J'ai traîné assez longtemps dans le monde de l'intelligence artificielle et des discussions crypto pour savoir quand une présentation est juste un costume bien taillé sur une idée faible. La plupart des modèles de récompense dans cet espace semblent encore paresseux. Rejoins, clique, poste, stake, farm, répète. Ça compte le mouvement. Ça ne demande pas si ton travail a amélioré quoi que ce soit. C'est une mauvaise façon de valoriser l'apport humain, et c'est encore pire quand des données d'IA sont impliquées.
@OpenLedger avec $OPEN vaut vraiment le coup d'être lu attentivement car il essaie de s'attaquer à ce vieux bazar, qui devrait gagner quand de nombreuses mains façonnent un seul modèle ?
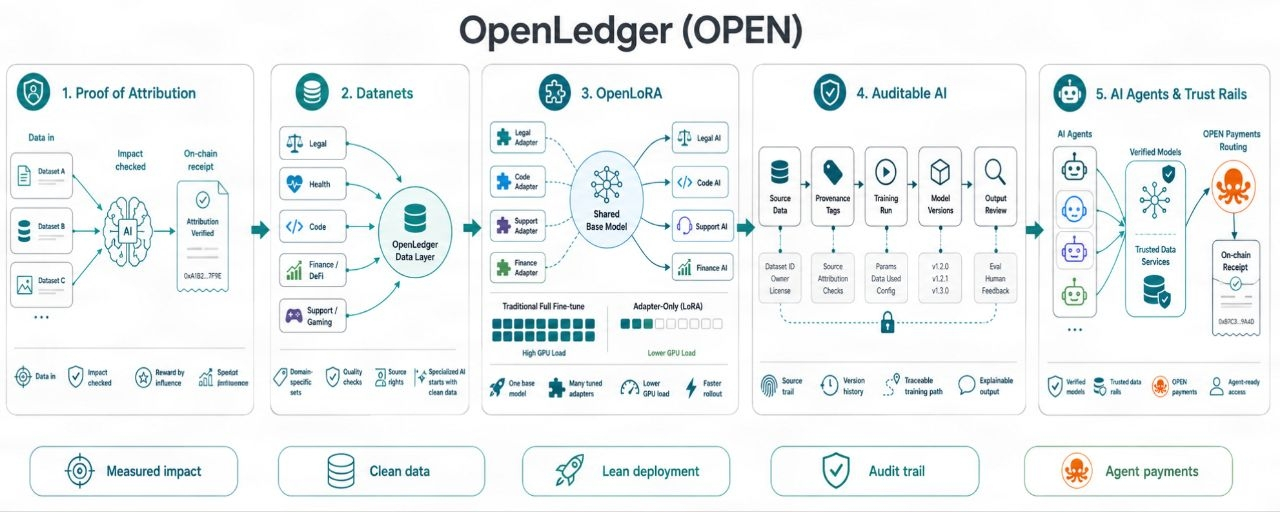
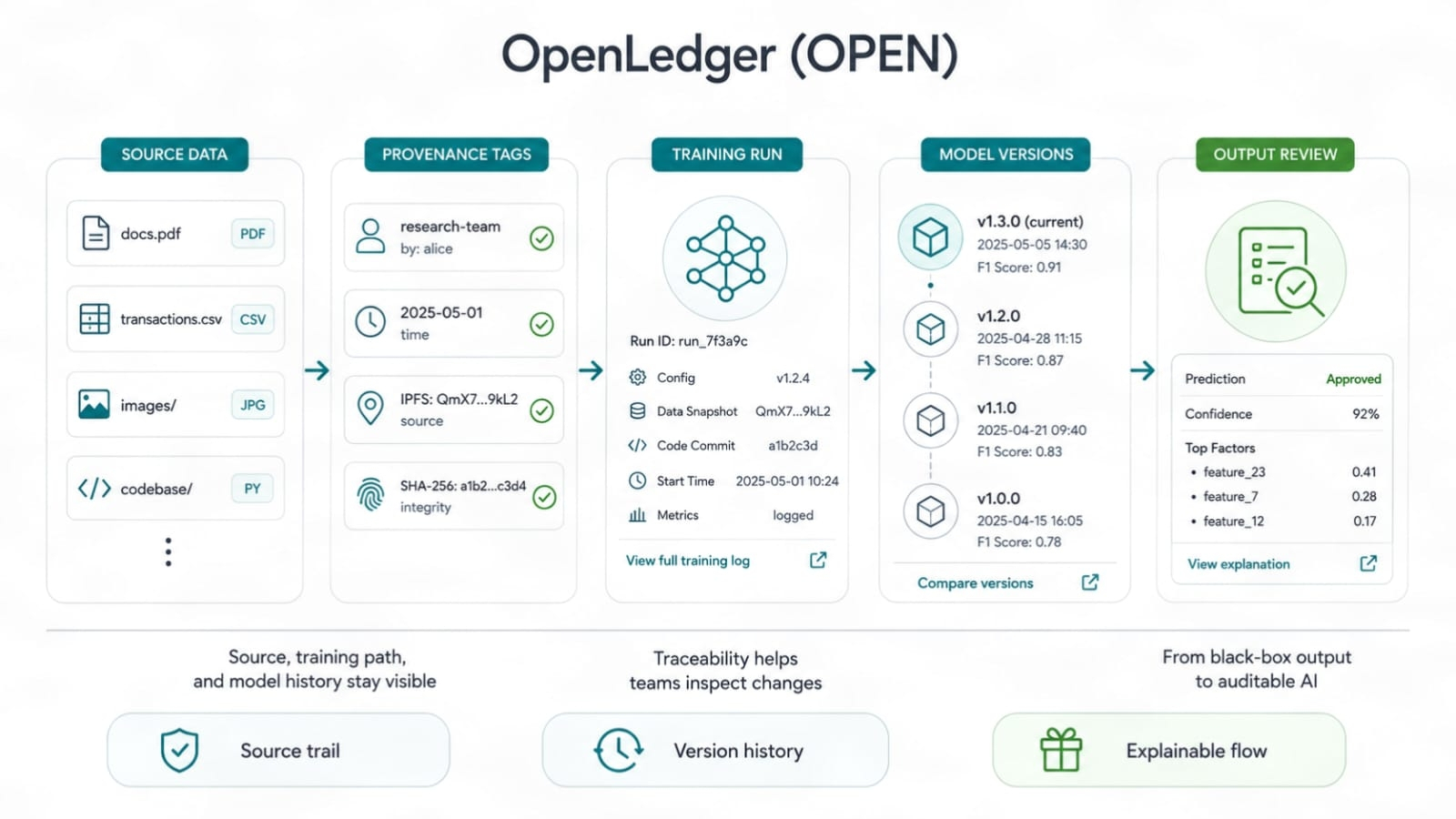
