
Flash Info: Données sur le financement en profondeur, mots-clés AI
2026-06-15
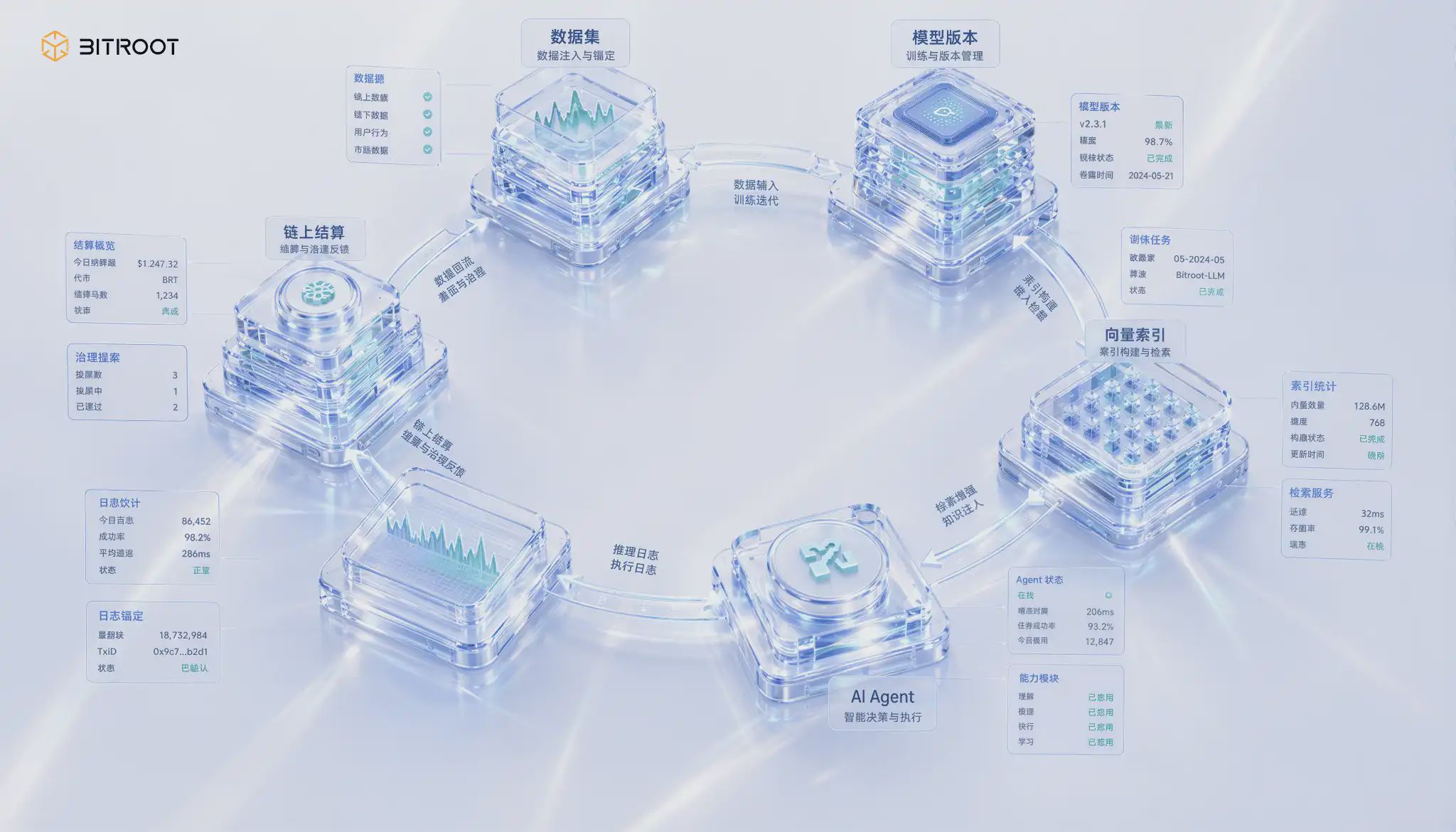
Bitroot, d'une part, fournit un environnement d'exécution en chaîne haute performance grâce à la parallélisation de l'EVM et au Pipeline BFT, et d'autre part, connecte les données, les modèles, la puissance de calcul et les applications d'agent en un réseau liquidable via un entraînement distribué, un réseau d'inférence, une exécution fiable et une gestion des actifs AI. Dans ce réseau, le stockage n'est pas un module isolé, mais l'infrastructure qui détermine si les données peuvent être certifiées, si les modèles peuvent être reproduits, si la puissance de calcul peut être liquidée et si les contributeurs peuvent continuer à générer des revenus.
Source : Bitroot
Le stockage n'est pas un centre de coût, c'est le système de distribution de valeur de la Bitroot AI Stack
Ce n'est que plus de six mois après le déploiement que de nombreuses équipes réalisent qu'elles auraient dû choisir leur couche de stockage avec plus de soin dès le départ. Les données n'ont pas été perdues et le service n'a pas été interrompu, mais les problèmes sont apparus différemment : la récupération des données d'entraînement archivées est devenue de plus en plus lente et la latence des requêtes vectorielles fréquemment utilisées est passée de millisecondes à plusieurs secondes. Lors de l'analyse d'un incident en ligne, personne n'a pu déterminer la version des données d'entraînement utilisée par le modèle. À ce stade, le problème n'était plus lié à la montée en charge, mais soulevait trois questions plus complexes : qui peut prouver que les données ont toujours été disponibles ? Qui est responsable de la version ? Et qui prendra en charge les coûts à long terme ?
Considérer le stockage comme un simple déplacement de fichiers d'un cloud centralisé vers un réseau externe peut se justifier à l'ère des métadonnées NFT. Cependant, cette approche deviendra rapidement obsolète dès que les besoins s'étendront aux corpus d'entraînement de l'IA, aux pondérations de modèles et aux index vectoriels.
La plupart des équipes considèrent encore le stockage comme un coût logistique à minimiser, ce qui est précisément là où il est le plus sous-estimé et le plus sujet aux erreurs d'appréciation : dans les blockchains publiques d'IA, c'est en réalité la couche de distribution de la valeur qui détermine qui contrôle les données et qui perçoit les revenus. Cet article répond à une question unique : comment construire, dans le contexte de l'intégration de l'IA et des blockchains publiques, une solution de stockage distribuée vérifiable, gouvernable et durable ? Nous analyserons d'abord les limites de trois paradigmes majeurs, puis expliquerons les défis spécifiques aux données d'IA, et enfin proposerons une architecture d'implémentation à cinq couches et des seuils de déploiement progressif. Notre analyse s'appuie autant que possible sur les documents de protocole officiels et des sources vérifiables.
