I’ll be honest.
I think most people started from the wrong assumption about AI infrastructure. I definitely did.
For a long time, I thought the winners would just be whoever trained the biggest models, bought the most compute, and pushed inference costs down faster than everyone else. Simple. Bigger systems usually crush smaller systems. That’s how tech tends to work.
But the more I looked at OpenLedger, the more that whole theory started feeling incomplete.
Because honestly? Intelligence itself might not be the scarce thing anymore.
Recoverability might be.
That’s where things get interesting.
People keep obsessing over generation. Smarter models. Faster outputs. Better agents. Cool demos. All that stuff. But almost nobody talks about what happens after information disappears into the noise.
And I don’t mean literally deleted.
I mean buried.
There’s a huge difference.
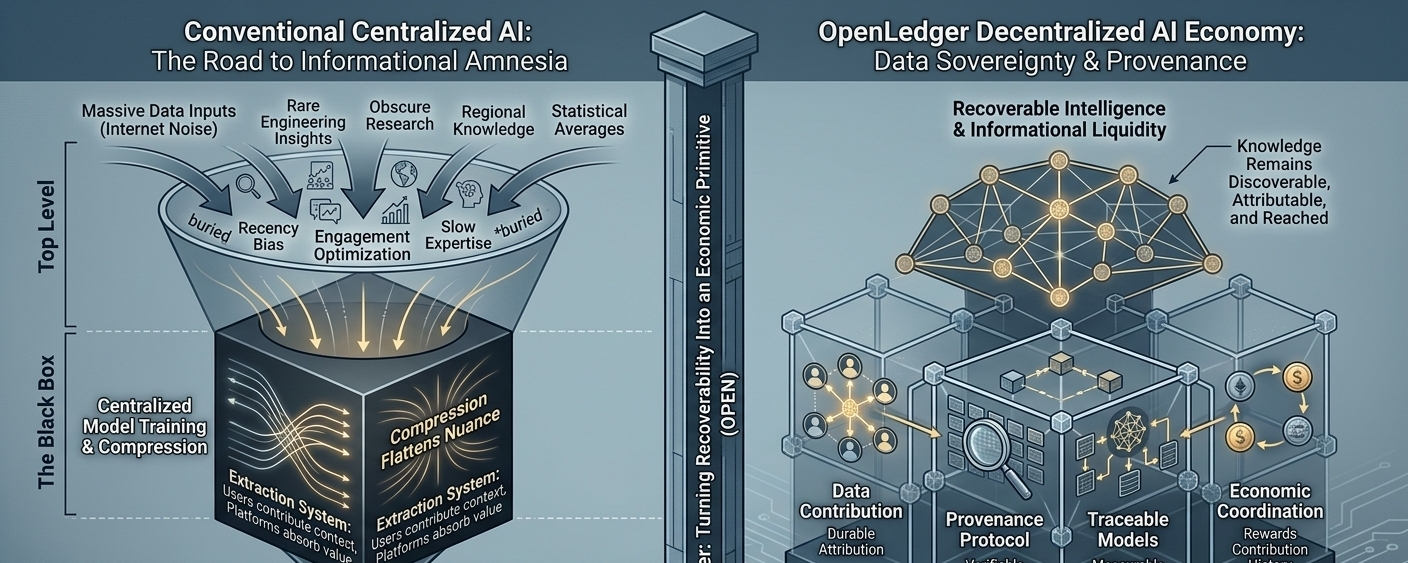
The internet already has more information than anyone can process. That’s not the problem anymore. The real problem is that modern systems only surface what fits their own structure. What’s recent. What gets engagement. What compresses cleanly into ranking systems and training pipelines.
Everything else slowly fades into the background.
A weird research thread from 2014.
An obscure engineering insight buried in a forum nobody visits anymore.
Regional knowledge that never made it into dominant datasets.
Slow expertise.
That stuff dies quietly.
Not because it lacks value. Because it lacks visibility.
And AI models inherit that bias whether people want to admit it or not. Models don’t magically learn “truth.” They learn what survived filtration. They absorb what platforms repeatedly expose. That’s a completely different thing.
“The system remembers what the market keeps rewarding.”
People don’t talk about this enough.
Most AI systems today optimize around legibility, not depth. If something can’t be structured easily, ranked quickly, or compressed efficiently, the system starts ignoring it. Over time, entire categories of valuable knowledge become economically invisible.
That’s why OpenLedger caught my attention.
Not because it’s another “AI + blockchain” project. Honestly, crypto has produced enough empty AI narratives already. Everyone suddenly slaps “AI infrastructure” onto a token and calls it the future. I’ve seen this before.