La preuve d'attribution est utile car elle déplace le focus de « J'ai participé » à « mes données ont changé la qualité des résultats. »
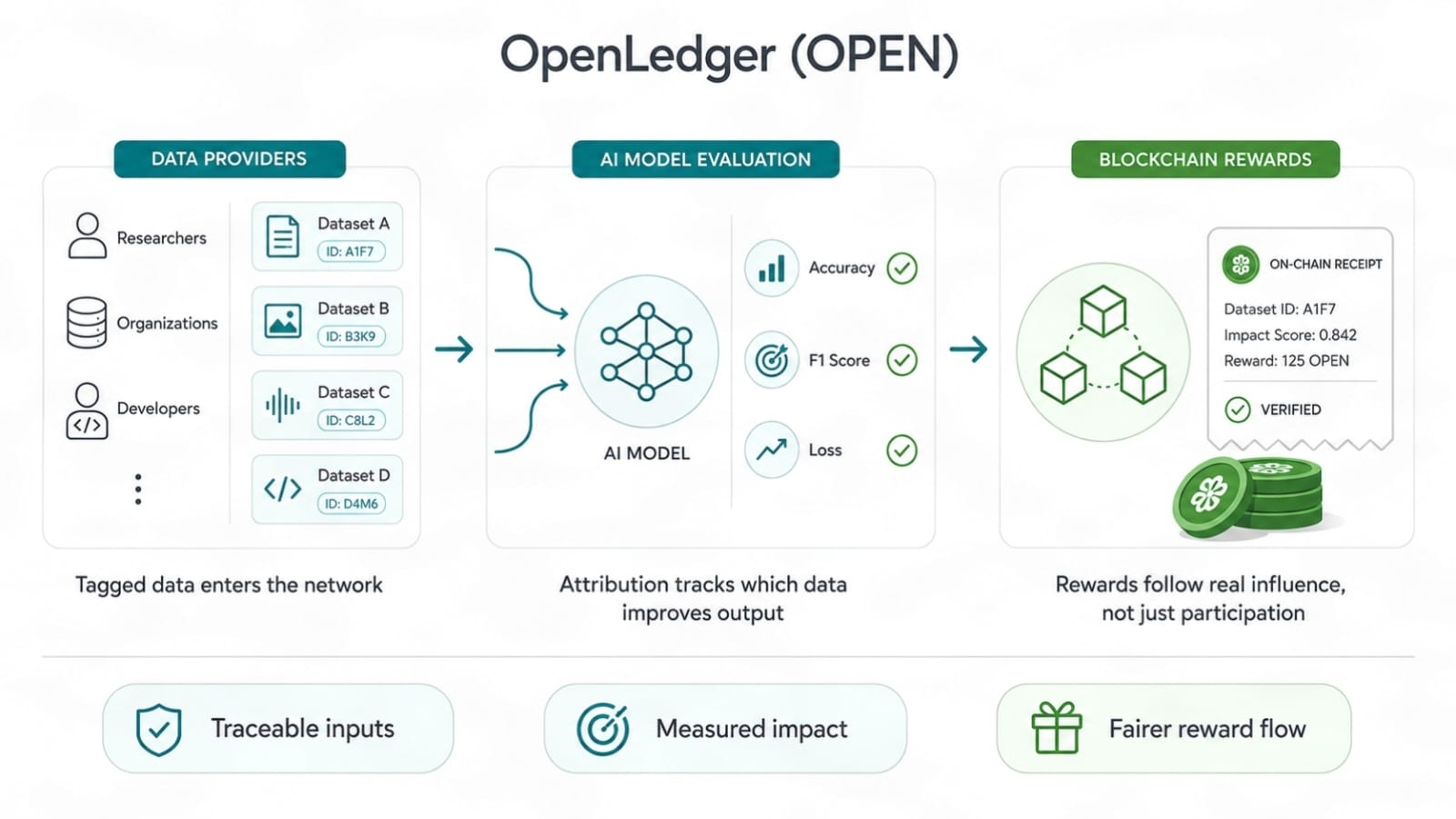
Cela semble petit. Ce ne l'est pas. Les marchés de données IA ont beaucoup de poids inutile. Les gens peuvent déverser des fichiers, gratter des textes de faible qualité, les renommer et espérer que l'échelle cache la faible valeur source. Si les récompenses suivent les entrées brutes, le spam gagne. Si les récompenses suivent un véritable levier, la qualité a un couloir.
C'est difficile à faire. Je ne vais pas l'embellir. L'attribution en IA n'est pas un jouet mathématique propre. Les modèles apprennent de manière désordonnée. Un ensemble de données peut aider une tâche et nuire à une autre. Certaines entrées ajoutent des compétences de cas limites. D'autres ne font que répéter ce que le modèle sait déjà. Donc, la revendication d'OpenLedger doit vivre ou mourir selon la façon dont elle peut suivre l'impact des données, les droits, l'utilisation des modèles et le flux de récompenses. De belles docs ne suffiront pas. La preuve en direct comptera.
Les données ont besoin d'une trace de reçu. Pas un faux badge. Pas un score de vanité. Une trace qui montre d'où provient une entrée de données, comment elle a été utilisée et quel rôle elle a joué. C'est ce que veulent les fournisseurs de données s'ils sont sérieux. Ils ne veulent pas se tenir dans une foule et espérer des miettes. Ils veulent savoir si leurs données ont du poids.
