Hier, je ne voulais à la base que jeter un œil à la documentation d'OpenLedger pour voir ce qui se passait avec ces modules clés, mais plus je lisais, plus je devenais excité, au point de tenir éveillé jusqu'à 2 heures du matin.
Et ce qui a déclenché cette réflexion profonde, c'est en fait une chose extrêmement banale de la vie quotidienne.
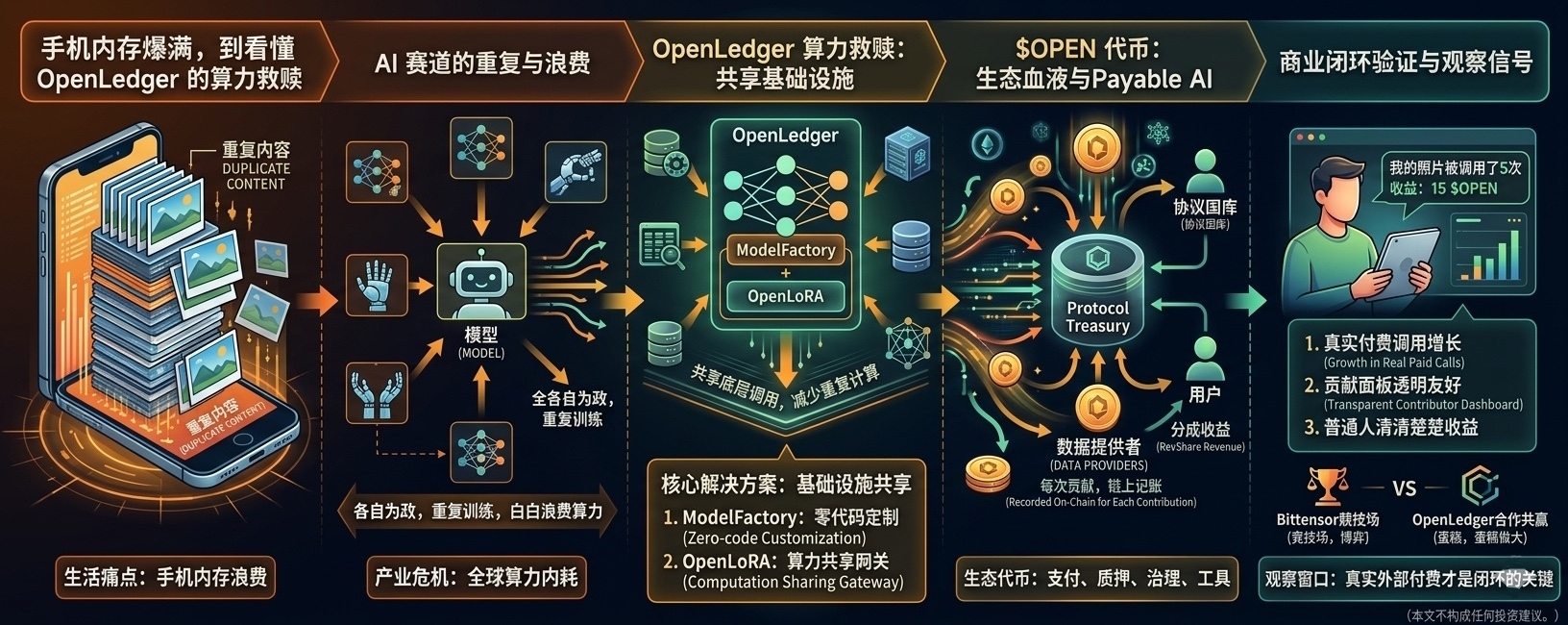
Il y a quelques jours, ma mémoire de téléphone était pleine à craquer, et en supprimant douloureusement des photos, j'ai découvert qu'une même image apparaissait dans trois dossiers différents, certaines ayant même été répétées cinq fois. Je me suis dit : c'est quoi ce bordel ? Mon téléphone est en train de me faire des copies infinies en cachette ?