But OpenLedger feels different because it’s solving a deeper problem.
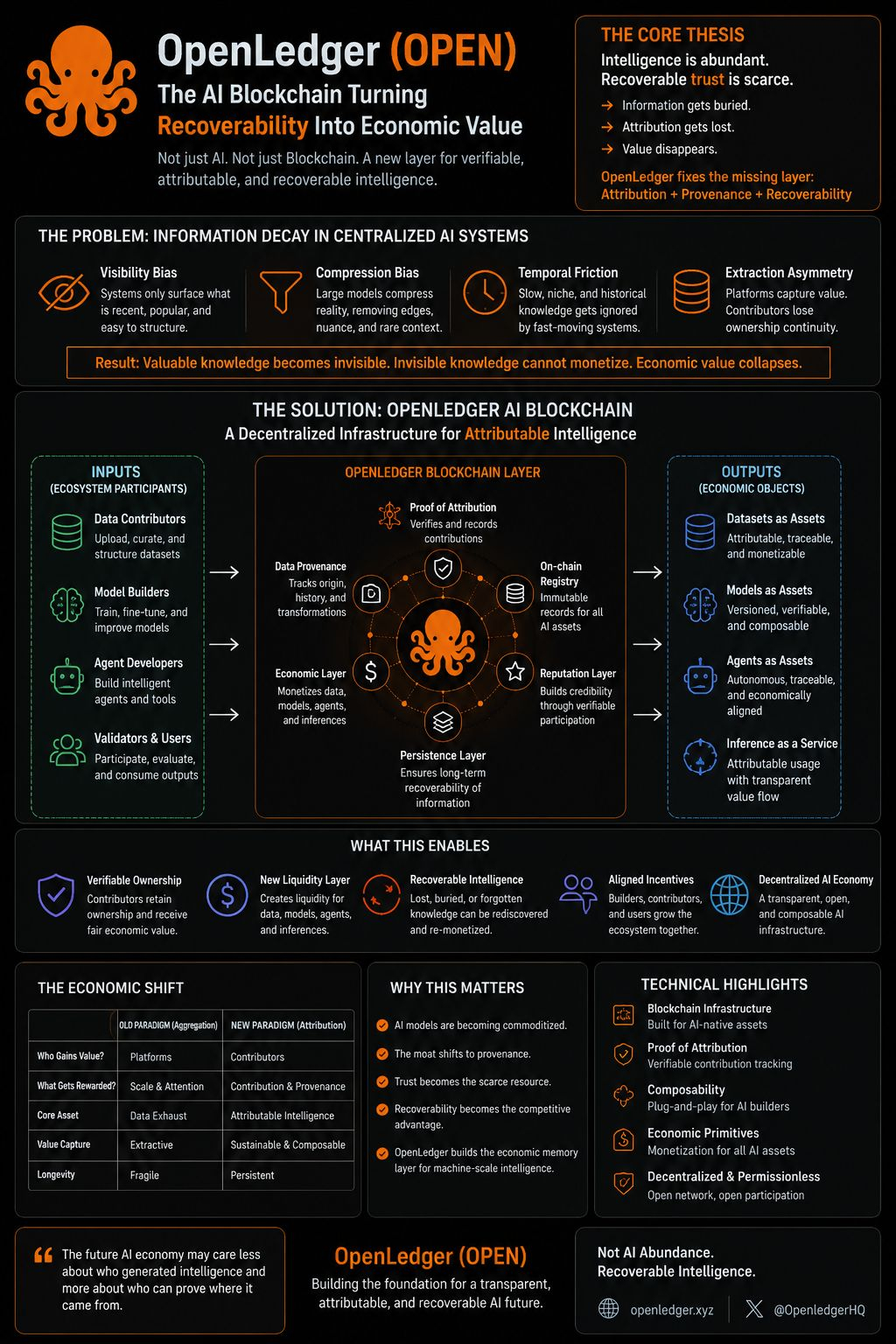
It’s trying to turn attribution, provenance, and recoverability into actual economic infrastructure.
That’s a much bigger idea than people realize.
Look, here’s the thing.
Most internet platforms built extraction systems disguised as participation systems. Users contributed data, behavior, knowledge, and context while centralized platforms absorbed the value. Over time, contributors lost ownership continuity while the platforms accumulated intelligence.
You trained the machine.
The machine owned the output.
That became normal somehow.
OpenLedger seems built around reversing part of that equation. Not through marketing slogans. Through infrastructure design.
Datasets become attributable.
