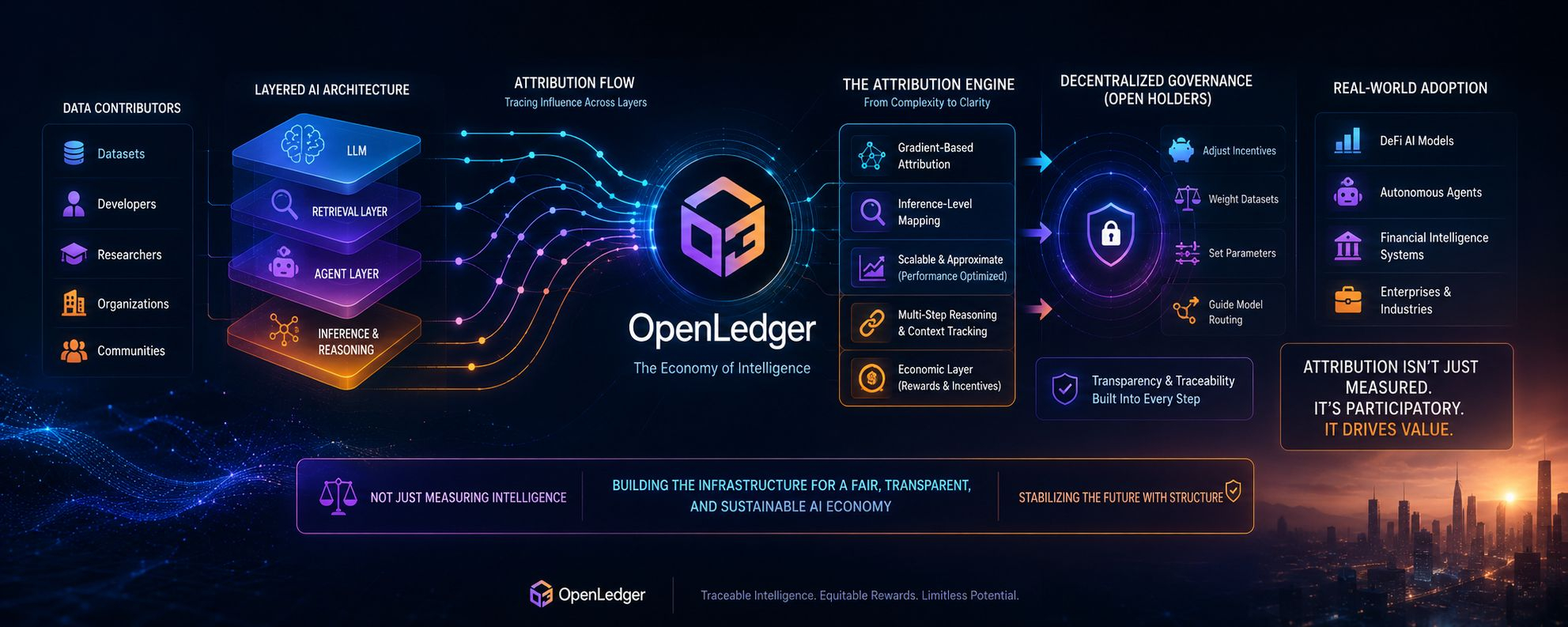

Je reviens sans cesse à une question qui semble presque trop précise au premier abord, comme quelque chose que tu pourrais répondre avec un diagramme ou un papier :
Comment l'attribution survit-elle réellement une fois que l'intelligence commence à circuler à travers de grands modèles superposés en mouvement ?

Au départ, je l'imagine comme propre. Un traçage d'attribution basé sur des gradients qui influence en arrière à travers les poids, mappant les sorties aux signaux d'entraînement, construisant une sorte de mémoire structurée de contribution. Et dans un petit système, peut-être que ça tient. Peut-être que ça semble même fiable.
Mais ensuite, je l'augmente dans ma tête.
Grands LLMs. Raisonnement à plusieurs étapes. Couches de récupération. Boucles d'agents. Chaînes de sortie alimentant les futures entrées.
Et soudain, je ne regarde plus une carte.
Je regarde un brouillard qui insiste encore sur le fait qu'il a une structure.
C'est là que ça commence à sembler différent.
Parce que je continue à demander :
Comment l'attribution basée sur le gradient se comporte-t-elle réellement lorsqu'elle doit évoluer à travers des modèles qui se redéfinissent constamment par l'usage ?
L'idée suppose une continuité. Mais les grands modèles ne se comportent pas comme des systèmes statiques. Ils évoluent par le biais d'un ajustement fin, à travers des schémas d'inférence, par un renforcement indirect de la façon dont ils sont utilisés dans le monde réel. Donc, l'attribution n'est plus juste un traçage en arrière - c'est essayer de tracer quelque chose qui avance aussi.
Et je ne sais pas si ces directions sont compatibles.
Puis une autre question interrompt cette pensée :
L'attribution peut-elle être calculée sans dégrader les performances ?
Et honnêtement, je comprends pourquoi c'est une contrainte. Un traçage complet à chaque couche serait coûteux en calcul, peut-être même impraticable. Mais l'optimisation des performances introduit toujours une pression vers la simplification. Vers l'échantillonnage au lieu de la reconstruction complète. Vers des approximations qui semblent suffisamment précises jusqu'à ce que vous les inspectiez vraiment.
Et cette partie a du sens pour moi.
Mais cela change aussi ce que ce système est réellement.
Parce qu'une fois que vous commencez à approximater l'attribution, vous ne mesurez plus l'influence exacte. Vous l'estimez sous des contraintes. Ce qui signifie que la couche économique construite sur l'attribution dépend désormais de quelque chose de probabiliste, pas déterministe.
Puis je pense à mapper les sorties aux données d'entraînement.
