d'économies d'IA. Si l'adoption reste limitée, elle risque de devenir une autre plateforme techniquement sophistiquée à la recherche d'une demande généralisée. À ce stade, je vois plus de promesses que de certitudes, ce qui est souvent là où les projets technologiques les plus intéressants commencent.