Je pense que l'une des plus grandes questions dans l'IA n'est pas seulement "qui a construit le modèle ?" mais "quelles données ont aidé le modèle à devenir utile ?"
Cette question est restée dans ma tête quand j'ai regardé @OpenLedger .
La plupart des modèles d'IA ne deviennent pas utiles par magie. Ils ont besoin de données. Ils ont besoin d'exemples. Ils ont besoin de signaux de vraies personnes, de vraies communautés et de cas d'utilisation réels. Mais le truc étrange, c'est que le contributeur de données est souvent poussé dans l'ombre une fois que le modèle commence à générer de la valeur.
Je pense qu'il y a une lacune sérieuse.
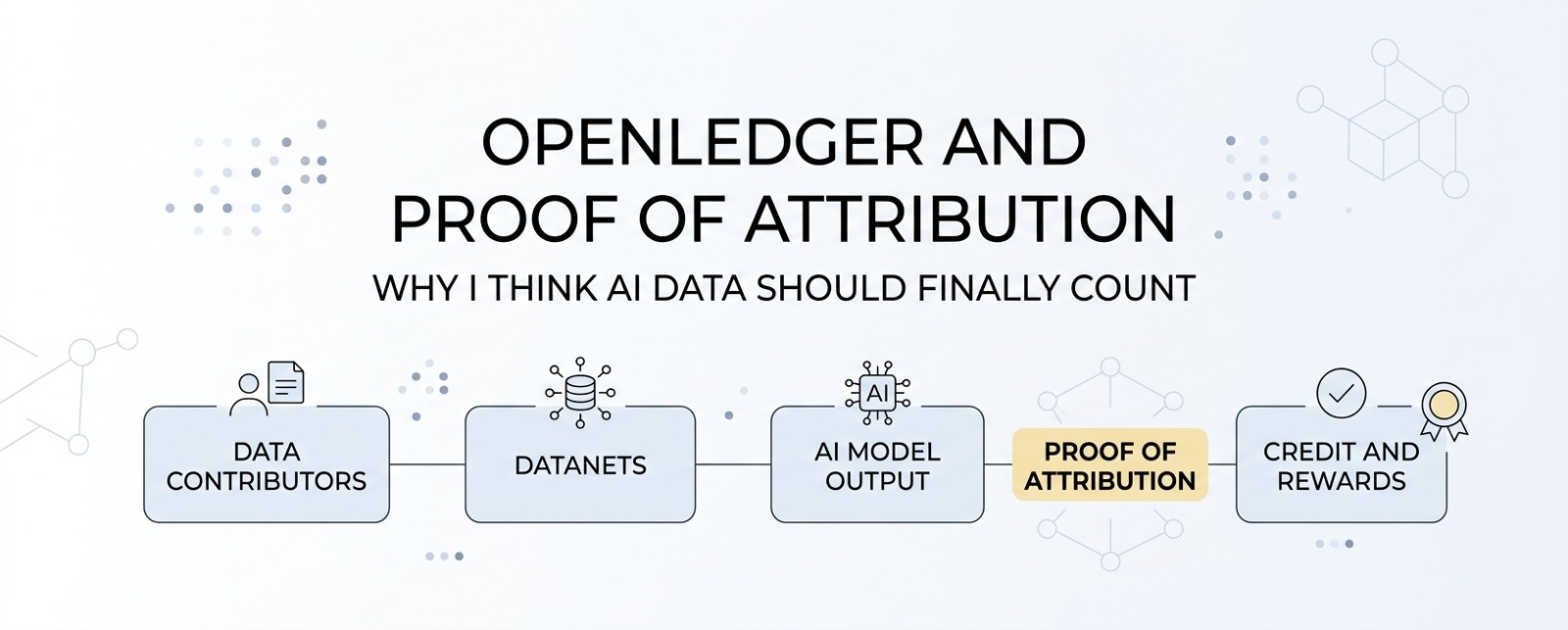
Openledger essaie de combler cette lacune avec un système IA-blockchain construit autour de jeux de données communautaires appelés datanets. Je vois les datanets comme des pools de données ciblées où les gens peuvent contribuer des informations utiles pour des modèles d'IA spécialisés. Cela importe parce que des données générales ne suffisent pas toujours. Certains cas d'utilisation de l'IA ont besoin de données plus propres, plus profondes et plus spécifiques.
C'est là que la preuve d'attribution devient importante.
