Je me souviens d'une conversation que j'ai eue il y a un moment avec un ami qui travaille dans l'IA. Nous avons passé des heures à parler de modèles, de puissance de calcul, de GPU, et de toutes les choses habituelles que les gens associent à l'intelligence artificielle.
À l'époque, je pensais que c'était là que la vraie compétition se déroulait.
Construisez des modèles plus grands. Entraînez-vous sur plus de données. Accédez à plus de puissance de calcul.
Simple.
Mais plus je suivais l'espace, plus je commençais à remarquer quelque chose qui semblait négligé.
Ce n'était pas de l'intelligence.
C'était la mémoire.
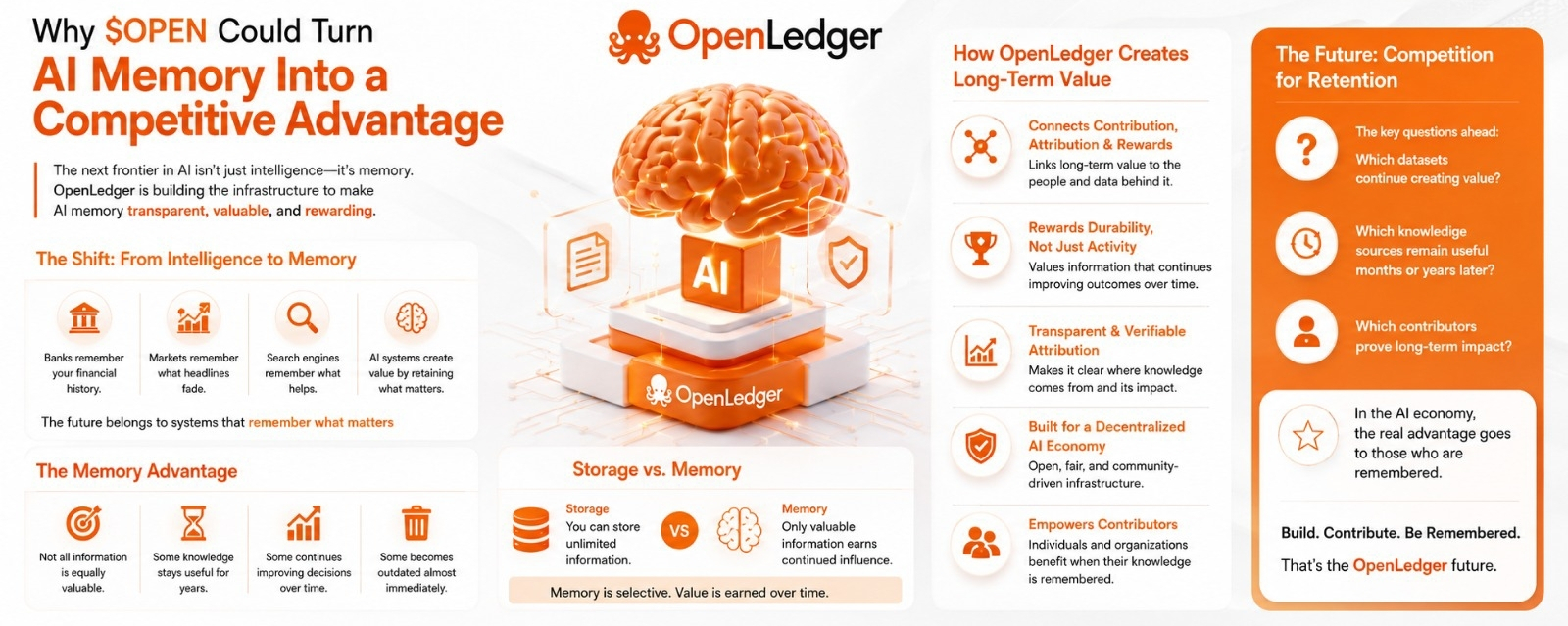
Pas la mémoire au sens technique. Je parle de la mémoire dans la façon dont les systèmes performants se souviennent de ce qui compte et ignorent ce qui ne compte pas.
Une fois que j'ai commencé à y penser, j'ai vu des exemples partout.
Les banques se souviennent de votre historique financier.
Les marchés se souviennent des informations longtemps après que les gros titres aient disparu.
Les moteurs de recherche se souviennent des sources qui aident constamment les utilisateurs.
Les systèmes qui créent le plus de valeur ne sont souvent pas ceux qui savent le plus. Ce sont ceux qui retiennent les informations les plus utiles au fil du temps.
C'est une des raisons pour lesquelles OpenLedger attire mon attention.
La plupart des discussions sur l'IA aujourd'hui sont encore axées sur la génération de meilleures réponses. Mais je me demande à propos d'une question différente :
Comment l'IA décide-t-elle ce qui mérite d'être mémorisé ?
Parce que toutes les informations ne sont pas également précieuses.