Prenons Bitroot comme exemple : la couche de stockage se positionne plus précisément comme le socle de la distribution de valeur de la pile d'IA. D'une part, Bitroot fournit un environnement d'exécution on-chain haute performance grâce à l'EVM parallélisé et au BFT en pipeline. D'autre part, il connecte les données, les modèles, la puissance de calcul et les applications d'agents au sein d'un réseau de règlement via l'entraînement distribué, les réseaux d'inférence, l'exécution de confiance et la gestion des actifs d'IA. Dans ce réseau, le stockage n'est pas un module isolé, mais une infrastructure qui détermine la propriété des données, la reproductibilité des modèles, la rémunération de la puissance de calcul et la continuité des bénéfices pour les contributeurs.
La blockchain intégrale et la centralisation totale ne sont plus des solutions viables dans les scénarios d'IA.
Ces dernières années, le problème du stockage a souvent été réduit à deux options : tout sur la blockchain ou tout centralisé. Aucune de ces solutions n’est viable dans le contexte de l’IA.
La pression liée à l'intégration intégrale des données sur la blockchain est très concrète. Les données d'entraînement, les poids des modèles, les journaux d'inférence et les index vectoriels sont généralement volumineux et fréquemment mis à jour. Même s'ils sont d'abord segmentés puis intégrés à la blockchain, le débit maximal et les coûts de traitement deviendront rapidement prohibitifs. Les systèmes entièrement centralisés sont rapides, mais la vérifiabilité, la traçabilité, la souveraineté des données et la confiance, fondements essentiels de la collaboration inter-entités, sont extrêmement fragiles. Elles ne résisteront pas à l'épreuve du partage des revenus et de la confirmation des droits entre plusieurs parties.
Un changement plus crucial réside dans le fait que l'IA a transformé le stockage, d'un poste de dépense en un facteur de production. La gestion des versions de données détermine qui prend l'initiative en matière d'itération des modèles ; la capacité à prouver l'utilisabilité des données influe directement sur la priorité de la planification et du règlement de la puissance de calcul ; et la capacité à valoriser les données est essentielle à la mise en place d'incitations à long terme au sein de l'écosystème. À ce stade, la couche de stockage n'est plus un système logistique, mais un système de distribution de valeur.
Par conséquent, une architecture de stockage qualifiée doit répondre simultanément à quatre questions : les données existent-elles réellement et sont-elles accessibles en permanence ? La relation de version entre les données et les modèles est-elle traçable ? Les autorisations et les avantages sont-ils gouvernables ? Et le système peut-il atteindre un équilibre à long terme entre coût et performance ?

L'approche de Bitroot : faire passer les données d'IA de l'état « stockable » à l'état « défini »
C’est précisément là que Bitroot doit combler cette lacune. En tant que blockchain publique EVM parallèle haute performance dédiée à l’IA, la stratégie de stockage de Bitroot ne doit pas se limiter à la simple localisation des données, mais doit également répondre aux questions suivantes : comment les données sont-elles authentifiées, comment y accède-t-on et comment participent-elles au partage des revenus ? Les corpus d’entraînement, les pondérations des modèles, les index vectoriels et les journaux d’inférence peuvent résider dans une couche de stockage distribuée plus adaptée aux objets volumineux, mais leurs engagements de hachage, leurs relations de version, leurs politiques d’autorisation, leurs enregistrements d’accès et les événements liés aux revenus doivent constituer une preuve unifiée sur la blockchain Bitroot.
De ce point de vue, le débit élevé et la faible latence de Bitroot ne servent pas uniquement les transactions DeFi, mais aussi des événements de gouvernance plus précis et fréquents au sein de la pile d'IA : ancrage des mises à jour des ensembles de données, enregistrement des versions des modèles, résolution des appels des agents d'IA, arbitrage des litiges relatifs aux résultats de recherche et contrôle continu de la disponibilité des nœuds de stockage. Ce n'est que lorsque la blockchain sous-jacente est capable de gérer ces événements que les données d'IA peuvent éviter d'être bloquées dans des bases de données centralisées ou de devenir une boîte noire hors chaîne intraçable.

Aucun des trois paradigmes dominants ne peut à lui seul résoudre tous les scénarios.
La concurrence dans le domaine du stockage distribué ne se résume jamais à savoir qui possède la technologie la plus avancée, mais à savoir qui est le plus adapté à votre structure de données.
Le réseau à adressage par contenu (CDN) répond à la question de l'identité des données, et non à celle de la garantie de leur disponibilité en ligne. Selon la documentation officielle d'IPFS, un identifiant de contenu (CID) est un identifiant basé sur le hachage du contenu, indépendant de l'adressage géographique : un même contenu génère le même CID avec les mêmes paramètres d'encodage/décodage, et le CID change à chaque modification d'octet du contenu. Cette caractéristique le rend naturellement adapté à la vérification d'intégrité, à la déduplication et au référencement inter-systèmes, servant de base à la confirmation de la propriété des données. Cependant, l'adressage par contenu n'est pas synonyme de disponibilité économiquement viable. Un CID répond à la question de l'identité, mais pas à celle de la garantie de disponibilité continue en ligne. De nombreuses équipes rencontrent ce premier écueil après le déploiement : elles obtiennent techniquement le CID, mais l'entreprise ne bénéficie d'aucune garantie de disponibilité.
Le réseau de stockage utilise un mécanisme économique pour garantir la disponibilité des données dans le temps. Selon la documentation Filecoin, le réseau établit un mécanisme d'engagement de stockage, complété par une preuve continue via la preuve de réplication (PoRep) et la preuve spatio-temporelle (PoSt). La PoRep atteste qu'une copie unique est bien stockée lors du scellement initial, et la PoSt confirme son existence de manière répétée lors des cycles suivants. Le cycle de preuve de WindowPoSt est généralement organisé en intervalles de 24 heures, eux-mêmes divisés en plusieurs fenêtres de preuve de 30 minutes. Si le fournisseur de stockage ne fournit pas de preuve valide dans le délai imparti, la garantie est confisquée et la capacité de stockage est réduite. Dans ce système, la disponibilité est évaluée en continu, et non un engagement ponctuel après la signature du contrat. Ce modèle contractuel et auditable convient à l'archivage, à la sauvegarde et aux marchés de données à moyen et long terme, mais il s'apparente davantage à un entrepôt de stockage à long terme avec preuve qu'à un service en ligne à faible latence. L'envoi direct de requêtes en ligne à haute fréquence dégraderait l'expérience utilisateur en raison de la latence résiduelle.
Les réseaux de stockage persistant adoptent une approche différente, proposant un paiement unique en échange d'un historique immuable. Selon le protocole Arweave et son livre blanc, une partie des frais de chargement alimente un fonds de stockage afin de financer les incitations au stockage à long terme, garantissant ainsi la pérennité du service dès la facturation, plutôt que de dépendre des renouvellements ultérieurs. Ce système convient aux données immuables telles que les archives historiques, les identifiants critiques et les documents protégés par le droit d'auteur. Ses inconvénients sont tout aussi évidents : la persistance n'implique pas automatiquement une forte concurrence et une faible latence. En pratique, la mise en cache, les passerelles ou les couches d'indexation quasi-en-ligne restent indispensables pour répondre aux exigences d'expérience utilisateur en temps réel.
