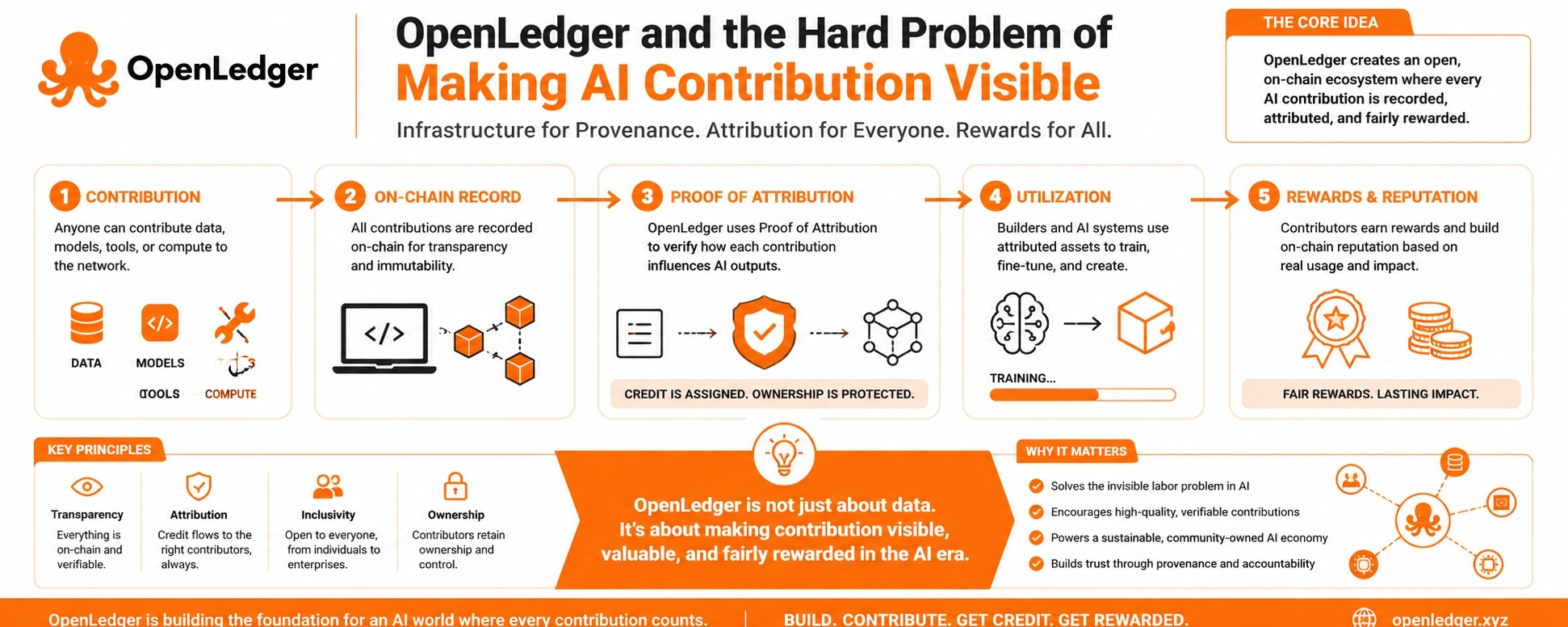
OpenLedger avec un genre d'intérêt prudent, pas parce qu'il a l'histoire la plus bruyante autour de lui, mais parce que le problème qu'il essaie d'aborder semble plus grand que la conversation habituelle en surface. À première vue, OpenLedger semble simple : un projet construit autour des données AI, de l'attribution, et de l'idée que les contributeurs devraient avoir une place plus claire dans la chaîne de valeur. Mais plus je l'examine, plus cela semble être quelque chose de moins direct. Il ne s'agit pas seulement d'organiser des données pour l'IA. Il essaie de répondre à une question plus difficile : lorsque l'intelligence est construite à partir de nombreux inputs invisibles, qui est retenu, qui est récompensé, et qui disparaît discrètement dans le système ?