Models become traceable.
Agents become persistent economic actors.
Contributions become measurable state instead of disposable exhaust.
And once you frame it that way, the blockchain part suddenly makes a lot more sense.
The chain isn’t there just to tokenize things for the sake of tokenization. It acts more like a persistence layer for informational ownership and economic coordination.
That matters because AI capability itself is already becoming commoditized faster than people expected.
Open-source models keep improving.
Inference keeps getting cheaper.
Fine-tuning keeps getting easier.
Agent frameworks keep multiplying.
The moat around raw intelligence is shrinking.
So where does value go next?
Honestly, probably toward provenance.
Toward recoverable trust.
Toward proving where information came from and who contributed to it.
“The next AI economy may care less about who generated intelligence and more about who can verify its lineage.”
That shift changes everything.
Because aggregation and attribution create completely different systems.
Aggregation rewards whoever controls the platform.
Attribution rewards whoever can preserve contribution history.
Big difference.
And this is where OpenLedger starts feeling less like a normal crypto network and more like an attempt to build economic memory for AI systems before everything collapses into opaque black-box infrastructure.
That sounds dramatic. Maybe it is a little. But I genuinely think people underestimate how dangerous compression bias becomes at scale.
Large models compress reality. That’s literally what they do. They reduce massive amounts of information into generalized representations that inference systems can use efficiently.
Efficient doesn’t always mean accurate though.
Compression removes edges.
It removes weirdness.
It removes historical friction.
And sometimes the weird edge cases matter most.
Averages flatten nuance. Optimization favors repetition. Systems naturally amplify whatever appears most statistically stable. That creates blind spots over time, especially for localized knowledge, historical expertise, and slow-moving domains that don’t generate constant engagement.
Honestly, this is where things get tricky.
Because once AI systems become the dominant interface layer for information retrieval, they also become gatekeepers of recoverability. The machine decides what gets surfaced and what quietly disappears below visibility thresholds.
That’s not just a technical issue.
It’s a power issue.
Who controls informational routing?
Who decides which datasets matter?
Which histories stay accessible?
Which contributions remain attributable after recursive model training?
Those questions sit underneath almost every future AI infrastructure debate whether people realize it or not.
And OpenLedger seems weirdly aware of that.
The project keeps circling around this idea that intelligence production needs durable attribution layers before recursive AI ecosystems completely blur authorship, provenance, and contribution lineage.
Because once agents start training agents and models start refining outputs from other models, informational ownership gets messy fast.
Without attribution, trust erodes.
Without provenance, verification collapses.
Without recoverability, knowledge fragments.
And honestly, I think that’s the real risk people ignore when they talk about infinite AI abundance.
Abundance creates noise.
Massive noise.
If synthetic generation becomes effectively infinite, then recoverable trust becomes the scarce layer. Not content generation. Not raw outputs. Trust.
Can you trace where information originated?
Can you verify who contributed?
Can you recover forgotten context after attention moved elsewhere?
That’s the actual battle.
And OpenLedger’s architecture seems designed around exactly that tension.
Not just liquidity of capital.
Liquidity of intelligence.
That phrase sounds abstract at first, but stick with me for a second.
Traditional liquidity means assets move efficiently through markets. Informational liquidity means knowledge remains discoverable, attributable, and economically reachable even after visibility systems move on.
That’s harder than people think.
Most information online technically still exists. But functionally? It’s gone. Buried under algorithmic prioritization systems optimized for recency and engagement velocity.
The internet confuses storage with preservation all the time.
They’re not the same thing.
An archive nobody can recover from might as well be dead.
And honestly, that’s why OpenLedger feels important to me. Not because it promises some magical AI future. Not because of hype cycles. Definitely not because of generic “decentralized AI” talking points.
It feels important because it assumes something most systems still ignore:
Intelligence without recoverability eventually collapses into informational amnesia.
That line keeps sticking in my head.
Civilizations don’t only fail when knowledge disappears. They fail when people lose the ability to recover what already existed. When memory fragments faster than systems can reconstruct it, societies start rebuilding partial understanding from compressed leftovers.
AI could accidentally accelerate that exact pattern.
Especially if centralized systems become the dominant memory layer for machine intelligence.
That’s why attribution matters.
That’s why provenance matters.
That’s why persistence matters.
And that’s why OpenLedger feels less like a normal blockchain project and more like infrastructure trying to preserve economic continuity inside machine-scale intelligence systems before abstraction layers swallow everything underneath them.
Honestly, I think that’s the real thesis here.
Not AI abundance.
Recoverable intelligence.