I’ll be honest.
For a long time, I thought the AI race would end the same way every big tech race usually ends.
Bigger models win.
Cheaper compute crushes everyone underneath scale.
The companies with the deepest infrastructure stacks absorb the market.
Simple.
That’s how these things usually go, right?
But the more I looked into OpenLedger, the more I started second-guessing that whole assumption.
Because here’s the thing people don’t talk about enough:
Intelligence itself might become cheap.
Not bad.
Not useless.
Just… abundant.
And once something becomes abundant, markets stop paying premium prices for it.
That’s basic economics.
We already watched this happen with storage.
Bandwidth.
Content.
Cloud infrastructure.
At first it feels rare and powerful.
Then suddenly everybody has it.
AI honestly feels like it’s heading toward the same wall.
And that’s where OpenLedger gets interesting.
Not because it’s “AI + blockchain.” I’ve seen that pitch a thousand times already. Most of it is noise.
What caught my attention is something deeper.
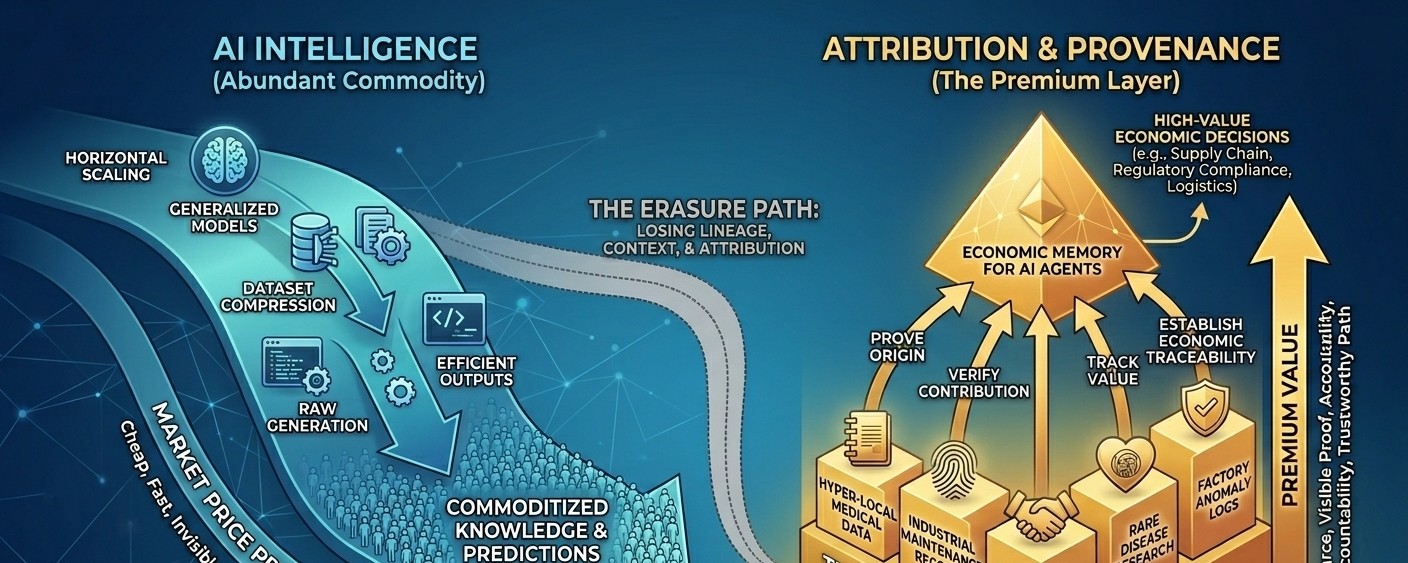
OpenLedger seems to understand that the real scarcity might not be intelligence anymore.
It might be attribution.
Proof.
Context.
The ability to prove where something came from and how it actually formed.
That sounds small at first.
It isn’t.
Modern AI systems have a massive compression problem.
Actually, “massive” might be understating it.
These systems compress huge amounts of human knowledge into outputs so aggressively that most of the path disappears entirely.
The answer survives.
The process doesn’t.
And honestly, that’s kind of terrifying once money starts depending on AI decisions at scale.
Think about how these models work.
Huge datasets become embeddings.
Embeddings become weighted relationships.
Those relationships eventually generate outputs.
Cool.
But during that entire process, something important gets flattened.
Contribution history.
Who added value?
Which dataset mattered most?
Which source corrected an error?
Which edge-case changed the outcome?
Most systems can’t answer that clearly.
