Le cycle de hype autour de l'IA semble familier. Si tu étais dans le crypto entre 2017 et 2021, tu connais le schéma : promesses énormes, tours de financement encore plus gros, tout le monde prétendant qu'il « construit l'avenir. » Les slides sont parfaits. Les roadmaps sont audacieuses. La tokenomics est « révolutionnaire. »
Avance rapide vers l'IA en 2026 et le script est le même. Il suffit d'échanger « finance décentralisée » contre « intelligence artificielle. »
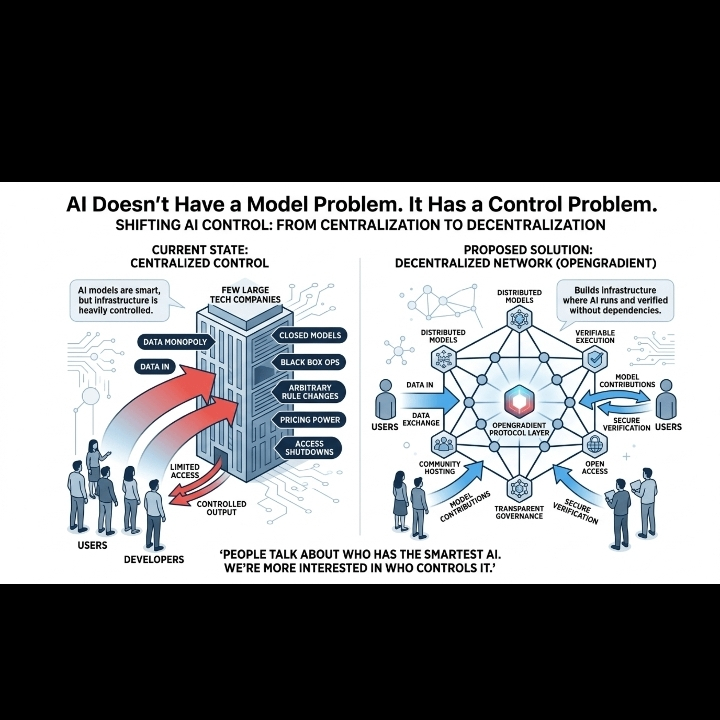
Mais il y a une question que la plupart des démos évitent : *Qui contrôle réellement cela ?*
*1. Le piège centralisé caché sous l'« innovation »*
En ce moment, une poignée d'entreprises décide quels modèles d'IA sont formés, qui obtient l'accès API, quels prompts sont autorisés, et quel est le prix. Changer les conditions de service du jour au lendemain ? Accès perdu. Augmenter les prix API de 5x ? Tout le monde le paie ou ferme boutique. Interdire un cas d'utilisation ? Des millions d'applications échouent.
C’est sur cette fondation que nous construisons le « futur de l’IA ». Serveurs centralisés. Clés centralisées. Règles centralisées.
On nous dit que l'IA sera partout. Dans vos applications, votre travail, vos appareils. Mais si l'infrastructure derrière cela est détenue par 3-4 acteurs, alors « partout » signifie vraiment « partout où ils le permettent ».
Ce n'est pas de l'innovation. Ce ne sont que de nouveaux gardiens avec des GPU plus rapides.
*2. Le vrai problème n'est pas le QI du modèle*
Oui, les modèles deviennent plus intelligents. Précision améliorée de 2%. Inference 10% plus rapide. Nouveaux records de benchmarks chaque mois.
Mais les benchmarks ne comptent pas si vous ne pouvez pas exécuter le modèle vous-même. Si vous ne pouvez pas vérifier ce qu'il fait. Si vous ne pouvez pas auditer les données sur lesquelles il a été formé. Si vous ne pouvez pas garantir qu'il ne sera pas éteint demain.
Un modèle qui est 2% plus intelligent mais 100% contrôlé par quelqu'un d'autre n'est pas de la liberté. C'est une location. Et les locataires ne construisent pas des systèmes durables.