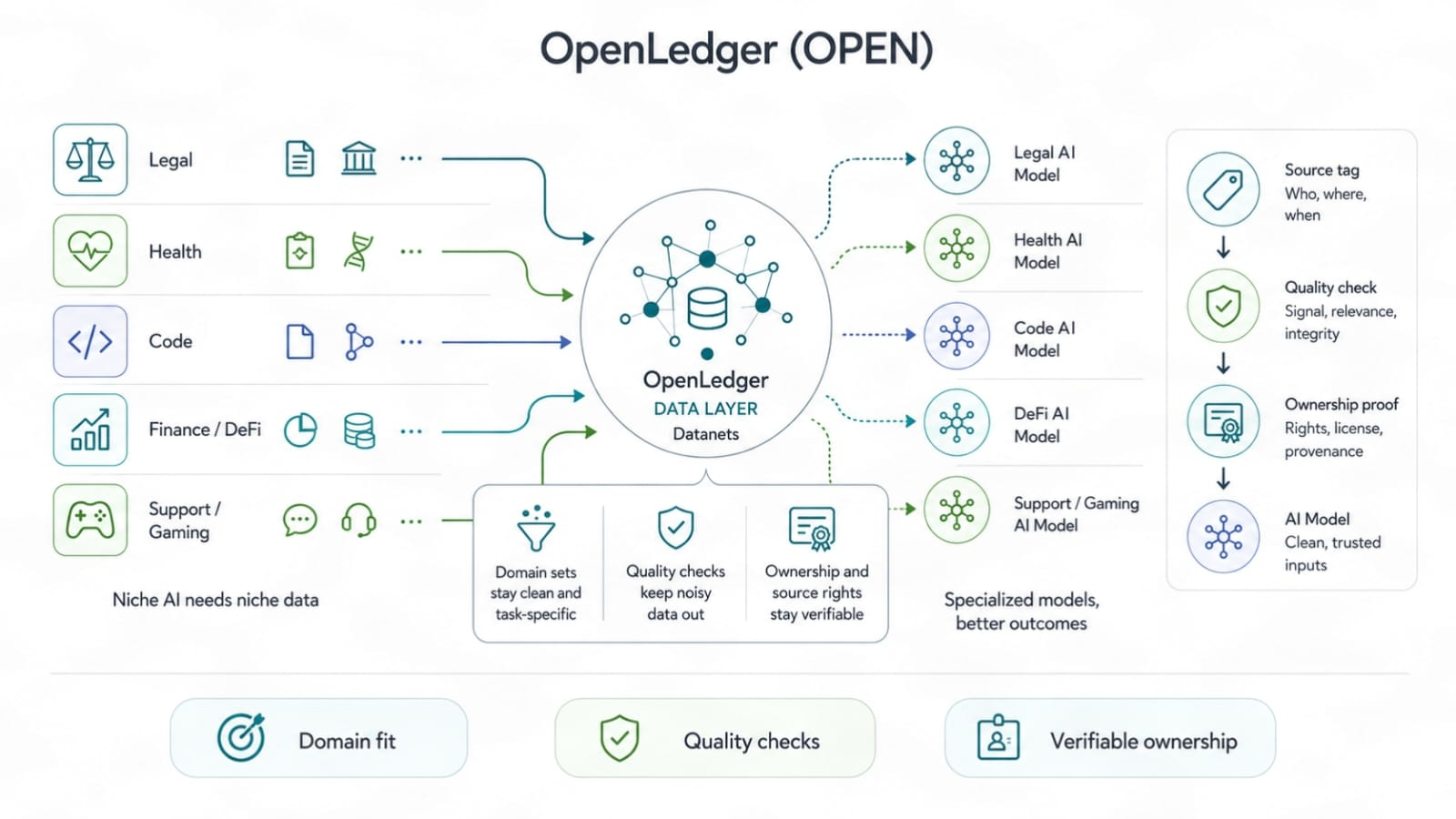
Les Datanets sont là où cela commence à devenir plus réel. Les données AI larges ont des limites. Vous pouvez entraîner un modèle général sur d'énormes tas de texte, c'est sûr. Mais quand vous avez besoin d'un modèle pour le droit, le code, l'administration de la santé, les actifs de jeu, le risque DeFi, les statistiques sportives ou les opérations de support, les données larges commencent à sembler légères. Les données de tâche gagnent. Les données propres gagnent. Les données possédées gagnent.
Datanet peut agir comme une salle de travail pour un domaine. Il peut contenir des données sources, des liens de droits, des enregistrements d'utilisation et des ajustements de tâches. C'est plus utile qu'un énorme seau où toutes les données sont mélangées jusqu'à ce que personne ne sache d'où ça vient. Si OpenLedger peut aider chaque domaine à garder sa propre trace de données, alors les constructeurs de niche obtiennent une meilleure base pour s'entraîner. Pas parfait. Mieux.