C'est là qu'OpenLedger devient intéressant pour moi. Beaucoup de projets d'infrastructure en IA parlent des données comme si c'était juste du carburant. Collectez-le, nettoyez-le, nourrissez-le dans des modèles et créez quelque chose d'utile de l'autre côté. Mais les données ne sont pas neutres de cette manière. Elles proviennent de personnes, de communautés, d'habitudes, d'expertise, de travail et de contexte. Certaines sont publiques. D'autres sont spécialisées. Certaines ne deviennent précieuses que lorsqu'elles sont connectées à d'autres éléments. OpenLedger semble être construit autour de la croyance que cette valeur ne devrait pas disparaître une fois qu'elle entre dans un pipeline d'IA. Cette croyance est facile à approuver, mais très difficile à transformer en un système fonctionnel.
La partie la plus importante d'OpenLedger, du moins de mon point de vue, est l'attribution. Pas l'attribution comme un joli mot dans un discours, mais l'attribution comme un moteur économique. Si le projet peut montrer d'où viennent les données utiles, comment elles ont été utilisées et pourquoi elles comptent, alors il commence à créer une relation différente entre les contributeurs et les systèmes d'IA. Au lieu que les contributeurs soient traités comme des matières premières, ils deviennent partie de la structure. Leur contribution a une traçabilité. Leur réputation peut se construire. Leur travail peut éventuellement porter une valeur au-delà du moment où il est soumis.
Mais c'est aussi là que la difficulté commence. L'IA n'utilise pas toujours les données de manière propre et évidente. Une contribution peut ne pas compter seule, mais devenir utile dans le cadre d'un modèle plus large. Une autre contribution peut sembler petite mais être importante pour un modèle spécifique, un agent ou un cas d'utilisation. Une grande quantité de données peut sembler impressionnante mais offrir très peu de valeur réelle. OpenLedger doit faire face à ce milieu désordonné. Il doit trouver un moyen de séparer la contribution significative de l'activité simple. Ce n'est pas juste un défi technique. C'est le défi économique central du projet.
Parce qu'une fois que les récompenses, la réputation ou l'accès futur sont liés à la contribution, les gens commenceront naturellement à ajuster leur comportement. Certains essaieront de fournir de meilleures données. D'autres essaieront de comprendre ce que le système valorise. Certains contribueront avec une intention authentique. D'autres chercheront des raccourcis. Cela se produit dans presque toutes les économies de plateforme. Lorsque les avis comptent, les gens apprennent à manipuler les avis. Lorsque l'engagement compte, les gens apprennent à chasser l'engagement. Lorsque les classements comptent, les gens apprennent à optimiser pour les classements. Si la contribution compte dans OpenLedger, les gens finiront par apprendre comment réaliser de la contribution.
Cela ne signifie pas que le projet est faible. Cela signifie qu'OpenLedger doit être jugé par la manière dont il gère le comportement qu'il crée. Un bon système n'attire pas seulement des utilisateurs. Il les façonne. Si OpenLedger récompense la qualité, l'originalité et l'utilité, il pourrait encourager une meilleure participation. S'il récompense trop le volume, il pourrait attirer du bruit. S'il rend la réputation trop puissante, les premiers utilisateurs pourraient construire des avantages qui deviennent difficiles à contester pour les contributeurs ultérieurs. S'il rend les règles trop floues, les utilisateurs ordinaires pourraient participer sans vraiment comprendre ce qui donne de la valeur à leurs actions.
C'est pourquoi je pense que l'accès et la distribution sont si importants pour OpenLedger. Le projet peut être ouvert en théorie, mais l'ouverture ne signifie pas toujours une égalité des chances. Les personnes qui arrivent tôt, comprennent profondément le système ou disposent de meilleurs outils peuvent avancer beaucoup plus vite que tout le monde. Elles peuvent construire une réputation avant que la communauté plus large ne comprenne comment fonctionne la réputation. Elles peuvent apprendre quelles contributions comptent avant que ces signaux ne deviennent évidents. Dans ce genre d'environnement, le pouvoir peut se concentrer discrètement, non pas parce que le projet est conçu de manière injuste, mais parce que l'information est inégale.
