The internet used to be a place where you could at least pretend most things were real.
Not perfect. Not clean. Not even close. But real enough. Real people wrote the posts. Real people made the mistakes. Real people argued in comment sections at ridiculous hours and built communities around weird little corners of the web nobody outside those spaces cared about. The mess was the point. It was human mess.
Now a lot of that feels like it is getting buried under machine noise.
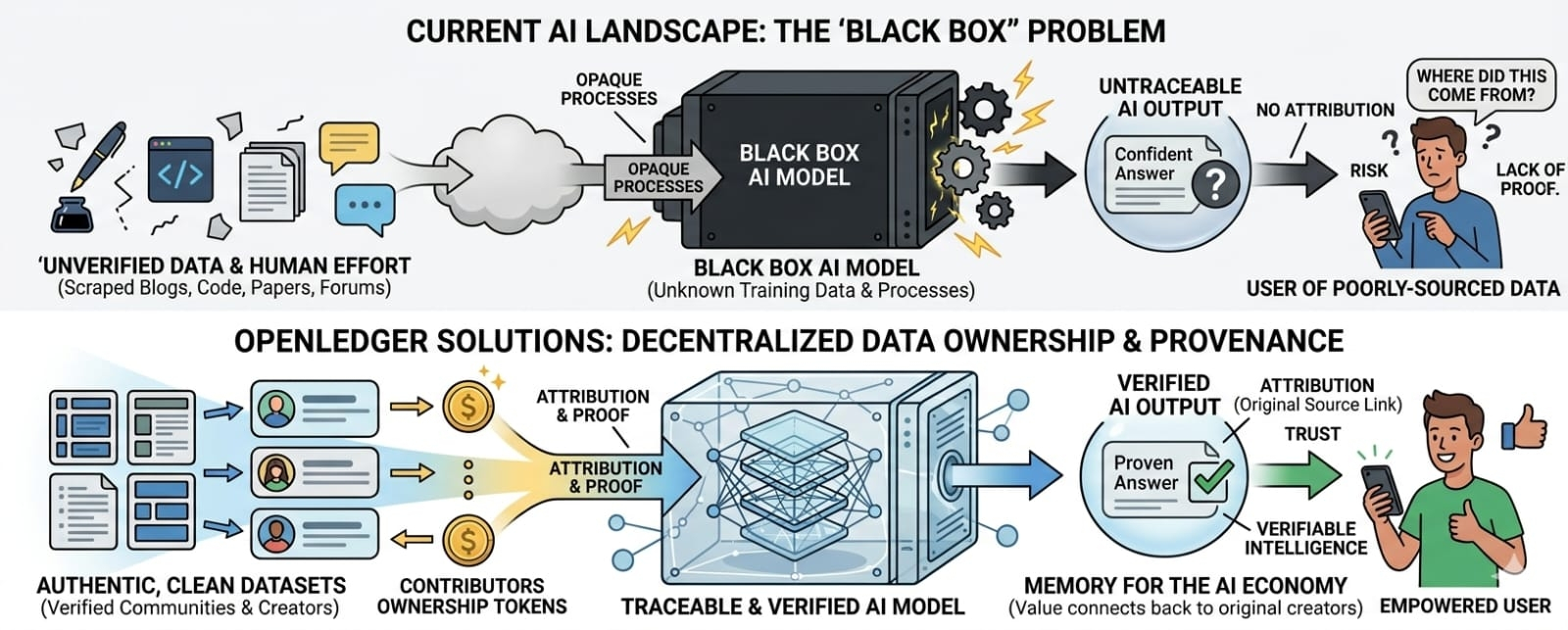
And that is the part that keeps bothering me. Not because AI is bad by default. It is not that simple. AI is useful. Sometimes it is actually impressive. Sometimes it saves time in a way that feels almost unfair. But the bigger the technology gets, the more obvious the cracks underneath it become. Most of these systems do not really explain where their answers come from. They just answer. Confidently. Smoothly. Like they know. Sometimes they do. Sometimes they absolutely do not. And the user usually has no clue which one they are looking at.
