
Écoute, j'ai couvert la technologie suffisamment longtemps pour me rappeler quand l'informatique en nuage allait tout changer. Puis c'était les réseaux sociaux. Ensuite, les grandes données. Puis les NFT. Puis le métavers. Maintenant, c'est l'IA combinée avec la blockchain.
Chaque cycle arrive avec la même confiance. Cette fois, c'est différent. Cette fois, la technologie résout enfin les problèmes que les technologies précédentes ne pouvaient pas. Cette fois, les incitations s'alignent.
J'ai déjà vu ce film.
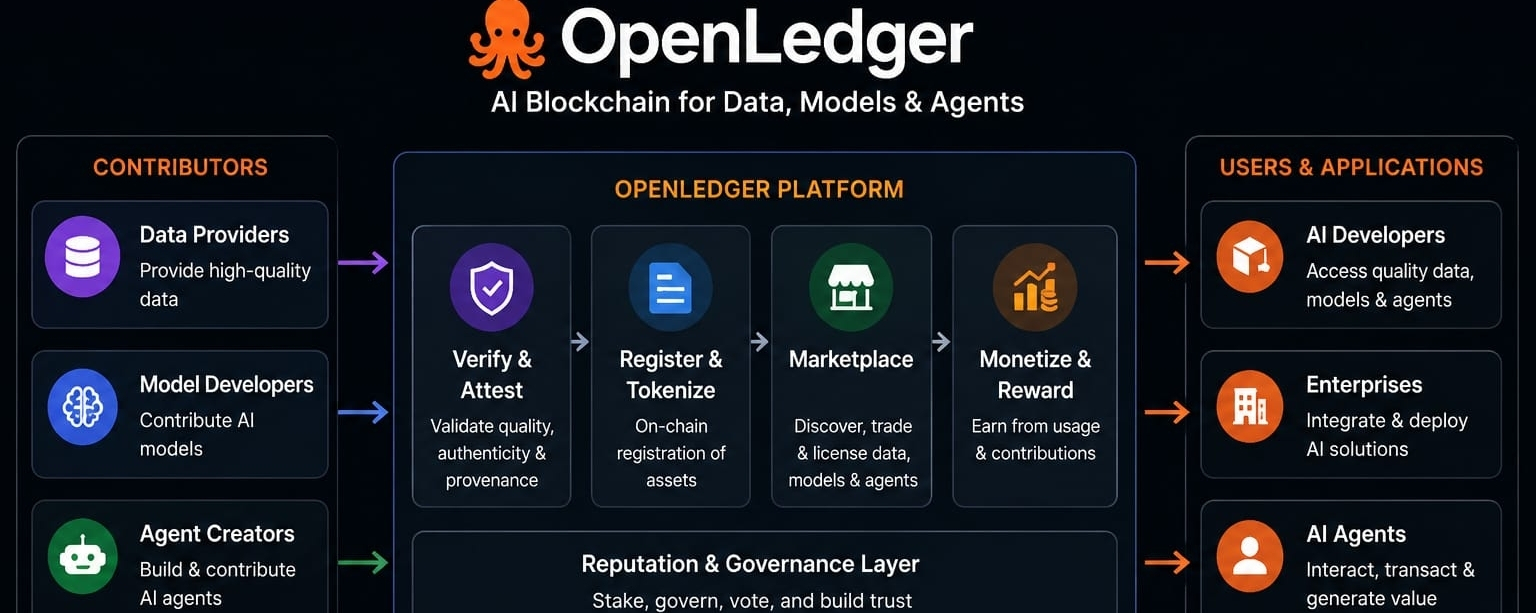
Le pitch d'OpenLedger semble assez simple. L'intelligence artificielle fonctionne sur des données. Les gens qui créent ou contribuent à ces données reçoivent souvent peu de compensation. Les grandes entreprises technologiques capturent la majeure partie de la valeur. Donc, construisez un système basé sur la blockchain où les données, les modèles IA et les agents autonomes deviennent des actifs négociables, et soudainement, tout le monde obtient une part plus équitable du gâteau.