Hier soir, en feuilletant la documentation technique d'OpenLedger, j'ai eu un 'boom' dans ma tête et j'ai instantanément fait le lien—**l'industrie AI décentralisée d'aujourd'hui fait des choses tout aussi stupides, voire plus, que de répéter des photos.**
Différents projets essayent de surfer sur la tendance en utilisant sans cesse les mêmes données open source pour entraîner des modèles presque identiques, déployant des nœuds similaires, chacun consommant de manière autonome une puissance de calcul GPU coûteuse. Au final, la puissance de calcul mondiale, déjà rare, est ainsi gaspillée dans cette 'répétition de création de roues' inutile.
Et ce qu'OpenLedger veut faire, c'est une sorte de 'désencombrement' et de rédemption pour la puissance de calcul AI.
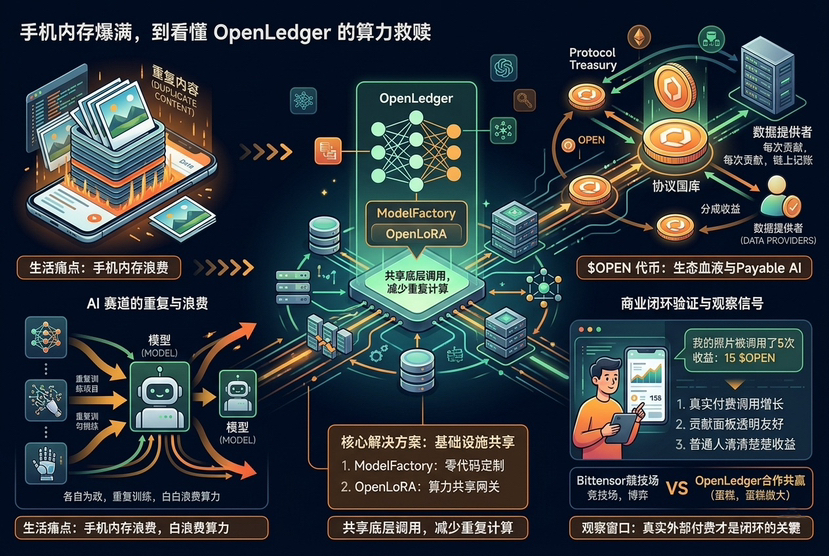
Ne créez plus chacun vos propres roues, partagez-les.
En analysant sa documentation, vous découvrirez que sa logique architecturale est extrêmement ciblée :
*ModelFactory (usine de modèles) : ** Principalement axé sur un 'modèle de personnalisation sans code'. Son existence libère directement les développeurs ordinaires et les entreprises de ces configurations manuelles lourdes et complexes, abaissant ainsi la barrière à l'entrée.
*OpenLoRA : ** Cette étape va plus loin. Elle extrait directement les appels de modèles et la puissance de calcul sous-jacente pour les partager, en éliminant spécifiquement ces calculs répétitifs et autonomes.
En gros, OpenLedger veut établir l'infrastructure de l'ère AI pour que personne ne perde son énergie dans des pertes de base inutiles, et que nous puissions tous travailler ensemble pour élargir le gâteau.
Dans cet écosystème vaste, **le jeton natif $OPEN joue le rôle de 'sang'**. Que ce soit pour les paiements d'appels, le staking de nœuds, la gouvernance communautaire ou les opérations réseau de base, tout est profondément lié à lui. Avec un total de 1 milliard de pièces, ce n'est pas un simple meme à la mode sans cas d'utilisation, mais un **outil de niveau industriel** fortement lié aux activités réelles sur la chaîne.
Sous l'apparence séduisante de Payable AI, qui va payer ?
Récemment, le concept de 'Payable AI (AI monétisable)' a vraiment fait fureur sur Twitter, tout le secteur dessine de grands projets : comment transformer vos photos, vos données annotées, et vos contenus professionnels en véritable argent lorsque les modèles AI les utilisent.
Cela ressemble à une utopie de productivité. OpenLedger, grâce à son livre de comptes technique, peut effectivement enregistrer chaque appel et chaque contribution de manière transparente sur la chaîne.
Mais en y regardant de plus près, le véritable champ de bataille de l'industrie ne réside pas dans 'comment tenir les comptes', mais dans 'qui va payer ?'.