Cela donne également aux petits propriétaires de données une chance équitable. L'équipe peut ne pas avoir une grande échelle, mais elle peut avoir des données rares avec une grande valeur d'utilisation. Dans les anciens marchés, la taille a tendance à écraser l'habileté. Dans les marchés basés sur l'attribution, un petit ensemble qui augmente le résultat du modèle pourrait compter plus qu'un énorme tas qui ajoute du bruit. C'est un cadre plus sain. Cela récompense le véritable avantage, pas le volume bruyant.
OpenLoRA s'inscrit alors dans un second point de douleur, le coût de déploiement des modèles. Les modèles finement réglés semblent géniaux jusqu'à ce que le coût du GPU frappe. Le travail complet du modèle peut dévorer le budget rapidement. Les méthodes de style LoRA aident car elles adaptent un modèle de base avec des changements de poids plus légers. Vous n'avez pas besoin de traîner un nouveau modèle complet à chaque fois. Vous pouvez exécuter plusieurs chemins réglés avec moins de charge.
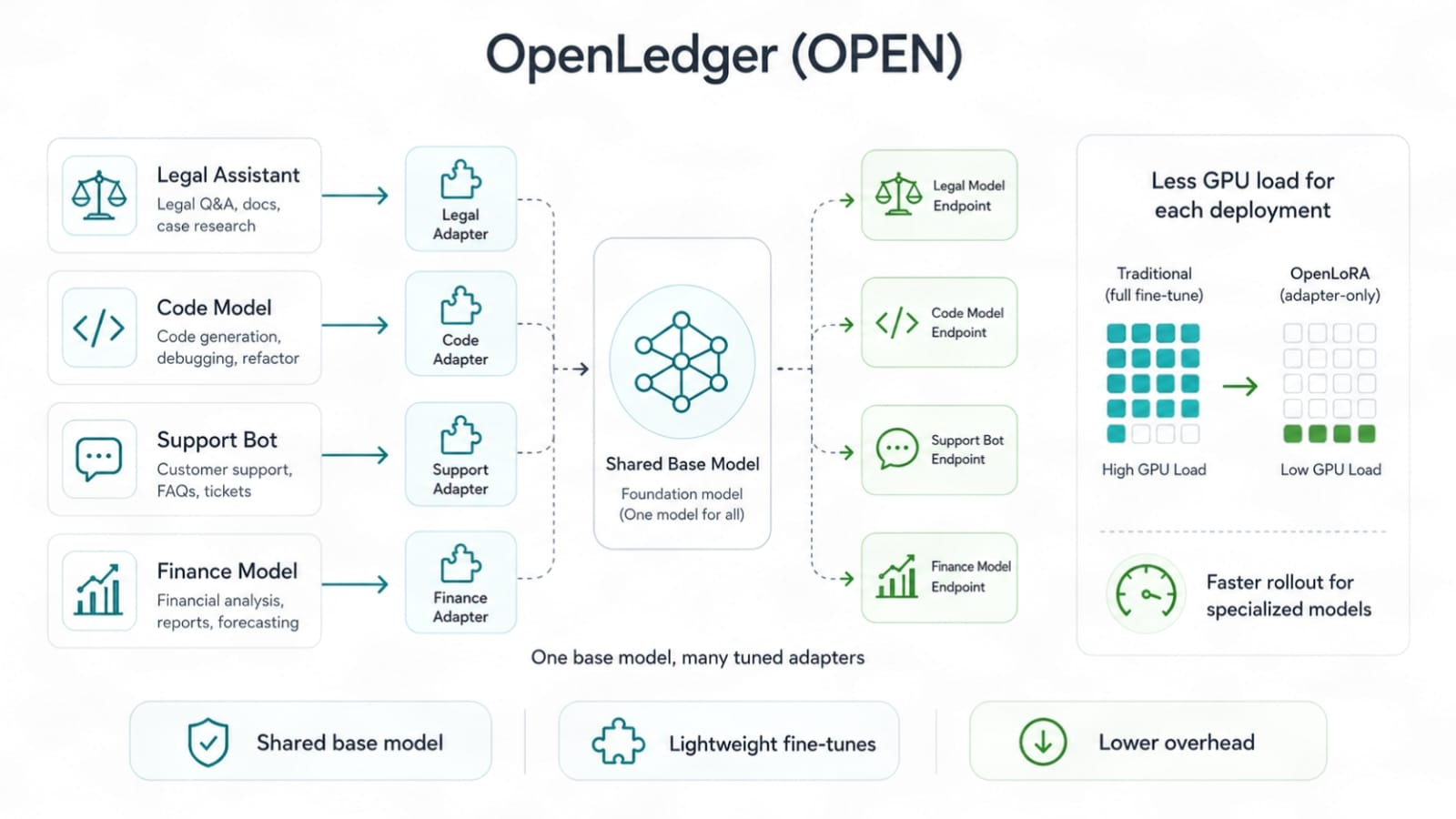
OpenLedger, OpenLoRA pourrait signifier plus de modèles de tâches servis avec moins de traînée de calcul. Cela compte parce que l'avenir de l'IA ne sera pas un énorme modèle faisant tous les jobs correctement. Il s'agira probablement de nombreux modèles ciblés, chacun réglé pour une voie. Un pour la recherche juridique. Un pour les opérations financières. Un pour le support de jeu. Un pour les vérifications de données de chaîne. Un pour l'utilisation des outils d'agents. Petit, précis, assez bon marché pour fonctionner. Ce n'est pas du battage. C'est là où beaucoup de travail IA pointe déjà.