Le problème plus difficile, le problème moins sexy, c'est l'infrastructure. Qui l'héberge. Qui vérifie. Qui paie. Qui décide des règles.
C'est ça le problème de contrôle. Et OpenGradient essaie de le résoudre.
*3. Ce que fait réellement #OpenGradient*
Oubliez les feuilles de route sophistiquées un instant. L'idée principale est simple :
Construisez un réseau décentralisé où les modèles d'IA peuvent être hébergés, exécutés et vérifiés sans qu'une seule entreprise soit au milieu.
Pas de PDG unique qui peut interdire votre application. Pas de département de facturation unique qui peut multiplier vos coûts par 10. Pas de ferme de serveurs unique qui devient un goulot d'étranglement ou un vecteur d'attaque.
Les modèles vivent sur un réseau distribué. N'importe qui peut héberger. N'importe qui peut exécuter. N'importe qui peut vérifier la sortie. Le système ne dépend pas de l'autorisation d'une autorité centrale.
C'est la même philosophie qui a rendu la crypto intéressante quand il s'agissait de résistance à la censure, pas juste des prix de jetons. Appliquez cela au calcul d'IA.
Peut-être que ça fonctionne. Peut-être que ça ne fonctionne pas. La plupart des projets ne le font pas. Mais au moins, ça vise la bonne cible.
*4. Pourquoi le « contrôle » bat le « plus intelligent » à chaque fois*
Les gens débattent sans cesse de quel laboratoire a le modèle le plus intelligent. GPT contre Claude contre Gemini contre open-source.
Mais l'histoire montre que les vraies guerres ne concernent pas le QI. Elles concernent le contrôle.
Qui possède les chemins de fer ? Qui possède les câbles Internet ? Qui possède les boutiques d'applications ? Les gagnants n'étaient pas toujours la meilleure technologie. Ce sont ceux qui contrôlaient les rails que tout le monde devait utiliser.
L'IA suivra le même chemin. Le modèle le plus intelligent aujourd'hui sera de niveau intermédiaire dans 18 mois. C’est juste comme ça que la tech évolue.
Mais celui qui contrôle l'infrastructure - l'endroit où les modèles sont hébergés, facturés et gouvernés - c'est là que le pouvoir réside à long terme.
Si l'IA devient le nouvel internet, voulons-nous qu'elle fonctionne sur 3 serveurs d'entreprise ? Ou sur un réseau ouvert où aucune entité unique ne peut couper le courant ?
*5. Le pari qu'OpenGradient fait*
Le pari d'OpenGradient est que la décentralisation compte plus qu'une autre victoire de benchmark.
C'est parier que les développeurs, entreprises et utilisateurs se soucieront finalement plus de la souveraineté que de la commodité. Que « je ne peux pas être déplatformé » devient aussi important que « mon modèle est 2% plus rapide ».
C'est un pari à long terme. Les systèmes décentralisés sont plus désordonnés. Plus lents à démarrer. Plus difficiles à commercialiser.
Mais les systèmes centralisés échouent de manière prévisible : hausses de prix, interdictions d'accès, changements de règles, points de défaillance uniques. Nous l'avons vu dans le cloud computing. Nous l'avons vu dans les médias sociaux. Nous le voyons maintenant dans les API d'IA.
Donc la question n’est pas « OpenGradient est-il parfait ? » La question est « que se passe-t-il avec l’IA si personne ne résout le problème de contrôle ? »
*En résumé*
L'IA n'a pas de problème de modèle. Les modèles s'améliorent rapidement.
L'IA a un problème de contrôle. Et les problèmes de contrôle ne se résolvent pas en rendant les modèles 2% plus intelligents. Ils se résolvent en changeant qui possède l'infrastructure.
OpenGradient pourrait être en avance. Il pourrait échouer. La plupart des projets échouent. Mais au moins, il est dirigé vers le bon problème : pas qui construit l'IA la plus intelligente, mais qui décide comment l'IA fonctionne.
Parce que celui qui contrôle la fondation, contrôle le futur