Si le prétendu 'frais d'appel sur la chaîne' n'est qu'un transfert d'argent fictif d'une poche à l'autre par le projet, alors c'est fondamentalement une auto-satisfaction du Web3. **Seulement si de véritables entreprises Web2 sont prêtes à payer de l'argent réel pour cette capacité AI, ce cycle commercial sera complètement opérationnel.**
De plus, le ratio de distribution des bénéfices est également un problème extrêmement difficile à aborder :
Une fois qu'une IA est appelée, supposons qu'un client externe ait payé 1 euro. Les créateurs de modèles, les fournisseurs de puissance de calcul, les passerelles de confidentialité, les nœuds de validation, le trésor du protocole… ce cercle d'intérêts se partage les bénéfices, et les véritables 'contributeurs de données ordinaires' ne récupèrent peut-être qu'un centime.
Donc, seuls les scénarios commerciaux **à haute valeur et à prix élevé**, comme l'analyse financière, les modèles privés médicaux, ou les bases de connaissances professionnelles d'entreprise, ont un sens à discuter des partages de revenus. Si c'est juste pour des discussions banales ou des questions sans récompenses, ces quelques centimes ne suffiront même pas à acheter un thé au lait en un an pour un utilisateur ordinaire.
Par rapport à l'arène de Bittensor, je lui ai laissé une fenêtre d'observation.
Beaucoup de gens le comparent à Bittensor ($TAO), mais d'après mon observation, ces deux-là ne sont pas du tout sur la même longueur d'onde.
*Bittensor ressemble plutôt à une arène romaine brutale**. Les sous-réseaux sont en pure lutte à somme nulle, vos récompenses proviennent des parts perdues par d'autres, l'auto-consommation est extrêmement sévère.
*OpenLedger met l'accent sur la collaboration incrémentale**. Il souhaite élargir le gâteau global en réduisant le gaspillage et en augmentant l'efficacité, puis en répartissant selon la contribution.
Le récit de ce dernier semble plus sain et plus humain, mais **la difficulté de mise en œuvre augmente de manière exponentielle**. Car vous devez coordonner sur une seule chaîne des parties prenantes arrogantes, des modèles pointilleux, des fournisseurs de puissance de calcul avides de profits et des utilisateurs exigeants, ce qui met à l'épreuve les compétences d'ingénierie et commerciales de l'équipe.
J'ai suivi ce projet depuis ses premières idées dans le livre blanc, à travers le testnet, jusqu'à aujourd'hui avec le récit de Payable AI qui prend forme. Je reconnais absolument sa direction technique (règlement des droits d'auteur sur les données, partage des revenus dès l'appel), et son imagination est suffisamment séduisante. Mais au final, dans le Web3, ce n'est jamais la qualité des PPT qui compte, mais la capacité à créer un cycle commercial.
Dans six mois ou un an, y aura-t-il encore un flux d'affaires externes stable sur la chaîne pour le soutenir ? Les créateurs pourront-ils obtenir des retours durables et significatifs ? C'est cela qui détermine le plafond de valeur de $OPEN .
Donc pour l'instant, mon attitude réelle est : **laisser une fenêtre d'observation à haute fréquence. Ne pas charger à fond sans réfléchir, et ne pas chanter aveuglément à la baisse.**
Ensuite, je vais régulièrement surveiller ses quelques tableaux de données clés :
1. Y a-t-il eu une croissance organique non subventionnée du volume réel d'appels payants ?
2. Le **tableau de contribution de données des gens ordinaires** est-il devenu assez idiot et assez convivial ?
3. La concentration des revenus s'est-elle améliorée, et la richesse s'oriente-t-elle à nouveau vers quelques grands acteurs ?
Le jour où même une grande-tante ordinaire n'y connaissant rien en crypto pourra clairement voir une photo de paysage qu'elle a prise utilisée par un grand modèle d'entreprise 5 fois, et qu'elle reçoit concrètement quelques dollars de dividende—à ce moment-là, il ne sera pas tard pour envisager sérieusement de charger à fond.
La deuxième moitié de la course AI est énorme. La prochaine véritable opportunité divine ne sera peut-être pas de comparer qui a le plus de paramètres de modèle, mais **de voir qui réussit à réduire véritablement les répétitions et le gaspillage choquants dans ce secteur**.
$OPEN essaie de tracer ce chemin, il mérite d'être ajouté à notre liste de surveillance.
(Remarque : cet article est une tâche de plateforme, ne constitue aucune recommandation d'investissement.)