Outre ces trois paradigmes de base, deux autres combinaisons d'ingénierie courantes méritent d'être prises en compte. La première est une approche hybride associant une couche de disponibilité des données à un stockage objet. Elle offre une publication des données plus standardisée et une meilleure preuve de disponibilité, mais au prix d'une collaboration intercouches complexe et de coûts de gouvernance des interfaces élevés. La seconde est une approche multicloud avec collaboration en périphérie. Elle offre une meilleure faible latence et une reprise après sinistre améliorée, mais rend la gestion des coûts et de la cohérence plus difficile.
Quel que soit le choix, il est irréaliste qu'un seul protocole puisse gérer tous les scénarios d'ingénierie. Une approche efficace consiste à combiner les protocoles en fonction des types de données : persistance, latence de récupération et conformité (à séparer), les associer séparément à la couche de capacités, puis les orchestrer de manière uniforme grâce à l'ancrage sur la blockchain et à la couche de gouvernance.

Les options de Bitroot devraient également reposer sur cette logique combinatoire : au lieu de remplacer IPFS, Filecoin, Arweave ou le stockage d'objets les uns par les autres, elles sont réparties en différents niveaux de responsabilité. L'adressage par contenu garantit l'identité et l'intégrité des données, les preuves de stockage assurent la disponibilité à long terme, la couche de persistance conserve l'historique et les identifiants critiques, la couche de récupération rapide optimise l'expérience des applications d'IA, et la couche on-chain de Bitroot gère de manière uniforme l'ancrage des versions, les politiques d'autorisation, le règlement des appels et la résolution des litiges. En d'autres termes, Bitroot n'a pas besoin d'être le dépôt physique de toutes les données, mais plutôt un registre de confiance pour le flux de valeur des données d'IA.
Le défi du stockage piloté par l'IA ne réside pas dans le stockage des fichiers, mais dans la gestion de l'ensemble de la chaîne de production.
Dans les scénarios d'IA, les objets stockés peuvent être classés en au moins quatre catégories : données d'entraînement, poids des modèles, index vectoriels et journaux d'inférence. Ces quatre types d'objets présentent des cycles de vie, des modes d'accès et des densités de valeurs totalement différents. Les gérer selon une stratégie unique peut sembler pratique à court terme, mais entraînera inévitablement une perte de contrôle à long terme.
Le problème des données d'entraînement ne réside pas dans leur taille, mais dans la dérive des versions. De nombreuses équipes associent les problèmes liés aux données d'entraînement à des coûts de stockage de l'ordre du téraoctet, mais le véritable défi est la dérive des versions : toute modification des règles de nettoyage, des seuils de sélection des échantillons ou des méthodes d'annotation altère le comportement du modèle. Sans liaison entre les versions des données et du modèle, l'évaluation hors ligne devient difficile à vérifier. Conformément aux pratiques de suivi des modèles et des données de MLflow, lier les exécutions d'entraînement aux versions des données est une condition préalable à la reproduction des expériences. Ce principe s'applique également à la blockchain : toutes les données brutes n'ont pas besoin d'y être stockées, mais les engagements de version, les résumés clés et les empreintes numériques des sources doivent y être ancrés. Concrètement, au moins trois identifiants doivent être liés : la version des données, l'exécution d'entraînement et la version du modèle. L'absence de l'un d'entre eux compliquera la résolution des problèmes en ligne, passant de la recherche de preuves à la conjecture de la cause.
Le problème de la pondération des modèles ne réside souvent pas dans leur téléchargement, mais plutôt dans la gestion des limites des appels. Un modèle entrant en production passe généralement par plusieurs étapes : déploiement progressif, utilisation principale, restauration et mise hors service. Sans système d'enregistrement et d'autorisation standardisé, les appels en ligne deviennent une boîte noire impossible à auditer. Un registre de modèles mature enregistre simultanément la lignée, les alias de version, les contraintes de signature et les étiquettes d'audit. Pour les systèmes on-chain, les versions de modèles ne doivent pas se limiter à un simple hachage de fichier ; elles doivent également être liées à des politiques d'autorisation, à la répartition des revenus et aux responsabilités.
Le défi de l'indexation vectorielle réside dans le maintien de la cohérence après la superposition des couches chaude et froide. La recherche vectorielle présente une contradiction inhérente : faible latence et faible coût sont incompatibles. La couche chaude s'appuie sur la mémoire ou des services d'indexation haute performance pour garantir une réponse en ligne, tandis que la couche froide utilise le stockage objet pour limiter les coûts à long terme. Sans métadonnées unifiées ni stratégie de synchronisation, les deux couches divergent rapidement, ce qui peut conduire à ce qu'une même requête renvoie des résultats sémantiques différents selon les nœuds. Par conséquent, les systèmes vectoriels doivent prendre en charge deux éléments : un processus de construction d'index traçable et des versions d'index de la couche chaude vérifiables par rapport aux données maîtres de la couche froide. C'est précisément ce que le système de recherche vérifiable abordera ultérieurement.
Il est difficile de garantir simultanément la confidentialité, l'audit et la conformité des journaux d'inférence. Ces journaux servent à la fois de support pour les audits de sécurité et de source de risques pour la confidentialité : conserver toutes les données en clair pose des problèmes de conformité, tandis qu'éliminer tout risque de perte de données empêche toute remédiation en cas d'incident. Une approche viable consiste en une structure à trois niveaux : le contenu est stocké après anonymisation, les engagements hachés sont chargés sur la blockchain et l'accès nécessite une autorisation d'audit, assurant ainsi l'immuabilité et la révocabilité des accès par couches successives.
Au sein de la pile d'IA de Bitroot, ces quatre types d'objets correspondent à quatre actions de gouvernance : les données d'entraînement font l'objet d'un ancrage de version et d'un enregistrement de source ; les pondérations des modèles servent à l'enregistrement des actifs et à leur invocation autorisée ; les index vectoriels sont utilisés pour la stratification chaud/froid et la preuve de cohérence ; et les journaux d'inférence sont stockés de manière anonyme et audités. Leur présence sur la blockchain n'est pas nécessairement identique, mais ils doivent tous former un identifiant d'actif, une hiérarchie de versions et un événement d'invocation unifiés sur Bitroot. Ceci permet la création d'une boucle métier réutilisable entre les actifs de données, les actifs de modèles et les applications agentes.

La vérifiabilité est l'essentiel ; la preuve d'utilisabilité est le facteur décisif.
En production, les engagements de stockage sans preuve de disponibilité sont pratiquement inutiles. Pour qu'un stockage distribué soit mis en production, il doit franchir au moins trois obstacles : la vérification de son intégrité, de sa disponibilité et l'auditabilité de son comportement. Dès lors qu'il est intégré à un scénario de récupération par IA, un obstacle supplémentaire, bien plus complexe, s'ajoute : la vérification de la récupération.