Ça a l'air soigné.
Sur le papier, du moins.
Mais quand vous commencez à tirer sur les fils, l'histoire devient beaucoup plus compliquée.
Le problème central que OpenLedger prétend résoudre est réel. C'est important de le reconnaître. Les systèmes d'IA consomment d'énormes quantités d'informations. La plupart de ces informations viennent de quelque part. Les individus les créent. Les entreprises les génèrent. Les communautés y contribuent. Pourtant, les récompenses économiques tendent à aller vers les entreprises qui possèdent les plateformes et l'infrastructure.
Personne ne conteste sérieusement cela.
Le problème est ce qui vient ensuite.
OpenLedger suppose que parce que quelque chose a de la valeur, il peut être transformé en marché. C'est là que les choses commencent à devenir compliquées.
Prenez les données elles-mêmes. Tout le monde parle des données comme si c'était une marchandise. Ce n'est pas le cas. Le pétrole est une marchandise. Le blé est une marchandise. L'or est une marchandise. Les données sont dépendantes du contexte. Le même ensemble de données peut valoir des millions pour une entreprise et absolument rien pour une autre.
Alors, la question évidente devient : qui décide de la valeur d'un ensemble de données ?
Le matériel marketing saute généralement cette partie.
C'est parce que les données de prix sont difficiles. Vraiment difficiles.
Imaginez deux ensembles de données de santé. L'un contient des informations qui aident à former un système de diagnostic. L'autre contient des dossiers incomplets collectés à partir de systèmes obsolètes. L'un pourrait être extrêmement précieux. L'autre pourrait être presque inutile. Pourtant, les deux peuvent être emballés, tokenisés, échangés et promus à l'intérieur d'un marché.
La blockchain ne résout pas ce problème.
Ça enregistre simplement des transactions.
C'est là que de nombreux projets crypto substituent discrètement la technologie à l'économie. Ils construisent des systèmes sophistiqués pour déplacer des actifs tout en évitant la question plus difficile de savoir si ces actifs peuvent être valorisés de manière cohérente en premier lieu.
Et puis il y a la question des incitations.
Soyons honnêtes.
Chaque fois qu'un projet introduit un token, je veux immédiatement savoir qui en possède la majorité.
Pas parce que les tokens sont intrinsèquement mauvais. Parce que les incitations comptent.
L'histoire publique se concentre généralement sur la participation communautaire et la propriété décentralisée. La réalité privée implique souvent des investisseurs précoces, des fonds de capital-risque, des fondations, des initiés et des partenaires stratégiques détenant des portions significatives de l'offre bien avant l'arrivée des participants ordinaires.
Cela ne rend pas automatiquement un projet illégitime.
Mais cela soulève des questions.
Si l'écosystème devient réussi, qui en bénéficie le plus ? Les milliers de futurs contributeurs fournissant des données ? Ou le groupe relativement restreint qui a acquis des positions avant que le marché plus large n'apparaisse ?
Ce ne sont pas la même chose.
Puis nous arrivons à l'un des mots préférés de la blockchain.
Décentralisation.
J'ai passé des années à entendre ce mot appliqué à des systèmes qui n'étaient en rien décentralisés.
Si vous regardez de près, de nombreux réseaux supposément décentralisés dépendent d'un petit groupe de développeurs, de validateurs, de participants à la gouvernance, de fournisseurs d'infrastructure ou de membres de fondations. La prise de décision devient concentrée même lorsque la propriété semble distribuée.
OpenLedger fait face au même défi.
Parce que les systèmes d'IA ne se gouvernent pas magiquement.
Quelqu'un détermine les normes. Quelqu'un vérifie la qualité des données. Quelqu'un décide quelles contributions méritent des récompenses. Quelqu'un met à jour le logiciel. Quelqu'un résout les litiges.
Des êtres humains se cachent derrière tous ces processus.
Plus le réseau devient précieux, plus ces décisions deviennent importantes.
