Auteur : 0xjacobzhao | https://linktr.ee/0xjacobzhao
Ce rapport de recherche indépendant est soutenu par IOSG Ventures, le processus de recherche et d'écriture a été inspiré par le rapport de recherche sur l'apprentissage par renforcement de Sam Lehman (Pantera Capital), merci à Ben Fielding (Gensyn.ai), Gao Yuan (Gradient), Samuel Dare & Erfan Miahi (Covenant AI), Shashank Yadav (Fraction AI), Chao Wang pour leurs précieux commentaires sur cet article. Cet article s'efforce d'être objectif et précis, certaines opinions impliquent un jugement subjectif, des biais sont inévitables, nous prions les lecteurs de bien vouloir comprendre.
L'intelligence artificielle passe d'un apprentissage statistique principalement basé sur le "fitting de modèles" à un système de capacités centré sur le "raisonnement structuré", l'importance du post-entraînement (Post-training) augmente rapidement. L'apparition de DeepSeek-R1 marque un renversement de paradigme pour l'apprentissage par renforcement à l'ère des grands modèles, un consensus se forme dans l'industrie : le pré-entraînement construit la base des capacités générales des modèles, l'apprentissage par renforcement n'est plus seulement un outil d'alignement de valeur, mais a prouvé qu'il peut systématiquement améliorer la qualité des chaînes de raisonnement et la capacité de prise de décision complexe, évoluant progressivement vers un chemin technique pour améliorer continuellement le niveau d'intelligence.
Parallèlement, Web3 redéfinit les relations de production de l'IA à travers un réseau de puissance de calcul décentralisé et un système d'incitation cryptographique, tandis que les exigences structurelles de l'apprentissage renforcé en matière d'échantillonnage de rollout, de signaux de récompense et d'entraînement vérifiable s'alignent naturellement avec la coopération en matière de puissance de calcul, la distribution des incitations et l'exécution vérifiable de la blockchain. Ce rapport analysera systématiquement le paradigme d'entraînement de l'IA et les principes techniques de l'apprentissage renforcé, démontrant les avantages structurels de l'apprentissage renforcé × Web3, et analysera des projets tels que Prime Intellect, Gensyn, Nous Research, Gradient, Grail et Fraction AI.
I. Trois phases de l'entraînement de l'IA : pré-entraînement, ajustement d'instruction et alignement post-entraînement
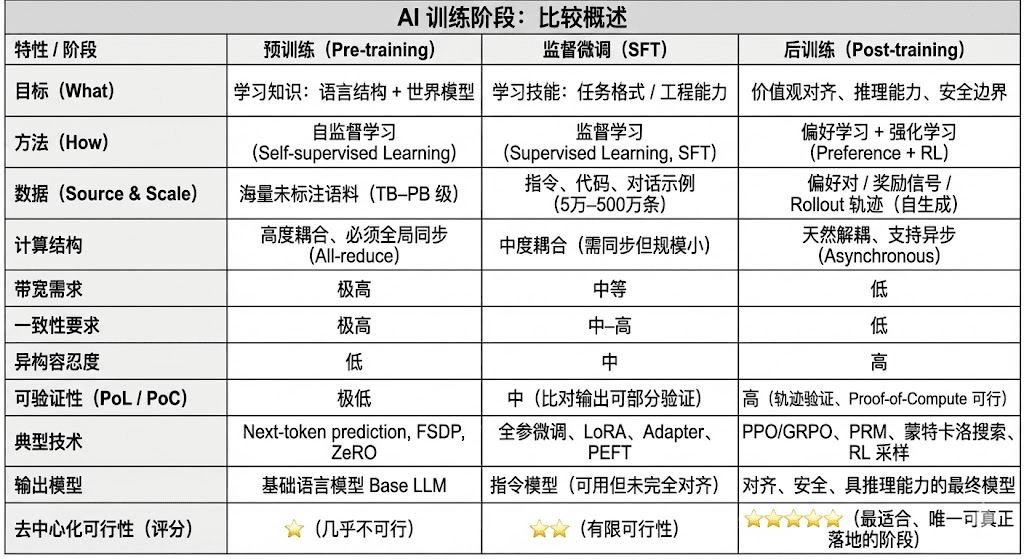
Le cycle de vie complet de l'entraînement des modèles de langage modernes (LLM) est généralement divisé en trois phases clés : pré-entraînement (Pre-training), ajustement supervisé (SFT) et post-entraînement (Post-training/RL). Elles remplissent respectivement les fonctions de "construction d'un modèle du monde - injection de capacité de tâche - formation de raisonnement et de valeurs", dont les structures de calcul, les exigences de données et la difficulté de vérification déterminent le degré d'adéquation à la décentralisation.