The intelligence survives.
The lineage disappears.
And look, maybe that doesn’t matter when AI generates anime pictures or random social posts.
Fine.
But what happens when AI starts operating inside real economic systems?
Medical systems.
Supply chains.
Insurance underwriting.
Industrial manufacturing.
Defense logistics.
Different game entirely.
At that level, provenance stops being some philosophical debate tech people have on podcasts.
It becomes infrastructure.
Legal infrastructure.
Financial infrastructure.
Regulatory infrastructure.
Because once AI agents start making decisions with real-world consequences, people are going to ask very uncomfortable questions.
Where did this output come from?
Which datasets influenced this model?
Who trained it?
Who gets paid if it succeeds?
Who takes responsibility if it fails?
Right now, most AI systems honestly suck at answering those questions.
They generate outputs beautifully.
But they destroy context while doing it.
That’s the tradeoff nobody wants to talk about.
Compression creates efficiency.
Compression also erases history.
And OpenLedger seems built around preserving parts of that missing history instead of pretending the problem doesn’t exist.
That’s what makes it structurally interesting to me.
Not hype-interesting.
Infrastructure-interesting.
There’s a difference.
A lot of crypto projects still think value comes from horizontal scale alone.
More users.
More throughput.
More transactions.
But historically, the deepest value usually accumulates vertically.
Inside narrow, ugly, highly specialized systems nobody on Twitter talks about.
Hyper-local medical data.
Industrial maintenance records.
Private manufacturing datasets.
Rare disease research.
Factory anomaly detection logs.
Weird little pockets of information that general AI models can’t easily reproduce.
That’s where things get tricky.
Because generalized intelligence scales horizontally really well.
Eventually everyone gets access to it.
But specialized context?
That accumulates privately.
Quietly.
And the organizations controlling that context end up holding disproportionate economic leverage.
People underestimate this constantly.
The future AI economy probably won’t belong to whoever owns the “smartest” model.
Honestly, that framing already feels outdated.
The real winners might be the systems that can preserve attribution while everything else gets compressed into statistical sludge.
Yeah, harsh wording.
But accurate.
And OpenLedger seems to be positioning itself around exactly that problem.
Creating infrastructure where datasets, models, and agents can actually retain economic traceability instead of dissolving into black-box outputs.
That matters more than people realize.
Especially once autonomous AI agents start interacting with each other financially.
Imagine thousands of AI agents negotiating supply contracts, analyzing risks, allocating capital, handling logistics.
Sounds efficient.
Also sounds like a regulatory nightmare if nobody can track contribution lineage anymore.
And here’s the uncomfortable part:
The more advanced AI becomes, the harder attribution gets.
That’s the paradox.
Better systems create blurrier origins.
The output looks cleaner while the underlying contribution graph becomes harder to untangle.
So eventually markets compensate for that uncertainty.
They start pricing trust.
Pricing provenance.
Pricing verifiable lineage.
That’s where the economic weight shifts.
Not toward raw generation.
Toward evidence.
Honestly, I think people are still mentally stuck in the “bigger model = bigger moat” phase of AI.
Maybe that works short term.
I’m not convinced it works forever.
Because once intelligence becomes widely accessible, trust becomes the premium layer.
Always.
And trust requires traceability.
The internet already taught us this lesson once.
Social media compressed credibility into engagement metrics.
Search engines compressed expertise into ranking systems.
Now AI compresses knowledge into generated responses.
Every layer increases convenience.
Every layer also weakens source visibility.
The path gets thinner each time.
Eventually somebody rebuilds the missing infrastructure.
That’s usually how these cycles go.
And maybe that’s what OpenLedger is really trying to do.
Not build another AI chain.
Build economic memory for AI systems before compression erases too much of the path completely.
Honestly, the deeper implication here feels bigger than crypto.
Because if AI eventually turns intelligence into a commodity, then attribution might become one of the most expensive assets on earth.
Not intelligence itself.
Proof of origin.
Proof of contribution.
Proof that something came from a trusted path instead of simply looking convincing enough statistically.
And the weird part?
I don’t think most markets are prepared for that transition yet.
People still focus on outputs because outputs are visible.
Lineage isn’t.
But invisible infrastructure usually becomes the thing civilization depends on later.
Quietly at first.
Then all at once.
So maybe the real question isn’t which AI system becomes smartest.
Maybe the real question is which systems can still preserve accountability after everything gets compressed beyond recognition.
Because those systems might end up controlling the economic layer underneath AI itself.