Mais les réductions de coûts ne peuvent pas se faire au détriment de la confiance. Un modèle bon marché que personne ne peut tracer est juste un problème rapide. Les équipes ont besoin d'un historique modèle. Quelles données ont été utilisées ? Quelle version a changé ? Qui a ajouté quoi ? Un nouvel ensemble de données a-t-il rendu les réponses pires ? Un constructeur peut-il revenir en arrière ? Un propriétaire de données peut-il prouver l'utilisation ? Ce ne sont pas des éléments à avoir ou à ne pas avoir. Ce sont les moyens par lesquels de vraies équipes gardent le contrôle lorsque l'IA s'intègre dans les opérations quotidiennes.
L'IA en boîte noire a toujours une odeur faible autour d'elle. Pas parce que l'IA est mauvaise, mais parce que la confiance se brise quand personne ne peut auditer un chemin. La trace d'audit d'OpenLedger vise à rendre l'historique de construction du modèle plus facile à inspecter. La traçabilité et la preuve de source peuvent sembler sèches jusqu'à ce que quelque chose se casse. Alors, elles deviennent des outils essentiels. Quiconque a expédié de réels systèmes le sait. Les logs battent les vibrations.
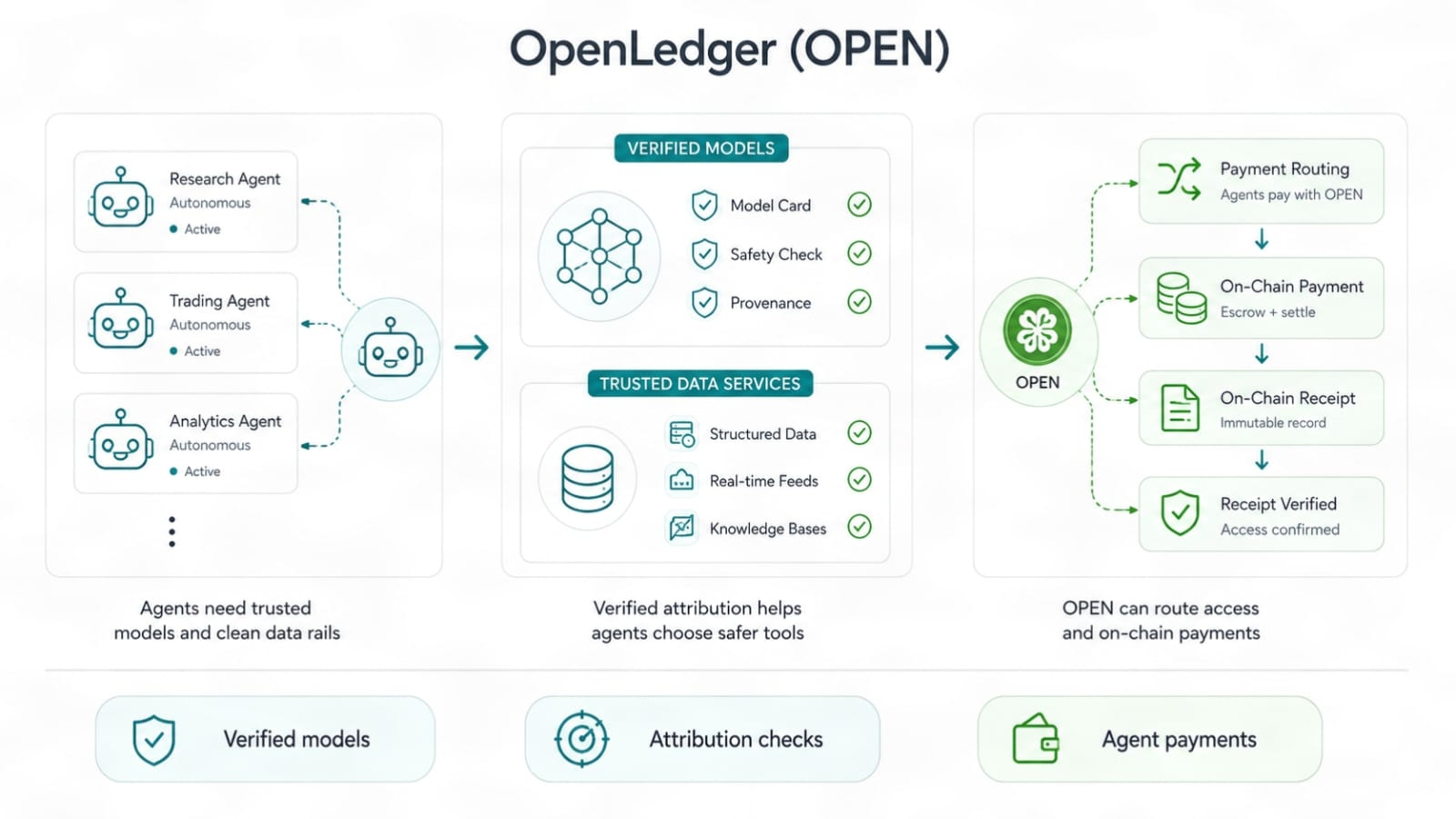
Les agents IA augmentent encore les enjeux. Les agents ne se contentent pas de répondre. Ils agissent. Ils appellent des modèles, utilisent des données, routent des tâches et peuvent payer pour l'accès à travers les systèmes. Une fois que les agents commencent à faire plus de choix par eux-mêmes, les rails de confiance comptent. Un modèle avec un historique de données vérifié est plus sûr à brancher dans le flux des agents qu'un avec des racines inconnues. Une couche de paiement liée à OPEN pourrait aider à router les frais et les récompenses à l'intérieur de ce système, mais seulement si l'utilisation est réelle et que les règles restent claires.