La vérification d'intégrité repose sur l'adressage de contenu et les engagements Merkle. L'adressage de contenu assure la stabilité de l'empreinte numérique des données, tandis que les engagements Merkle garantissent la vérifiabilité locale. Concrètement, cela permet d'utiliser des preuves au niveau des fragments pour vérifier un sous-ensemble de l'objet, au lieu de lire l'intégralité des données à chaque fois. Pour les modèles comportant des poids importants, les grands corpus et les données multimédias, cela influe directement sur le coût de la vérification.
La vérification de la disponibilité repose sur des mécanismes de défi et une validation par échantillonnage. L'expérience de Filecoin a démontré que la disponibilité ne se limite pas à un simple accord de niveau de service (SLA), mais résulte d'une combinaison de défis périodiques et de preuves enregistrées sur la blockchain. Dans une architecture générale, cela se traduit par une approche en trois volets : des contrôles ponctuels passifs, des inspections proactives et des pénalités en cas de défaillance. Les nœuds doivent répondre aux défis dans un délai imparti ; à défaut, des pénalités ou des réductions de poids sont appliquées. Cette même approche s'étend à la couche de disponibilité des données. Selon la conception d'échantillonnage de la disponibilité des données de Celestia, les données passent d'une matrice k×k à une matrice 2k×2k. Grâce à de multiples cycles d'échantillonnage aléatoire et d'accumulation de probabilités, les nœuds légers peuvent établir une forte probabilité de disponibilité sans télécharger l'intégralité du bloc de données. Ceci offre une perspective transposable aux scénarios d'IA : face à des objets extrêmement volumineux et à un accès hautement concurrentiel, il n'est pas toujours nécessaire de vérifier la disponibilité par des téléchargements complets ; une confirmation statistique est plus réaliste pour les systèmes à grande échelle.
L'auditabilité des comportements repose sur l'ancrage sur la blockchain et le suivi des événements. La difficulté majeure de la gestion d'un système de stockage réside précisément dans le suivi des comportements : qui a téléchargé quoi, qui a modifié la politique, qui a déclenché la migration, et qui a invoqué des modèles sensibles et à quel moment. Si ces comportements ne sont pas agrégés dans un flux d'événements unifié, les litiges aboutiront inévitablement à des affirmations non fondées. Le rôle de la couche de gouvernance n'est pas d'inscrire chaque détail sur la blockchain, mais plutôt de disposer d'un ensemble minimal, définitif et vérifiable de preuves en cas de litige.
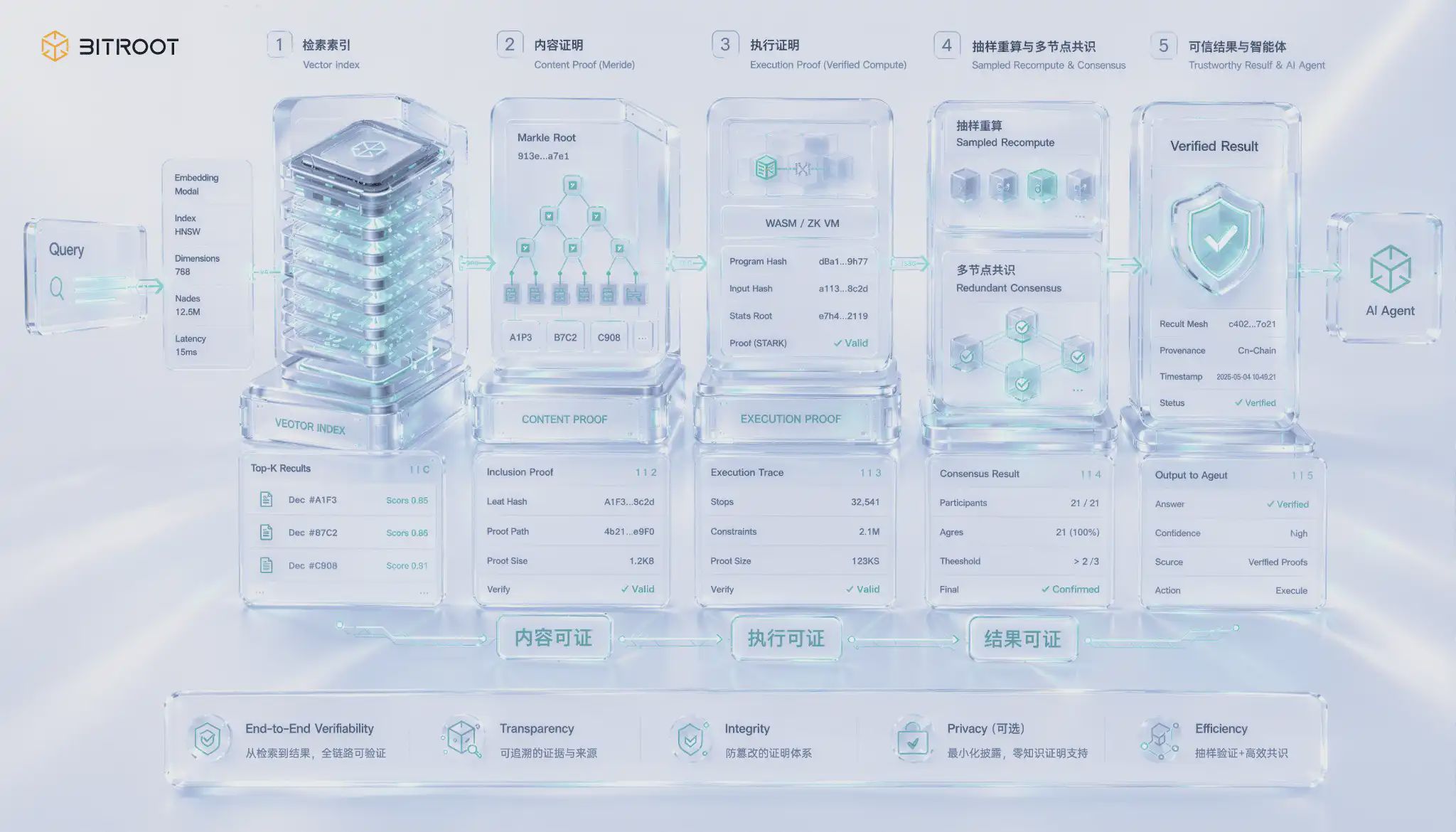
La récupération vérifiable est une spécificité des scénarios d'IA et représente également l'aspect le plus complexe. Le problème réside dans une lacune souvent négligée : renvoyer un résultat ne garantit pas son exactitude. Un nœud de récupération vectorielle peut aisément obtenir un index expiré, voire ignorer les voisins les plus proches, et renvoyer un résultat top-k apparemment pertinent, impossible à déceler à partir de la seule valeur de retour. La sortie de la récupération sémantique elle-même manque d'auto-vérification ; les erreurs ne sont pas signalées, mais elles réduisent subtilement la qualité du rappel et les performances du modèle. Lorsque les résultats de la récupération sont utilisés pour le règlement, l'autorisation ou les décisions sur la blockchain, cette lacune transforme un problème de qualité en un problème de confiance.