Le pré-entraînement (Pre-training) construit la structure statistique linguistique et le modèle du monde multimodal du modèle à travers un apprentissage auto-supervisé à grande échelle, étant la base des capacités LLM. Cette phase nécessite un entraînement sur des corpus de trillions de manière synchronisée à l'échelle mondiale, s'appuyant sur des grappes homogènes de milliers à des dizaines de milliers de H100, avec des coûts représentant jusqu'à 80–95 %, extrêmement sensibles à la bande passante et aux droits d'auteur des données, devant donc être complétés dans un environnement hautement centralisé.
Le réglage (Supervised Fine-tuning) est utilisé pour injecter des capacités de tâche et des formats d'instruction, avec un volume de données réduit, représentant environ 5–15 % des coûts ; le réglage peut se faire par entraînement de tous les paramètres ou en utilisant des méthodes de réglage efficaces en paramètres (PEFT), parmi lesquelles LoRA, Q-LoRA et Adapter sont les plus courantes dans l'industrie. Cependant, il nécessite toujours la synchronisation des gradients, limitant ainsi son potentiel de décentralisation.
Le post-entraînement (Post-training) est constitué de plusieurs sous-phases itératives, déterminant la capacité de raisonnement du modèle, ses valeurs et ses limites de sécurité, ses méthodes incluant à la fois des systèmes d'apprentissage renforcé (RLHF, RLAIF, GRPO) et des méthodes d'optimisation des préférences non renforcées (DPO), ainsi que des modèles de récompense de processus (PRM). Cette phase a une quantité de données et des coûts relativement faibles (5–10 %), principalement concentrés sur le Rollout et la mise à jour des stratégies ; elle soutient naturellement l'exécution asynchrone et distribuée, les nœuds n'ayant pas besoin de détenir l'intégralité des poids, et en combinant des calculs vérifiables avec des incitations sur chaîne, elle peut former un réseau d'entraînement décentralisé ouvert, étant la phase d'entraînement la mieux adaptée à Web3.