Et le pouvoir a tendance à se concentrer autour des décisions importantes.
Ce n'est pas un problème de blockchain. C'est un problème humain.
Maintenant, parlons de la partie que presque personne n'aime aborder.
Que se passe-t-il quand les choses tournent mal ?
Parce qu'ils le font toujours.
Imaginez qu'un contributeur télécharge des données trompeuses. Imaginez qu'un modèle d'IA formé sur ces données produise des résultats nuisibles. Imaginez que les revendications de propriété deviennent contestées. Imaginez que les régulateurs décident que certains ensembles de données violent les lois sur la vie privée. Imaginez que des poursuites pour propriété intellectuelle commencent à apparaître autour du contenu généré par l'IA.
Qui est responsable ?
La blockchain ?
Les détenteurs de tokens ?
Les développeurs ?
Les contributeurs ?
La réponse est généralement moins claire que la présentation marketing ne le suggère.
Les projets technologiques supposent souvent que la transparence crée de la responsabilité.
Ça ne l'est pas.
Un système parfaitement transparent peut quand même prendre de mauvaises décisions.
Un registre public peut montrer exactement comment un désastre s'est produit tout en n'offrant aucun moyen pratique de le prévenir.
C'est particulièrement pertinent pour l'IA, où les conséquences de mauvaises informations peuvent se propager rapidement à travers des systèmes automatisés.
Et puis il y a la plus grande question de toutes.
Les gens veulent-ils réellement cela ?
Cela peut sembler injuste, mais ça compte.
De nombreux projets blockchain commencent avec l'hypothèse que les utilisateurs ont désespérément besoin d'alternatives décentralisées. Puis ils passent des années à découvrir que la plupart des utilisateurs privilégient la commodité, la rapidité, la fiabilité et la simplicité à la pureté idéologique.
La moyenne des entreprises ne se lève pas en demandant une infrastructure de données tokenisées.
Le développeur moyen ne passe pas des nuits sans sommeil à souhaiter que ses ensembles de données vivent sur une blockchain.
Ils veulent des solutions qui réduisent les coûts, améliorent l'efficacité et créent une valeur mesurable.
Si OpenLedger peut accomplir cela, il a une chance.
S'il ajoute simplement une autre couche de tokens, de systèmes de gouvernance, de portefeuilles, de mécanismes de vérification, d'exigences de staking et de complexité de marché, l'adoption devient une vente beaucoup plus difficile.
Parce que la complexité coûte cher.
Les gens sous-estiment cela.
Chaque couche supplémentaire introduit des frictions. Chaque nouveau système crée un autre point d'échec potentiel. Chaque incitation économique crée des opportunités de contourner les règles.
Le piège, alors, n'est pas caché dans la technologie.
C'est caché dans l'hypothèse.
L'hypothèse selon laquelle les problèmes de propriété des données sont principalement des problèmes d'infrastructure.
Ils peuvent ne pas l'être.
Beaucoup d'entre eux sont des problèmes juridiques. Des problèmes économiques. Des problèmes de gouvernance. Des problèmes humains.
La blockchain peut enregistrer des revendications de propriété. Elle ne peut pas garantir que les tribunaux les reconnaissent.
La blockchain peut suivre les contributions. Elle ne peut pas garantir que ces contributions aient une valeur significative.
La blockchain peut distribuer des récompenses. Elle ne peut pas garantir que ces récompenses créent un comportement durable.
J'ai suffisamment observé des cycles technologiques pour savoir que construire un marché est généralement beaucoup plus difficile que de construire une plateforme. OpenLedger peut réussir à créer une infrastructure impressionnante. Le plus grand défi est de convaincre suffisamment de personnes que l'infrastructure résout un problème qu'elles ont vraiment.
Parce que l'histoire est pleine de systèmes techniquement élégants qui n'ont jamais trouvé de marché.
Et les marchés ont tendance à ignorer les idées qui semblaient brillantes dans un livre blanc.
\u003cm-151/\u003e \u003ct-153/\u003e\u003cc-154/\u003e