OpenLedger pointe vers un besoin de marché réel, une récompense équitable pour des données IA utiles. La preuve d'attribution n'est pas une question de distribution de jetons à quiconque se présente. Il s'agit de lier la récompense à l'impact. Les Datanets donnent aux données de domaine un endroit pour prouver leur valeur. OpenLoRA donne aux modèles réglés un chemin de déploiement léger. Les outils d'audit ramènent l'historique source en vue. Les paiements d'agents laissent entrevoir un futur travail IA où les modèles, les données et les tâches évoluent avec moins de traînée humaine.
DYOR, toujours. Lisez les docs. Suivez l'utilisation. Observez comment fonctionnent les récompenses en vue ouverte. Vérifiez si la qualité des données reste élevée lorsque les incitations augmentent. Vérifiez si OPEN a un besoin clair dans le flux de travail, pas seulement un logo en haut. Un design propre n'est pas la même chose qu'un ajustement de marché solide.
Je ne suis pas ici pour couronner quoi que ce soit. La crypto a brûlé trop de gens intelligents qui sont tombés amoureux de mots élégants. Mais je pense qu'OpenLedger pose une des bonnes questions. Dans l'intelligence artificielle, la valeur ne viendra pas simplement de la possession de données. Elle viendra de la preuve des données qui ont aidé, qui les a possédées, où elles sont allées et pourquoi elles méritent une part. C'est là que cette histoire a du mordant.
\u003ct-24/\u003e\u003ct-25/\u003e\u003ct-26/\u003e\u003ct-27/\u003e