II. Panorama technologique de l'apprentissage renforcé : architectures, cadres et applications
2.1 Architecture système de l'apprentissage renforcé et éléments clés
L'apprentissage renforcé (Reinforcement Learning, RL) stimule l'amélioration autonome des capacités décisionnelles du modèle grâce à "l'interaction environnementale - retour d'information sur les récompenses - mise à jour de la stratégie" ; sa structure centrale peut être considérée comme un cycle de rétroaction composé d'états, d'actions, de récompenses et de stratégies. Un système RL complet comprend généralement trois types de composants : Policy (réseau de stratégies), Rollout (échantillonnage d'expérience) et Learner (mise à jour de stratégie). L'interaction entre la stratégie et l'environnement génère des trajectoires ; le Learner met à jour la stratégie en fonction des signaux de récompense, formant ainsi un processus d'apprentissage itératif et optimisé en continu :
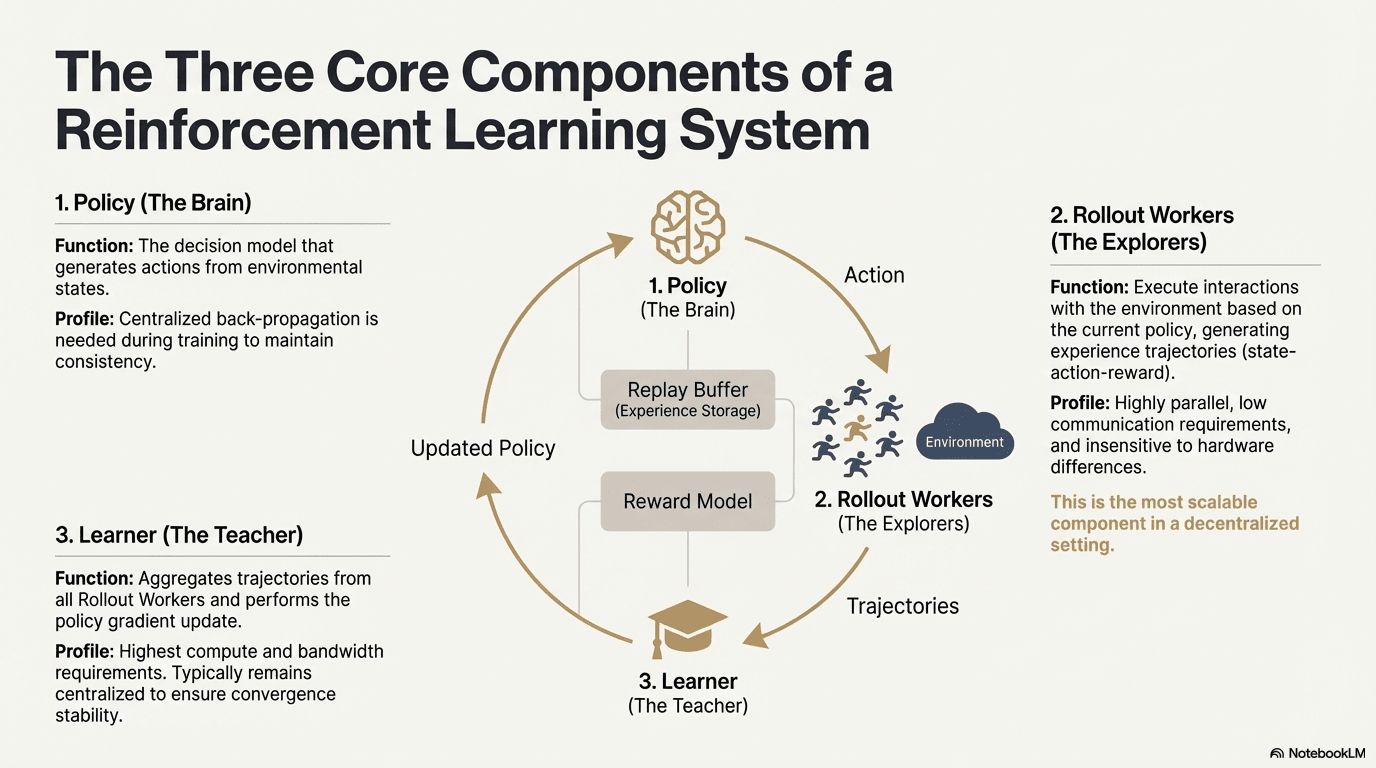
Réseau de stratégies (Policy) : génère des actions à partir de l'état de l'environnement, étant le cœur de la décision du système. Pendant l'entraînement, un rétropropagation centralisée est nécessaire pour maintenir la cohérence ; lors de l'inférence, elle peut être distribuée à différents nœuds pour fonctionner en parallèle.
Échantillonnage d'expérience (Rollout) : les nœuds interagissent avec l'environnement en exécutant la stratégie, générant des trajectoires d'état-action-récompense, etc. Ce processus est hautement parallèle, avec une communication très faible, et est le mieux adapté à l'expansion dans un environnement décentralisé en raison de sa faible sensibilité aux différences matérielles.
Apprenant (Learner) : agrège toutes les trajectoires de Rollout et exécute la mise à jour des gradients de stratégie, étant le seul module ayant les exigences les plus élevées en matière de puissance de calcul et de bande passante, il est donc généralement déployé de manière centralisée ou légèrement centralisée pour garantir la stabilité de la convergence.