L'analyse de la vérifiabilité des résultats de recherche comprend trois niveaux d'assurance de complexité croissante. Le premier niveau concerne la vérifiabilité du contenu : il s'agit de prouver que le vecteur retourné appartient bien à une version d'index validée. Pour ce faire, on construit une structure de données d'authentification pour l'index, on utilise les engagements Merkle pour placer la racine de l'index sur la blockchain et on joint une preuve d'inclusion au résultat retourné afin de garantir que les nœuds n'ont ni falsifié ni altéré les données. Le deuxième niveau concerne la vérifiabilité de l'exécution : il s'agit de prouver que la requête a bien été exécutée sur la version validée et non sur un index modifié. Cela nécessite d'inclure le processus de requête dans le périmètre du calcul vérifiable. Le troisième niveau, le plus complexe, concerne la vérifiabilité des résultats : il s'agit de prouver que les k valeurs les plus proches retournées sont bien les voisins les plus proches selon une métrique donnée, et non des voisins plus proches qui ont été omis. Concrètement, cela implique de prouver la validité de la recherche approximative des plus proches voisins.
Fournir des preuves rigoureuses pour l'approximation des plus proches voisins en grande dimension à l'échelle de la production demeure un enjeu de pointe. Bien que les techniques cryptographiques telles que les preuves à divulgation nulle de connaissance progressent, la surcharge de preuve des opérations vectorielles en grande dimension est loin d'être acceptable pour une utilisation en ligne à grande échelle. Une solution d'ingénierie pragmatique consiste en une approche par couches plutôt qu'en une solution en une seule étape : premièrement, enregistrer la version de l'index et les paramètres de construction dans la blockchain pour garantir la traçabilité ; deuxièmement, effectuer un recalcul par échantillonnage des requêtes, en échantillonnant proportionnellement les requêtes en ligne pour les réexécuter sur des répliques de confiance et comparer les résultats, en utilisant la confiance statistique pour remplacer les preuves ligne par ligne ; simultanément, permettre à plusieurs nœuds indépendants d'effectuer des récupérations redondantes et de parvenir à un consensus sur les résultats retournés, augmentant ainsi le coût de la tricherie ponctuelle ; ce n'est qu'en cas de divergences lors de la comparaison ou du consensus que le processus doit s'intensifier pour un recalcul complet et une adjudication sur la blockchain des requêtes litigieuses. Cette approche s'aligne sur l'approche de vérification par échantillonnage en premier lieu dans les preuves de disponibilité : dans les systèmes à grande échelle, la confirmation statistique et l'escalade des litiges sont souvent plus réalisables que des preuves rigoureuses ligne par ligne.
Pour Bitroot, la récupération vérifiable n'est pas une simple fonction de stockage, mais fait partie intégrante du processus d'exécution sécurisée des agents d'IA. Si un agent on-chain s'appuie sur des bases de connaissances externes, des pondérations de modèles ou des index vectoriels pour prendre des décisions, le système doit pouvoir répondre à au moins trois questions : quelle version des données il utilise, quelle version du modèle il appelle et si le résultat renvoyé provient d'une version d'index enregistrée. Bitroot peut condenser ces informations en événements vérifiables on-chain, permettant ainsi à l'agent de dépasser la simple apparence d'intelligence pour devenir traçable, contestable et susceptible de faire l'objet d'un règlement.

Le véritable problème de la sélection : il ne s’agit pas de choisir un protocole, mais de créer une combinaison.
De nombreuses propositions sont rejetées car les questions sont mal formulées. La bonne approche ne consiste pas à déterminer s'il faut utiliser un protocole particulier, mais plutôt à définir la combinaison de données, les indicateurs cibles et les contraintes. Il est recommandé de suivre quatre étapes.
Commencez par réaliser un inventaire des données. Il convient au minimum de distinguer les données d'état, les données d'objet, les données de récupération et les données d'audit. Créez un modèle d'inventaire standardisé comportant au moins huit champs fixes : type de données, incrément quotidien, pic de concurrence, ratio lecture/écriture, durée de conservation, niveau de conformité, latence cible et plafond de coût. Une fois les champs standardisés, la communication et la sélection entre les équipes seront grandement facilitées.
Redéfinir les objectifs de niveau de service. Des paramètres spécifiques tels que la latence P95/P99, le temps de récupération (RTO), l'objectif de point de récupération (RPO), la cible de disponibilité et le plafond de coût par téraoctet doivent être clairement définis ; sinon, toutes les discussions ultérieures manqueront de point de référence.
Ensuite, établissez une cartographie des capacités. Associez les capacités telles que le stockage persistant, la preuve de disponibilité périodique, la récupération à faible latence et la gouvernance des accès aux différentes couches technologiques, au lieu de vous attendre à ce qu'une seule couche couvre tout.
Enfin, définissez les seuils de migration. Quelles données peuvent être hébergées de manière centralisée pendant la période de transition ? Quels indicateurs déclenchent la migration ? Quand le remplacement décentralisé doit-il être achevé ? Une approche pratique consiste à prédéfinir deux seuils : si le coût par téraoctet dépasse le budget pendant deux périodes statistiques consécutives, ou si la latence P95 dépasse l’objectif pendant deux semaines consécutives, une revue de migration de l’architecture sera automatiquement déclenchée. Sans seuils, il n’y a pas de gouvernance et la période de transition deviendra permanente.
Solution de mise en œuvre : une architecture à cinq couches qui intègre le stockage, la récupération et la gestion dans une boucle fermée.
La valeur d'une architecture ne réside pas dans le nombre de couches, mais dans sa capacité à former une boucle fermée vérifiable. S'appuyant sur le cadre précédent, la solution converge vers cinq couches : couche d'ancrage sur la blockchain, couche de stockage d'objets, couche de récupération d'index, couche de preuve de disponibilité et couche d'autorisation des clés. L'objectif est de faire de la vérifiabilité une capacité par défaut, des hautes performances une capacité configurable et de la gouvernance un processus exécutable.
Au sein de Bitroot, ces cinq couches peuvent être interprétées comme un module de gouvernance du stockage d'une pile d'IA : Parallel EVM fournit des capacités d'ancrage et de règlement à haute fréquence, Pipeline BFT assure un déterminisme à faible latence, le réseau de stockage distribué gère les objets volumineux et les données historiques, la couche de récupération d'index sert les agents d'IA et les appels d'application, la couche de preuve de disponibilité transforme la qualité de service du nœud en réputation et en récompenses, et la couche d'autorisation des clés relie la souveraineté de l'utilisateur, la protection de la vie privée et l'autorisation de commercialisation du modèle.