That is a massive problem if AI is going to sit inside real workflows for long enough.
Because once people start depending on these systems for research, business, health, law, education, finance, and all the other places where mistakes matter, “trust me” stops being good enough. A model saying something with confidence is not the same thing as a model proving where it learned it. That gap is where a lot of the risk lives. Not the flashy stuff. The boring stuff. The invisible stuff. The part nobody wants to spend time on because it is less exciting than the demo.
That is where OpenLedger starts making more sense to me.
Not as another loud crypto project trying to attach itself to the AI wave. That whole game is already tired. Everybody slapping “AI” onto their token and acting like it means something. Most of it feels like noise. OpenLedger at least seems focused on a real problem that AI keeps dragging around behind it like a weight it cannot shrug off. Provenance. Attribution. Verification. The stuff that sounds dry until you realize it is probably the whole game.
If AI is going to keep absorbing more of the internet, then somebody has to track what it is absorbing and where it came from. Otherwise the whole system turns into one giant black box with money flowing through it while nobody can explain the path anything took. That is not sustainable. Maybe it works for a while because hype covers the cracks. But not forever.
OpenLedger seems to be betting on that exact pressure point. The idea is not just to build AI tools. It is to build a system where data, models, and agents can be traced and monetized in a way that connects back to the people and communities that actually created value in the first place. That matters more than people think. Because the current AI economy is basically built on a weird bargain where public human knowledge gets scraped, mixed, trained, and sold back as a product, while the original contributors mostly get nothing. Maybe a little attention. Maybe a little traffic. Rarely ownership.
And that is the part that feels rotten.
People keep acting like AI is some clean leap forward. It is not clean at all. It is built on huge amounts of work that already existed. Blogs. Code. Papers. Forums. Repos. Comments. Art. Conversations. The raw material was human. The economic structure now is mostly corporate. That mismatch is not going away just because the outputs look better every few months.
That is why provenance matters.
Because once the internet gets flooded with synthetic content, the line between real information and machine-generated mush gets harder to see. We are already heading there. Articles written by models. Replies written by models. Videos made by models. Entire websites that feel like they were assembled by a machine for another machine. And when future AI systems start training on that junk, the loop gets even worse. AI on top of AI on top of AI, until the original human signal gets buried under layers of noise.
That is not some dramatic sci-fi warning. It is already happening in smaller ways.
OpenLedger’s angle is basically: if the internet is going to become an AI economy, then the economy needs memory. It needs records. It needs proof. It needs a way to say this data mattered, this model used that source, this contributor added real value, and this output should not just vanish into a corporate machine with no trace left behind.
That sounds simple, but it is not. It is actually one of the harder problems in the whole space. Maybe that is why most projects avoid it. It is easier to talk about scale. Easier to talk about agents. Easier to talk about faster generation and better benchmarks and all the usual stuff people post on X to look smart for twelve hours. It is much harder to talk about accountability. And yet accountability is what eventually decides whether these systems become trusted infrastructure or just another layer of noisy automation nobody can fully rely on.
That is also why the data side matters so much. If the future of AI is only giant models trained on messy internet sludge, the whole thing gets weaker over time. But if communities can build cleaner datasets, specialized models, and traceable contribution networks, then AI becomes less like a black box and more like a real economy with actual participants. Not perfect. Not magically fair. But at least legible. At least trackable. At least closer to something people can inspect instead of just blindly use.
That is the kind of shift OpenLedger seems to be aiming at. Not just intelligence. Verified intelligence. Not just automation. Accountable automation. Not just data extraction. Data ownership. That is a much harder story to sell, which is probably why it matters more.
Because once the hype settles, the market usually stops caring about shiny promises and starts caring about the plumbing underneath them. And in AI, the plumbing is everything.
#OpenLedger $OPEN @OPEN LEDGER