Certaines connaissances restent utiles pendant des années.
Certaines deviennent obsolètes presque immédiatement.
Certaines informations continuent d'améliorer les décisions longtemps après être entrées dans un système, tandis que d'autres perdent tranquillement leur pertinence.
Et en ce moment, on a l'impression que l'industrie consacre beaucoup plus de temps à discuter de la façon dont l'IA apprend qu'à comment elle se souvient.
Plus j'y pense, plus je ressens que la mémoire pourrait être un problème économique autant que technique.
Imaginez deux personnes contribuant des informations à un réseau d'IA.
Un contributeur fournit des données qui continuent d'améliorer les résultats des années plus tard.
L'autre contribue des informations qui semblaient utiles au départ mais qui sont rapidement devenues sans rapport.
Au début, les deux contributions peuvent sembler également précieuses.
La différence ne devient visible qu'avec le temps.
C'est là que l'approche d'OpenLedger devient intéressante pour moi.
Ce qui ressort, ce n'est pas la promesse d'une IA plus intelligente. Presque chaque projet le revendique.
Ce qui se démarque, c'est l'idée de connecter contribution, attribution et récompenses d'une manière qui rend la valeur à long terme visible.
Je continue de le comparer à ce qui s'est passé avec Internet.
Au début, l'information était partout, mais trouver des informations utiles était difficile.
Ensuite, les moteurs de recherche ont introduit des systèmes de classement.
Soudain, le contenu ne se contentait pas de rivaliser pour exister.
Il rivalisait pour rester visible.
L'IA pourrait se diriger vers un moment similaire.
Sauf que cette fois, la compétition pourrait ne pas être pour l'attention.
Cela peut être pour la rétention.
Quelles ensembles de données continuent de créer de la valeur ?
Quelles sources de connaissances restent utiles des mois ou des années plus tard ?
Quels contributeurs peuvent prouver que leurs informations continuent d'améliorer les résultats longtemps après avoir été soumises ?
Ces questions semblent de plus en plus importantes à mesure que l'IA s'implique davantage dans les décisions du monde réel.
Une chose que j'ai réalisée, c'est que le stockage et la mémoire ne sont pas la même chose.
Vous pouvez stocker des informations illimitées.
Cela ne signifie pas que cela a de l'importance.
La mémoire est sélective.
Certaines informations gagnent une influence continue.
La plupart des informations ne le font pas.
Si OpenLedger peut aider à rendre ce processus plus transparent, les contributeurs pourraient commencer à optimiser pour quelque chose de différent.
Pas le volume.
Durabilité.
Et la durabilité est beaucoup plus difficile à feindre.
Tout le monde peut télécharger des données.
Tout le monde peut créer du contenu.
On a vu cela sur Internet depuis des années.
Mais l'information qui reste utile longtemps après sa création est beaucoup plus rare.
Un ensemble de données qui continue d'améliorer les résultats dix-huit mois plus tard raconte une histoire.
Une source qui continue d'être référencée à travers des milliers d'interactions en dit une autre.
Avec le temps, le marché commence à distinguer entre les informations qui existent et celles qui survivent.
C'est une distinction qui devient, je pense, plus importante à mesure que l'IA pénètre plus profondément dans des domaines comme la finance, les logiciels d'entreprise, la santé et d'autres environnements où les décisions ont de vraies conséquences.
Parce qu'éventuellement, les gens poseront des questions qui sont étonnamment simples.
Pourquoi l'IA a-t-elle fait cette recommandation ?
Quelle information a influencé cette décision ?
D'où vient cette connaissance ?
Au moment où ces questions deviennent importantes, l'attribution devient également importante.
Bien sûr, rien de tout cela ne garantit le succès d'OpenLedger.
Les défis sont réels.
Mesurer la valeur de l'information est incroyablement difficile.
La connaissance ne circule pas par des canaux bien définis.
Différentes sources influencent les résultats simultanément.
L'attribution devient compliquée.
Et comme chaque système qui introduit des récompenses, il y aura toujours des tentatives de manipulation.
On a vu ça avec les moteurs de recherche.
On a vu ça avec les réseaux sociaux.
Les réseaux d'IA ne seront pas différents.
Mais c'est en fait une partie de ce qui rend l'opportunité intéressante.
Le problème est encore précoce.
Personne n'a complètement résolu cela.
Ce qui me garde concentré, ce n'est pas l'idée que la mémoire de l'IA devrait être permanente.
C'est l'idée que la mémoire pourrait devenir compétitive.
Peut-être que l'économie future de l'IA ne sera pas définie uniquement par ceux qui construisent les modèles les plus intelligents.
Peut-être que cela sera également défini par ceux qui contribuent avec des informations suffisamment précieuses pour être mémorisées.
Et cela semble être une opportunité beaucoup plus grande que la plupart des gens ne le réalisent.
@OpenLedger #OpenLedeger #openledger $OPEN