La couche d'ancrage on-chain ne stocke que les données minimales nécessaires : validation des données, empreinte de version, résumé des politiques d'autorisation et événement de règlement. Les objets volumineux ne sont pas stockés sur la chaîne ; seule une attestation prouvant l'existence et la version correcte de l'objet y est stockée. Ceci garantit la vérifiabilité sur la chaîne tout en évitant la saturation du débit par les fichiers volumineux.
Dans l'architecture de Bitroot, la couche d'ancrage on-chain ne se limite pas à l'enregistrement des hachages ; elle constitue un point d'entrée unique pour l'enregistrement des actifs d'IA, la gestion des permissions, la distribution des revenus et la résolution des litiges. Les ensembles de données, les pondérations des modèles, les index vectoriels et les journaux d'inférence peuvent être stockés hors chaîne de la manière la plus appropriée, mais leurs engagements de version, leur statut d'autorisation, les enregistrements d'appels et l'attribution des revenus doivent être intégrés à l'état on-chain de Bitroot. Ainsi, le stockage hors chaîne gère le volume, tandis que Bitroot garantit la confiance.
La couche de stockage objet héberge les données et utilise une stratégie hybride de codage d'effacement et de réplication : les objets à forte valeur ajoutée et à faible fréquence d'accès privilégient la tolérance aux pannes, tandis que les objets à valeur moyenne et à fréquence d'accès élevée privilégient l'efficacité de la récupération. Cette stratégie n'est pas statique et doit être ajustée dynamiquement en fonction de la fréquence d'accès et des besoins métier.
La couche d'indexation intègre les index de métadonnées et les index vectoriels dans un catalogue unifié. La couche active gère la recherche en ligne, tandis que la couche passive gère l'archivage et la reconstruction. Toutes les versions d'index doivent enregistrer la version des données sources et les paramètres de construction ; à défaut, il est impossible de suivre les dérives d'index.
La couche de preuve de disponibilité quantifie le comportement des nœuds. Le taux de réussite des réponses aux défis, la latence de réponse et le taux de réussite des réparations sont tous intégrés au score de réputation, qui est ensuite lié à l'allocation des récompenses afin d'éviter de récompenser la capacité sans récompenser la disponibilité.
L'accès et la conformité sont contrôlés par une couche de contrôle d'accès basée sur des clés. Les données hautement sensibles utilisent des clés hiérarchisées et une autorisation temporelle ; les journaux d'inférence sont stockés sous forme anonymisée avec possibilité de relecture des audits ; et les appels de modèles utilisent des autorisations révocables. Les opérations de contrôle d'accès elles-mêmes doivent également être consignées afin d'éviter toute dérive de configuration.
Ces cinq couches forment une boucle fermée au niveau de l'exécution, et non un pipeline unidirectionnel : après réception des données, celles-ci sont d'abord segmentées et encodées dans la couche objet, puis écrites. Un index est ensuite généré et ancré à la chaîne. Les requêtes en ligne transitent par la couche active, tandis que celles dont le nombre de résultats est insuffisant sont renvoyées vers la couche passive. Lorsque le résultat est renvoyé, des contrôles d'intégrité et d'autorisation sont déclenchés, et les actions critiques sont intégrées aux processus de règlement et d'audit. La véritable valeur de cette chaîne réside dans le fait que chaque nœud, à tout moment, peut répondre à quatre questions : d'où proviennent les données ? Quelle est leur version actuelle ? Qui a le droit d'y accéder ? Le système peut-il prouver qu'elles sont utilisables ?
C'est également une des principales raisons pour lesquelles Bitroot est parfaitement adapté à la gouvernance du stockage pour l'IA. Les invocations d'agents IA, les changements de version de modèles, les modifications d'autorisation de données et les litiges relatifs aux résultats de recherche ne sont pas des opérations backend peu fréquentes, mais des événements on-chain qui se produisent continuellement à mesure que les applications évoluent. Si la chaîne sous-jacente ne peut garantir une latence de confirmation suffisamment faible et un débit suffisamment élevé, la gouvernance du stockage devra finalement s'appuyer sur des tables off-chain et une réconciliation manuelle. La combinaison de Parallel EVM et de Pipeline BFT de Bitroot offre bien plus qu'un simple TPS plus élevé ; elle permet d'ancrer, de régler et de comptabiliser ces événements de gouvernance à haute fréquence en temps réel.

Qui paiera la facture ? Que les revenus soient déterminés par la disponibilité, et non par la capacité.
Pour que le stockage fonctionne durablement à long terme, les incitations doivent privilégier la disponibilité, et non la seule capacité. Récompenser uniquement la capacité revient à encourager indirectement les nœuds à empiler les disques durs et à fournir des services légers. Filecoin a résolu ce problème grâce à un mécanisme : le concept de puissance ajustée à la qualité. Ce mécanisme accorde une plus grande importance, en termes de puissance de calcul, aux secteurs qui reçoivent de véritables commandes de stockage, notamment les commandes valides et vérifiées (la plus petite unité d'espace de stockage). Ainsi, les récompenses sont davantage axées sur la capacité qui fournit réellement des services, plutôt que sur la simple capacité inutilisée. Cette approche mérite d'être envisagée pour toute couche d'incitation développée en interne.
Pour traduire cela en une fonction de récompense opérationnelle, il faut considérer simultanément au moins quatre dimensions, chacune avec une pondération clairement définie. La capacité détermine la part de base, indiquant l'espace alloué. Le taux de disponibilité et la latence de réponse déterminent le coefficient de qualité de service, indiquant si cet espace est réellement utile en cas de besoin ; ce coefficient doit être fortement pondéré, sinon la disponibilité n'est qu'un slogan. Le taux de réussite de la récupération des données détermine la fiabilité de la reprise après sinistre, indiquant si les répliques peuvent être reconstruites après la mise hors ligne d'un nœud ; il est directement lié à la préservation des données à faible trafic. La densité de valeur des données détermine le bonus lié à la demande ; il convient d'appliquer des multiplicateurs différenciés aux ensembles de données à forte valeur ajoutée et aux modèles à forte demande, permettant ainsi aux données rares et fréquemment consultées de recevoir une meilleure rémunération. Les récompenses doivent être attribuées aux services éprouvés, et non à la seule capacité déclarée.
Les incitations positives à elles seules ne suffisent pas ; le staking, les pénalités et l’arbitrage du côté des contraintes doivent être mis en œuvre simultanément, et une inégalité fondamentale doit être respectée : le bénéfice escompté de la tricherie doit être inférieur au coût escompté du brouillage ; sinon, tout mécanisme de preuve sera contourné par la rationalité économique. Le staking exige des nœuds qu’ils s’engagent à être disponibles moyennant un coût, et la taille de la mise doit être proportionnelle à la puissance de calcul et à la valeur des données qu’ils engagent. Dans la conception de Filecoin, les fournisseurs de stockage doivent payer une garantie initiale basée sur leur puissance de calcul engagée. Une défaillance pendant la fenêtre de preuve déclenche des frais de défaillance, et l’abandon définitif d’un secteur déclenche une pénalité de résiliation plus lourde. Ce système de pénalités à plusieurs niveaux fait la distinction entre les défaillances à court terme et les sorties malveillantes. L’arbitrage utilise des preuves sur la chaîne pour résoudre les litiges : lorsqu’un utilisateur déclare que des données sont indisponibles et qu’un nœud déclare un service normal, les enregistrements de contestation, les preuves d’échantillonnage et les journaux d’événements constituent une preuve d’adjudication lisible par machine, compressant les litiges qui nécessitaient initialement une intervention manuelle en un jugement vérifiable sur la chaîne.