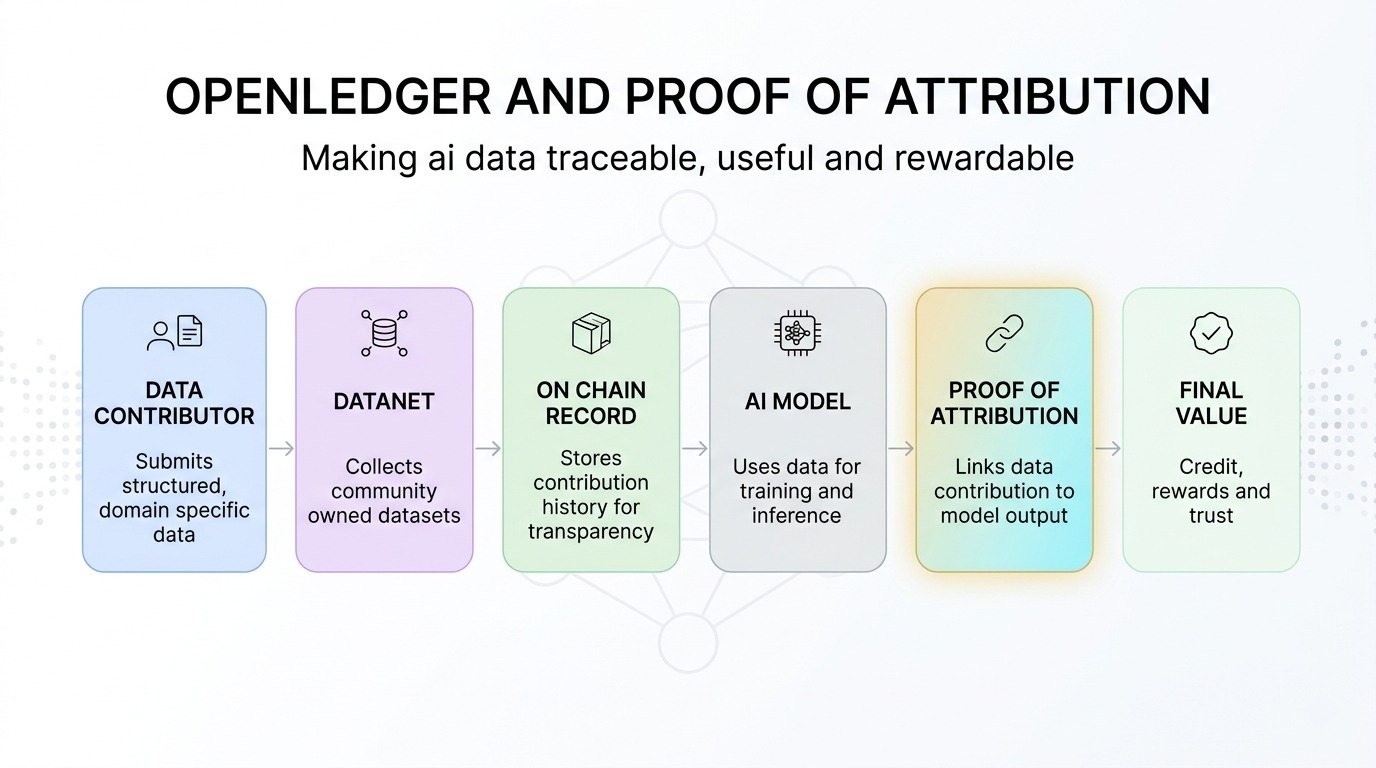
Pour moi, la preuve d'attribution ressemble à un système de reçu pour les données d'IA. Il est conçu pour connecter les contributions de données aux résultats des modèles d'IA. En d'autres termes simples, si une personne ajoute des données utiles et que ces données aident le modèle à mieux performer, le système vise à rendre cette contribution traçable.
J'aime cette idée parce qu'elle change notre façon de penser à la valeur de l'IA.
Aujourd'hui, beaucoup de gens parlent de modèles, de tokens et d'applications. Mais moins de gens parlent de la couche de données qui les sous-tend. Je pense que l'approche de #OpenLedger est intéressante parce qu'elle rapproche le contributeur de la chaîne de valeur. Elle ne traite pas les données comme une ressource cachée. Elle traite les données comme quelque chose qui peut être vérifié, suivi et récompensé.
Cela pourrait aussi améliorer la qualité des données. Si les contributeurs savent que leur travail peut être reconnu, ils ont plus de raisons de fournir des données utiles au lieu d'informations aléatoires.
Néanmoins, je ne dirais pas que c'est un problème facile. Suivre l'influence des données réelles dans l'IA est compliqué. L'idée semble solide, mais le vrai test est de savoir si Openledger peut rendre l'attribution précise à grande échelle.
Pour moi, le point clé est simple. L'avenir de l'IA ne devrait pas seulement récompenser le propriétaire du modèle. Il devrait aussi reconnaître les personnes derrière les données.