Il y a aussi la question de la demande réelle. OpenLedger peut attirer des contributeurs, mais le projet ne devient durable que si la couche de données, d'attribution et le réseau de contributeurs sont utiles aux personnes qui construisent des systèmes d'IA. Les développeurs, les constructeurs de modèles, les agents, les applications et les entreprises doivent vouloir ce qu'OpenLedger organise. Sinon, l'économie risque de devenir trop interne. Les gens contribuent parce qu'ils s'attendent à une valeur plus tard. Le système semble actif parce que les gens contribuent. Mais le test plus profond est de savoir si la demande extérieure apparaît parce que la production est réellement utile.
C'est l'une des questions les plus inconfortables pour tout projet comme OpenLedger. L'offre peut être incitée. La demande doit être gagnée. Il est généralement plus facile d'amener les gens à participer à un réseau tourné vers l'avenir que de prouver que le réseau produit quelque chose dont les autres ont constamment besoin. Si OpenLedger peut connecter les contributeurs à une utilisation réelle de l'IA, alors le système a une base plus solide. Si ce n'est pas le cas, alors l'attribution pourrait devenir une belle idée sans suffisamment de gravité économique en dessous.
La gouvernance est un autre aspect qui compte plus qu'il n'y paraît au premier abord. Si OpenLedger traite de la contribution, de la valeur des données, de la réputation et de l'attribution, alors la gouvernance ne concerne pas seulement la gestion d'un protocole. Cela devient un moyen de décider de l'équité. Qui décide si une contribution est originale ? Qui gère les litiges lorsque des données similaires apparaissent de différentes personnes ? Qui décide ce qui est utile ? Que se passe-t-il lorsqu'un participant à haute réputation fait une soumission douteuse ? Que se passe-t-il lorsque de grands utilisateurs veulent des normes différentes de celles des petits contributeurs ? Ces décisions peuvent sembler techniques, mais elles façonnent la confiance de tout le système.
Le cas optimiste pour OpenLedger est clair pour moi. L'IA a besoin d'une meilleure provenance. Les contributeurs ont besoin de plus de visibilité. Le système actuel récompense souvent celui qui contrôle le produit final tout en ignorant les nombreuses contributions qui l'ont rendu possible. OpenLedger essaie au moins de rendre cet déséquilibre visible et peut-être plus corrigeable. Même si l'attribution parfaite est impossible, une meilleure attribution pourrait encore avoir de l'importance. Un système n'a pas besoin de tout résoudre pour améliorer la situation actuelle.
Mais je pense aussi que le risque est réel. Un projet qui suit la contribution peut encore devenir un endroit où les utilisateurs les plus informés gagnent le plus. Un système construit autour de la réputation peut encore devenir une hiérarchie. Un modèle de récompense peut encore déformer le comportement. Un réseau qui commence avec ouverture peut encore devenir dépendant d'un petit groupe de participants puissants, d'acheteurs, de validateurs ou de constructeurs. Ces risques ne suppriment pas le potentiel du projet, mais ils font partie de ce qu'OpenLedger devra prouver au fil du temps.
Ce qui rend OpenLedger intéressant à suivre, c'est qu'il fonctionne près d'un véritable point de pression. L'IA devient plus précieuse, mais la question de qui a contribué à cette valeur reste encore non résolue. Le projet essaie de placer une structure autour de cette couche manquante. Cela a du sens. Mais une structure seule n'est pas suffisante. La structure doit rester crédible lorsque les gens essaient de la contourner, lorsque les contributeurs rivalisent pour la reconnaissance, lorsque la demande devient sélective et lorsque la gouvernance doit prendre des décisions que tout le monde n'apprécie pas.
Donc, je ne vois pas OpenLedger comme quelque chose qui peut être compris uniquement à travers son récit public. L'idée est assez simple à expliquer, mais la réalité dépend des incitations, du comportement, de la demande et de la confiance. Il essaie de rendre la contribution visible dans une économie de l'IA qui cache souvent la contribution par conception. S'il peut le faire équitablement, durablement et sans créer un nouveau type de concentration, c'est encore une question ouverte. Pour l'instant, la chose la plus importante à surveiller n'est pas à quel point l'histoire semble forte, mais à quel point OpenLedger se maintient lorsque les gens à l'intérieur du système commencent à agir exactement comme les incitations leur enseignent à agir.