Les scénarios d'IA nécessitent un niveau de gouvernance supplémentaire, encore plus complexe : comment répartir les bénéfices entre les trois parties prenantes ? Un modèle invoqué de manière répétée repose sur des contributeurs de données fournissant des corpus, des contributeurs de modèles investissant dans l'entraînement et des nœuds de stockage assurant l'hébergement. Ces trois parties contribuent à la valeur finale de l'appel, mais leurs contributions sont difficiles à observer directement. Une approche viable consiste à baser l'attribution de valeur sur des événements mesurables sur la blockchain : les appels sont facturés individuellement et réglés automatiquement. Les données et les modèles sont liés à chaque appel par des empreintes de version et des relations de traçabilité, puis répartis automatiquement selon un ratio de partage des revenus préprogrammé, évitant ainsi les litiges post-appel. Ce système s'accompagne de listes noires et de sanctions. En cas de téléchargement malveillant de données, de violation de droits d'auteur ou de vol de modèles, une fois l'arbitrage établi, les garanties sont saisies et les revenus ultérieurs sont gelés. Sans cela, un résultat contre-intuitif se produira : plus l'assetisation est réussie, plus les litiges concernant le partage des revenus et la confirmation de propriété se multiplieront, finissant par miner la confiance au sein même de l'écosystème.
La conformité n'est pas un correctif a posteriori, mais une contrainte inhérente à la phase architecturale : le socle de sécurité repose sur un chiffrement de bout en bout, une gestion des clés par couches et une rotation périodique, auxquels s'ajoutent la vérification du hachage et les engagements Merkle pour garantir la vérifiabilité des téléchargements. Ce socle est renforcé par de multiples réplicas et un codage d'effacement pour la reprise après sinistre. Côté confidentialité, un contrôle d'accès au moindre privilège est mis en œuvre au niveau des données, prenant en charge l'autorisation révocable, l'autorisation unique et l'autorisation temporaire, ainsi que la traçabilité complète des liens pour les accès et opérations critiques, facilitant ainsi la relecture des audits. La conformité est également l'étape la plus facilement reportable et la plus coûteuse : la localisation des données et les stratégies de transmission inter-domaines doivent être configurables, et les demandes de suppression, d'accès et d'audit doivent disposer d'interfaces de processus standard. Le principal défi réside dans le conflit inhérent entre immuabilité et possibilité de suppression. Une solution envisageable consiste à utiliser l'effacement chiffré combiné à l'invalidation de l'index : la destruction de la clé rend le texte chiffré irrécupérable, tandis que l'invalidation de l'index rend les données introuvables, satisfaisant ainsi l'exigence de suppression tout en conservant les enregistrements sur la blockchain. Le passage du projet pilote à la production se déroule en trois étapes : premièrement, établir une boucle de confiance minimale garantissant le bon fonctionnement du stockage des objets, de l’ancrage sur la blockchain, de la vérification d’intégrité et de la surveillance de base. Les tests d’acceptation portent sur la disponibilité, le taux de réussite des opérations de lecture/écriture, le taux de cohérence de l’ancrage et des versions des objets, ainsi que la capacité à simuler la récupération après incident. Deuxièmement, implémenter l’allocation des ressources IA et la gouvernance des index, en introduisant la gestion des ensembles de données et des modèles, la hiérarchie des versions, la stratification des index vectoriels (chauds/froids), les appels d’autorisation des modèles et l’enregistrement des sources de données d’entraînement. Les tests d’acceptation portent sur la traçabilité de l’entraînement, la restauration et l’auditabilité des modèles, la conformité de la latence de la couche chaude et l’impact contrôlable de la reconstruction des index. Enfin, implémenter la récupération vérifiable et la gouvernance automatisée, en introduisant les preuves de défi, la migration des politiques et les récompenses et pénalités automatisées. Les tests d’acceptation portent sur la couverture des preuves de disponibilité, la latence de gestion des risques, la réduction du coût unitaire et la traçabilité et la possibilité de restauration des modifications de politiques. Le système d’indicateurs est un système stratégique, et non un simple rapport. Si seuls les aspects techniques sont pris en compte sans considération des résultats commerciaux, la solution de stockage se transformera en un centre de coûts. Il est recommandé de le diviser en trois niveaux : des indicateurs techniques de base (disponibilité, latence P95/P99, débit, RTO/RPO, taux d’erreur) pour évaluer le bon fonctionnement du système ; des indicateurs spécifiques à l’IA (taux de traçabilité des données d’entraînement, taux de reproductibilité du modèle, couverture de la vérification des inférences, cohérence des indices) pour évaluer la qualité du modèle ; et des indicateurs de résultats commerciaux (croissance de l’offre de données, réduction du coût des appels, activité des nœuds, volume des transactions d’actifs) pour évaluer la création de valeur par le système. Une correspondance doit exister entre ces trois niveaux. L’objectif principal de ces indicateurs est d’alimenter l’optimisation stratégique, et non de servir de simples rapports.Les cinq principaux points de défaillance peuvent généralement être évités en amont : 1. Un stockage sans gouvernance des versions : l’existence des données ne garantit pas leur disponibilité, et la disponibilité ne garantit pas leur reproductibilité ; 2. Une capacité sans preuve de disponibilité : une rémunération basée sur la capacité incitera les services légers à privilégier cette dernière ; 3. Des niveaux de stockage chauds et froids sont mis en œuvre, mais sans stratégies de synchronisation, et la synchronisation des versions d’index ainsi que la gestion des invalidations ne sont pas bouclées ; 4. Des politiques de conformité retardées : plus les autorisations, les journaux, l’anonymisation et les réponses à la suppression sont traités tardivement, plus le coût est élevé ; 5. Une architecture transitoire sans mécanisme de sortie : la centralisation suivie de la décentralisation est une voie raisonnable, mais l’absence de seuils de migration consolidera l’état de transition et s’éloignera de l’objectif initial.
Boucle de rétroaction complète de Bitroot : des données aux modèles, en passant par l’agent IA
Au sein de cette boucle fermée, Bitroot peut transformer chaque action clé de ses ressources d'IA en un événement traçable : enregistrement des jeux de données, publication de versions de modèles, reconstruction d'index vectoriel, invocation d'agents d'IA, ancrage des journaux d'inférence, autorisation et révocation de permissions, contestations de litiges et résultats d'arbitrage. La blockchain n'a pas besoin de contenir toutes les données, mais elle doit conserver une trace minimale de ces actions. C'est la seule façon pour la relation de valeur entre les données, les modèles, la puissance de calcul et les applications de dépasser les simples promesses verbales et d'accéder à un registre partagé programmable et à une gouvernance auditable.