2.2 Cadre de phase d'apprentissage renforcé (RLHF → RLAIF → PRM → GRPO)
L'apprentissage renforcé peut généralement être divisé en cinq étapes, le processus global étant décrit comme suit :
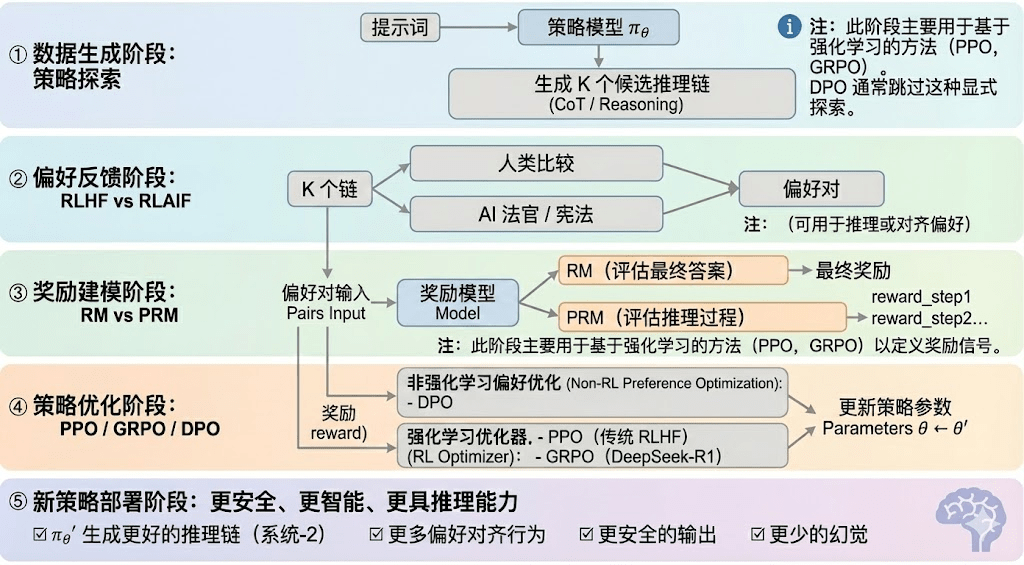
Phase de génération de données (Policy Exploration) : sous la condition d'invites d'entrée données, le modèle de stratégie πθ génère plusieurs chaînes d'inférence candidates ou des trajectoires complètes, fournissant une base d'échantillons pour l'évaluation des préférences et la modélisation des récompenses, déterminant ainsi l'étendue de l'exploration de la stratégie.
Phase de retour de préférences (RLHF / RLAIF) :
RLHF (Reinforcement Learning from Human Feedback) optimise les sorties du modèle par le biais de réponses multiples, d'annotations de préférences humaines et de modèles de récompense (RM) entraînés, en utilisant PPO pour rendre les sorties du modèle plus conformes aux valeurs humaines, étant une étape clé dans la transition de GPT-3.5 à GPT-4.
RLAIF (Reinforcement Learning from AI Feedback) remplace l'annotation humaine par un juge AI ou des règles de type constitutionnelles, automatisant l'acquisition des préférences, réduisant considérablement les coûts et présentant des caractéristiques d'évolutivité, devenant le paradigme d'alignement dominant pour des entreprises comme Anthropic, OpenAI et DeepSeek.
Phase de modélisation des récompenses (Reward Modeling) : les préférences sont mappées à un modèle de récompenses d'entrée, apprenant à mapper les sorties en récompenses. RM enseigne au modèle "qu'est-ce que la bonne réponse", PRM enseigne au modèle "comment raisonner correctement".
RM (Modèle de Récompense) évalue la qualité de la réponse finale, ne notant que la sortie :
Modèle de récompense de processus PRM (Process Reward Model) évalue non seulement la réponse finale, mais attribue également des scores pour chaque étape de raisonnement, chaque token, chaque segment logique, étant également une technologie clé d'OpenAI o1 et DeepSeek-R1, apprenant essentiellement à "comment penser" au modèle.
Phase de vérification des récompenses (RLVR / Reward Verifiability) : introduit des "contraintes vérifiables" dans le processus de génération et d'utilisation des signaux de récompense, afin de garantir que les récompenses proviennent autant que possible de règles, de faits ou de consensus reproductibles, réduisant ainsi les risques de hacking de récompense et de biais, tout en améliorant l'auditabilité et l'évolutivité dans un environnement ouvert.