Comment OpenLedger décide-t-il réellement ce qui a "causé" une sortie spécifique ?
Dans des modèles à étape unique, cela peut sembler simple. Mais dans des systèmes de raisonnement à plusieurs étapes, les sorties sont émergentes. Elles sont construites à travers des états intermédiaires qui ne correspondent pas toujours proprement à un ensemble de données ou à un contributeur unique.
Alors je continue à me demander :
Que devrait capturer l'attribution au niveau de l'inférence lorsque l'inférence elle-même est une chaîne de transformations plutôt qu'un seul calcul ?
Et je ne pense pas qu'il y ait une frontière nette là.
On a l'impression que l'attribution commence à se brouiller avec l'interprétation.
Puis la gouvernance entre en jeu.
Quelles décisions les détenteurs d'OPEN contrôlent-ils réellement ? Paramètres ? Ajustements d'incitations ? Pondération des ensembles de données ? Règles de routage des modèles ? Plus j'y pense, plus la gouvernance semble moins être un contrôle direct et plus comme des contraintes de direction autour d'un système qui s'auto-organise déjà par l'usage.
Cela crée un léger décalage.
Le contrôle existe.
Mais elle est distribuée à travers des couches qui ne s'exposent pas entièrement en une seule fois.
Et puis je commence à penser à l'adoption.
Des industries se construisant sur OpenLedger. Modèles DeFi AI. Agents automatisés interagissant avec la logique financière. Systèmes qui dépendent non seulement de l'intelligence, mais de l'intelligence traçable.
Cela soulève une autre question :
Que se passe-t-il lorsque l'attribution devient partie intégrante de l'infrastructure financière plutôt qu'un simple outil de mesure ?
Parce qu'une fois que l'attribution influence directement les flux économiques, elle cesse d'être purement descriptive. Elle devient participative. Elle commence à façonner les incitations tout en essayant simultanément de les mesurer.
Cela change ce que ce système est réellement.
Je continue à revenir à la même tension sous-jacente :
Si l'attribution est approximative, évolutive et économiquement intégrée, décrit-elle toujours l'intelligence… ou stabilise-t-elle simplement une version de celle-ci que le système peut se permettre de mesurer ?
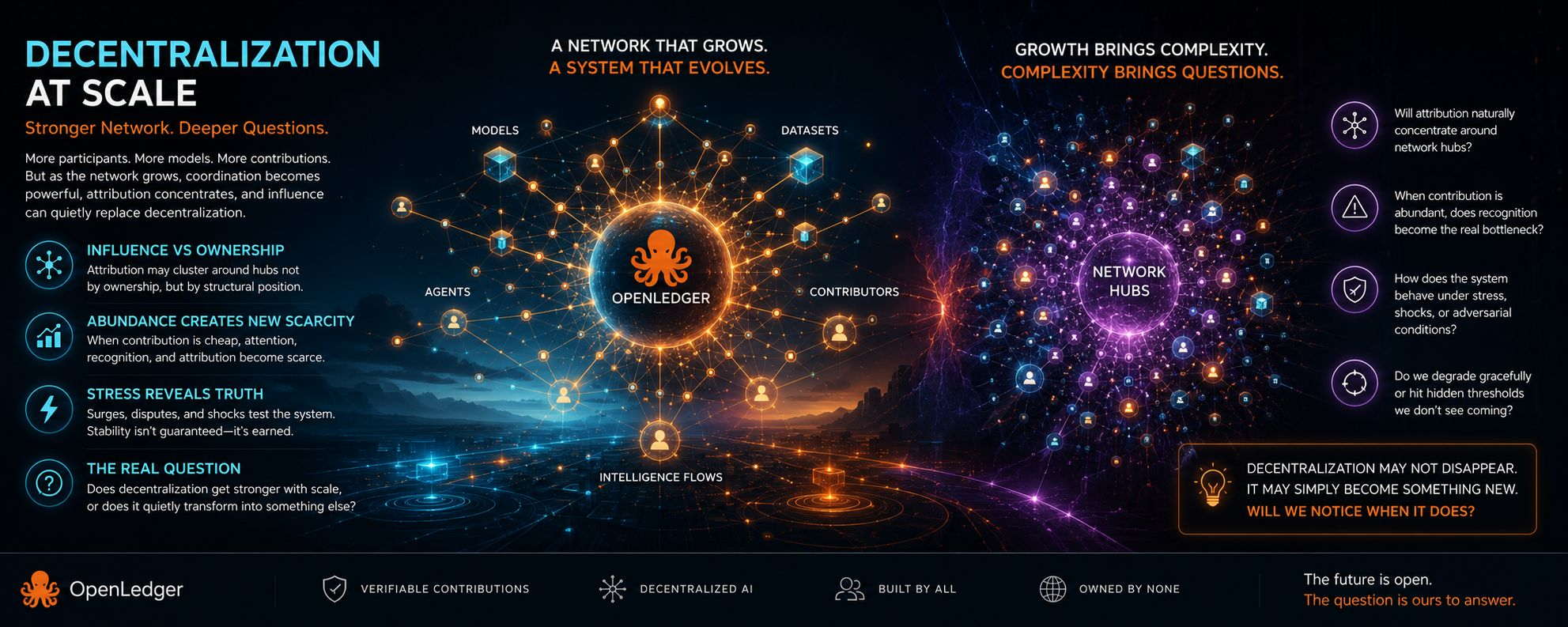
Et je ne peux pas me débarrasser du sentiment que la réponse compte moins en théorie qu'en accumulation.
Parce qu'à grande échelle, de petites approximations cessent de se comporter comme des erreurs.
Ils commencent à se comporter comme une structure.
Et je ne suis pas sûr de l'endroit où cette structure mène finalement.