En appliquant ce mécanisme aux opérations et à l'expansion de l'écosystème Bitroot, les incitations au stockage ne devraient pas être conçues comme des subventions matérielles distinctes, mais plutôt comme une composante de la chaîne de valeur de l'AI Stack : les contributeurs de données sont rémunérés pour l'entraînement ou l'utilisation de leurs données, les contributeurs de modèles sont rémunérés pour leurs services de modélisation, les nœuds de stockage et de récupération sont rémunérés pour la disponibilité continue et la faible latence des services, et les nœuds de vérification et de validation sont rémunérés pour la détection d'indisponibilités, de dérives d'index ou d'anomalies d'autorisation. Ainsi, le système économique de Bitroot récompense non seulement les données « téléchargées », mais les données « dont l'utilité est constamment prouvée ».
Le stockage n'est pas un centre de coûts, mais un système de confiance et de distribution de valeur.
À l’ère de l’IA, le stockage distribué doit aborder quatre autres questions fondamentales : des preuves fiables et utilisables à long terme, un ordre de gouvernance collaborative inter-entités, des liens de responsabilité entre les données et les modèles, et des incitations économiques durables.
Une architecture mono-protocole et mono-couche ne peut atteindre ces objectifs. Une approche plus réaliste consiste en une architecture composite : l’adressage du contenu garantit l’intégrité, les preuves de stockage assurent la disponibilité dans le temps, une couche permanente garantit l’historique critique, une couche active garantit l’expérience en ligne et l’ancrage sur la blockchain assure une gouvernance et un règlement vérifiables. Il ne s’agit pas d’un compromis, mais d’une approche rationnelle. L’objectif de la mise en œuvre n’est pas d’obtenir la fonctionnalité la plus complète, mais d’établir d’abord une boucle de sécurité. Il faut d’abord mettre en place la boucle de sécurité la plus simple et fiable, puis ajouter progressivement, couche par couche, l’allocation des actifs par l’IA, la récupération vérifiable et la gouvernance automatisée.
Intégrée à une semaine d'actions, cette approche se résume à trois étapes : Jour 1 : Création d'un tableau d'inventaire des données à huit champs ; Jour 3 : Exécution d'un processus minimal (accès, stockage, récupération et vérification) dans un contexte métier réel ; Jour 7 : Réunion de bilan des seuils de migration (latence P95 et coût unitaire). La réalisation de ces trois étapes permet à l'équipe de passer d'un consensus conceptuel à un consensus technique.
Il convient également de reconnaître une limite pratique : quelle que soit la combinaison de protocoles utilisée, il existe des compromis entre coût, latence et durabilité ; aucune solution unique ne répond simultanément à tous les besoins de l’entreprise. Les solutions véritablement durables résultent d’itérations continues dans un cadre clairement défini, plutôt que de configurations statiques à long terme imposées après une décision unique.
À l'avenir, ce qui entraînera souvent l'échec d'un projet ne sera plus un faible nombre de transactions par seconde (TPS), mais plutôt une chaîne de responsabilité des données mal définie. À l'ère des blockchains publiques basées sur l'IA, le stockage ne consiste plus à y déposer des données, mais à garantir leur traçabilité à tout moment.
Conclusion
La véritable concurrence entre les blockchains publiques d'IA ne se limitera pas à la comparaison du nombre de transactions par seconde (TPS), des frais de gaz ou du temps de confirmation. La performance est un point de départ, mais pas une fin en soi. À l'ère des applications natives d'IA, les systèmes on-chain devront gérer bien plus que de simples transactions ; ils devront également inclure le versionnage des données, l'invocation de modèles, la planification de la puissance de calcul, les enregistrements d'inférence, le comportement des agents et la distribution des bénéfices entre les différentes parties prenantes.
C’est également l’avis de Bitroot sur la couche de stockage : celle-ci n’est pas un module auxiliaire, mais bien la couche de la pile d’IA la plus proche de la source de valeur. La viabilité à long terme d’un réseau d’IA décentralisé dépend de la possibilité de prouver l’intégrité des données, de reproduire les modèles, d’auditer les appels et de distribuer automatiquement les revenus.
Bitroot vise à construire non seulement une blockchain privilégiant une exécution plus rapide, mais aussi une infrastructure permettant de vérifier, d'invoquer, de régler et de gouverner les actifs d'IA. L'EVM parallèle et le BFT en pipeline assurent la capacité de gérer les événements à haute fréquence sur la blockchain, le stockage distribué et les mécanismes de vérification garantissent la confiance dans les données et les modèles d'IA, tandis que le registre programmable et la gouvernance sur la blockchain transforment les contributions en incitations économiques durables.
Lorsque les agents d'IA commenceront à agir au nom des utilisateurs, lorsque les modèles et les données deviendront des actifs négociables, et lorsque la puissance de calcul, le stockage et les services d'inférence intégreront le même réseau de valeur, le stockage ne sera plus une question de « où mettre les fichiers ».
Elle deviendra le fondement de la confiance pour les blockchains publiques d'IA et le système de distribution de valeur pour la prochaine génération de réseaux intelligents.
Pour Bitroot, ce qui comptera vraiment à l'avenir, ce n'est pas qui possède le plus de données, mais qui peut rendre ces données vérifiables, accessibles et traçables à tout moment, et finalement participer au règlement de leur valeur.
À propos de Bitroot
Bitroot est un projet de blockchain publique de couche 1 axé sur l'exécution parallèle et une architecture native pour l'IA. Bitroot adopte une feuille de route technologique compatible avec l'EVM et explore des solutions pour fournir un environnement d'exécution on-chain performant et économique pour les agents d'IA, la DeFi et les applications Web3 grâce à des mécanismes d'exécution parallèle, l'optimisation du consensus et une conception d'interface dédiée à l'IA.
Cet article est une contribution et ne représente pas les opinions de BlcokBeats.
Cliquez ici pour en savoir plus sur les offres d'emploi chez BlockBeats.
Bienvenue dans la communauté officielle BlockBeats :
Groupe d'abonnement Telegram : https://t.me/theblockbeats
Groupe Telegram : https://t.me/BlockBeats_App
Compte Twitter officiel : https://twitter.com/BlockBeatsAsia
#Bitroot
Rapport/Correction
Articles connexesLa blockchain publique Bitroot a été invitée à participer à la conférence Tencent Cloud Singapore sur l'IA, où elle a partagé la scène avec Solana pour discuter de l'avenir.

Lancement officiel de B.AI : construction des fondements financiers des agents IA et pilotage de la logique commerciale sous-jacente de l’ère de l’IA générale.

Analyse approfondie de la technologie EVM parallélisée de Bitroot : conception et implémentation d’une architecture blockchain haute performance