Phase d'optimisation des stratégies (Policy Optimization) : mise à jour des paramètres de stratégie θ guidée par les signaux fournis par le modèle de récompenses, pour obtenir une stratégie πθ′ avec une capacité de raisonnement plus forte, une sécurité accrue et un comportement plus stable. Les méthodes d'optimisation dominantes comprennent :
PPO (Proximal Policy Optimization) : l'optimiseur traditionnel de RLHF, connu pour sa stabilité, mais souvent confronté à des limitations de convergence lente et de stabilité insuffisante dans des tâches de raisonnement complexes.
GRPO (Group Relative Policy Optimization) : l'innovation clé de DeepSeek-R1, qui estime la valeur d'attente en modélisant la distribution des avantages au sein d'un groupe de réponses candidates, plutôt qu'un simple classement. Cette méthode conserve les informations sur l'amplitude des récompenses, étant plus adaptée à l'optimisation des chaînes de raisonnement, et le processus d'entraînement est plus stable, considérée comme un cadre important d'optimisation d'apprentissage renforcé pour des scénarios de raisonnement avancés après PPO.
DPO (Direct Preference Optimization) : méthode de post-entraînement non renforcée : ne génère pas de trajectoires, ne construit pas de modèle de récompense, mais optimise directement sur les préférences, ce qui est peu coûteux et stable, donc largement utilisé pour l'alignement de modèles open source comme Llama, Gemma, etc., mais n'améliore pas la capacité de raisonnement.
Phase de déploiement de nouvelle stratégie (New Policy Deployment) : le modèle optimisé se traduit par : une capacité renforcée à générer des chaînes de raisonnement (System-2 Reasoning), un comportement plus conforme aux préférences humaines ou AI, un taux d'illusion plus faible et une sécurité accrue. Le modèle apprend en continu les préférences, optimise le processus et améliore la qualité des décisions, formant ainsi une boucle fermée.

2.3 Cinq grandes catégories d'applications industrielles de l'apprentissage renforcé
L'apprentissage renforcé (Reinforcement Learning) a évolué des premières intelligences de jeu vers un cadre central de décision autonome inter-industries, ses cas d'utilisation étant regroupés par maturité technologique et degré de mise en œuvre industrielle, et ayant propulsé des percées clés dans chacune de ses directions.
Systèmes de jeux et de stratégies (Game & Strategy) : c'est la première direction validée pour RL, où RL a démontré une intelligence décisionnelle capable de rivaliser, voire de surpasser, celle des experts humains dans des environnements tels qu'AlphaGo, AlphaZero, AlphaStar, OpenAI Five, caractérisés par des "informations parfaites + récompenses explicites", posant ainsi les bases des algorithmes modernes de RL.
Robotique et intelligence incarnée (Embodied AI) : RL apprend aux robots à contrôler, à modéliser la dynamique et à interagir avec l'environnement, apprenant à réaliser des tâches de contrôle et cross-modal (comme RT-2, RT-X), se dirigeant rapidement vers l'industrialisation, étant la voie clé pour la mise en œuvre de la robotique dans le monde réel.
Raisonnement numérique (Digital Reasoning / LLM System-2) : RL + PRM propulsent les grands modèles de la "mimétisme linguistique" vers le "raisonnement structuré", avec des résultats tels que DeepSeek-R1, OpenAI o1/o3, Anthropic Claude et AlphaGeometry, son essence étant d'optimiser les récompenses au niveau des chaînes de raisonnement, plutôt que de simplement évaluer la réponse finale.
Découverte scientifique automatisée et optimisation mathématique (Scientific Discovery) : RL recherche des structures ou stratégies optimales dans des espaces de recherche complexes, non étiquetés et avec des récompenses complexes, ayant déjà réalisé des percées fondamentales telles qu'AlphaTensor, AlphaDev et Fusion RL, montrant des capacités d'exploration dépassant l'intuition humaine.
Systèmes de décision économique et de trading (Economic Decision-making & Trading) : RL est utilisé pour l'optimisation des stratégies, le contrôle des risques à haute dimension et la génération de systèmes de trading adaptatifs, apprenant à se maintenir dans des environnements incertains, constitutif essentiel de la finance intelligente.
