je veux parler de quelque chose de vraiment technique aujourd'hui parce que je pense que la conversation de surface autour d'OpenLedger manque où se situe réellement le véritable défi d'ingénierie. tout le monde parle des agents et de la propriété des données et de l'attribution. c'est juste. mais en dessous de tout cela, il y a deux problèmes d'infrastructure qui doivent être résolus correctement sinon aucune des choses intéressantes ne fonctionne à grande échelle.
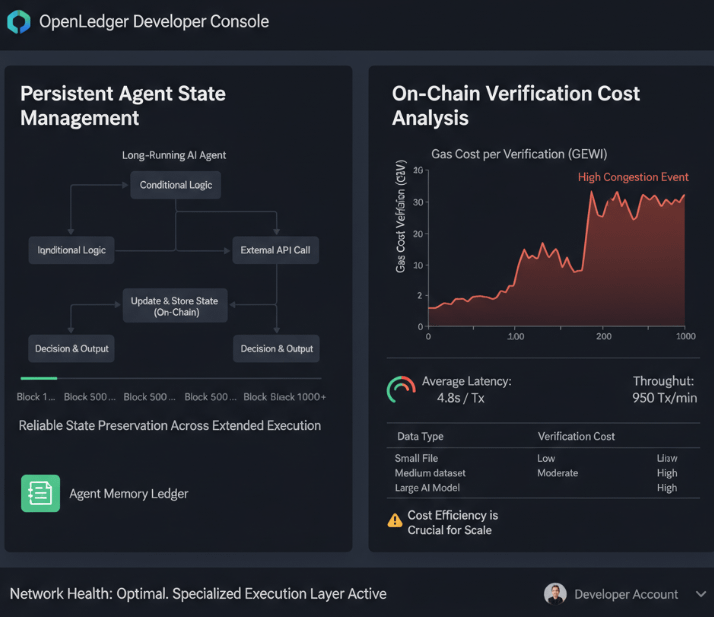
le premier est la gestion de l'état pour les agents à long terme.
les chaînes à usage général ont été conçues autour de transactions discrètes. quelque chose se produit, ça s'enregistre, c'est fait. le modèle mental est une entrée de registre. propre, limité, final. mais un agent IA faisant quelque chose de vraiment utile ne fonctionne pas de cette manière. un agent de trading surveillant les conditions du marché à travers plusieurs sessions, un agent de recherche tirant et traitant des données pendant des heures, un agent de coordination gérant les dépendances entre d'autres agents, ce ne sont pas des transactions discrètes. ce sont des processus en cours avec un état qui évolue continuellement et doit être préservé de manière fiable dans le temps sans que le réseau perde de vue où en sont les choses.
aucune chaîne à usage général n'a été construite avec ce cas d'utilisation en tête. Ethereum ne l'était pas. la plupart des L2 ne l'étaient pas. elles gèrent l'état au sein d'un bloc, au sein d'une transaction, au sein d'un appel de contrat. mais l'état des agents persistant sur des périodes de temps prolongées avec des branches conditionnelles et des dépendances de données externes est un problème complètement différent. L'architecture d'OpenLedger est spécifiquement conçue autour de cela, c'est pourquoi les décisions concernant l'environnement d'exécution importent beaucoup plus que les gens ne le réalisent lorsqu'ils se contentent de regarder le prix du token.

le deuxième problème est le coût réel de la vérification des données on-chain et personne n'en parle dans le deck marketing parce que les chiffres ne sont pas jolis.
chaque donnée qui est attribuée, vérifiée et enregistrée on-chain coûte quelque chose. gaz, latence, capacité de traitement. et quand tu construis un réseau où la contribution de données est l'activité économique principale, ces coûts ne sont pas des cas marginaux. ce sont l'événement principal. si la vérification est coûteuse, les petits contributeurs sont exclus. si c'est lent, les workflows des agents qui dépendent de données vérifiées récentes se dégradent. si la capacité de traitement est limitée, le réseau se congestione exactement au moment où l'adoption augmente, ce qui est le pire moment pour une hausse des frais.
la raison pour laquelle ces deux problèmes sont connectés est que le coût de la gestion d'état et de la vérification se situe tous deux au même niveau. l'environnement d'exécution. si tu arrives à bien gérer cette couche, les deux problèmes deviennent gérables. si tu te trompes, tu finis avec un réseau qui fonctionne parfaitement dans une démo contrôlée et commence à fuir de la valeur au moment où une utilisation réelle exerce une pression sur lui.
ce qui me donne confiance dans l'approche d'OpenLedger, c'est que ce ne sont pas des problèmes qu'ils ont rencontrés par hasard. Les décisions architecturales prises autour d'une exécution spécialisée plutôt que d'un déploiement général de chaîne suggèrent que l'équipe a cartographié ces points de pression tôt et construit autour d'eux plutôt que d'espérer qu'ils n'importent pas. C'est généralement la différence entre une infrastructure qui tient et une infrastructure qui s'excuse.
le modèle économique ne cesse de fuir que lorsque la couche technique en dessous est honnête sur ses propres coûts. OpenLedger est honnête à ce sujet d'une manière que la plupart des projets dans cet espace ne le sont pas.