III. La correspondance naturelle entre l'apprentissage renforcé et Web3
L'adéquation élevée de l'apprentissage renforcé (RL) avec Web3 découle du fait que les deux sont essentiellement des "systèmes motivés par des incitations". Le RL dépend des signaux de récompense pour optimiser les stratégies, tandis que la blockchain s'appuie sur des incitations économiques pour coordonner le comportement des participants, rendant les deux intrinsèquement cohérents au niveau mécanique. Les demandes fondamentales du RL - Rollout hétérogène à grande échelle, distribution des récompenses et vérification de l'authenticité - sont précisément les avantages structurels de Web3.
Découplage de l'inférence et de l'entraînement : le processus d'entraînement de l'apprentissage renforcé peut être clairement divisé en deux phases :
Rollout (échantillonnage d'exploration) : le modèle génère une grande quantité de données basé sur la stratégie actuelle ; c'est une tâche intensive en calcul mais peu en communication. Il n'exige pas de communication fréquente entre les nœuds, ce qui le rend adapté à une génération parallèle sur des GPU de consommation distribués dans le monde entier.
Mise à jour (mise à jour des paramètres) : mise à jour des poids du modèle basée sur les données collectées, nécessitant des nœuds centralisés à haute bande passante.
Le "découplage inférence-formation" s'intègre naturellement à la structure de puissance hétérogène décentralisée : le Rollout peut être externalisé à un réseau ouvert, réglé par des mécanismes de contribution via un système de jetons, tandis que la mise à jour du modèle reste centralisée pour garantir la stabilité.
Vérifiabilité (Verifiability) : ZK et Proof-of-Learning fournissent des moyens de vérifier si les nœuds exécutent réellement les inférences, résolvant ainsi les problèmes d'honnêteté dans les réseaux ouverts. Pour des tâches déterministes telles que le code ou le raisonnement mathématique, les validateurs n'ont qu'à vérifier les réponses pour confirmer la charge de travail, augmentant considérablement la crédibilité des systèmes RL décentralisés.
Couche d'incitation, mécanisme de production de retour basé sur l'économie des jetons : le mécanisme des jetons de Web3 peut directement récompenser les contributeurs de rétroaction de préférences RLHF/RLAIF, rendant la génération de données de préférences transparente, réglable et sans autorisation ; le staking et le slashing (Staking/Slashing) contraignent encore davantage la qualité des retours, formant un marché de retour plus efficace et aligné que la collecte de fonds traditionnelle.
Potentiel de l'apprentissage multi-agents (MARL) : la blockchain est essentiellement un environnement multi-agents ouvert, transparent et en évolution continue, où les comptes, les contrats et les agents ajustent constamment leurs stratégies sous l'incitation, ce qui lui confère un potentiel naturel pour construire de vastes expérimentations MARL. Bien que cela soit encore à ses débuts, ses caractéristiques d'ouverture, d'exécution vérifiable et d'incitations programmables offrent des avantages fondamentaux pour le développement futur de MARL.
IV. Analyse des projets classiques Web3 + apprentissage renforcé
Sur la base du cadre théorique ci-dessus, nous allons analyser brièvement les projets les plus représentatifs de l'écosystème actuel :
Prime Intellect : Paradigme d'apprentissage renforcé asynchrone prime-rl
Prime Intellect s'engage à construire un marché mondial ouvert de puissance de calcul, réduisant les barrières à l'entraînement, promouvant l'entraînement décentralisé collaboratif, et développant une pile technologique complète d'intelligence super ouverte. Son système comprend : Prime Compute (environnement de puissance de calcul unifié/cloud distribué), la famille de modèles INTELLECT (10B–100B+), le centre d'environnement d'apprentissage renforcé ouvert (Environments Hub), ainsi qu'un moteur de données synthétiques à grande échelle (SYNTHETIC-1/2).
Le composant d'infrastructure clé de Prime Intellect, le cadre prime-rl, est conçu pour les environnements asynchrones et distribués et est fortement lié à l'apprentissage renforcé, les autres comprenant le protocole de communication OpenDiLoCo qui surmonte les goulets d'étranglement de bande passante, le mécanisme de vérification TopLoc garantissant l'intégrité des calculs, etc.
Aperçu des composants d'infrastructure clés de Prime Intellect

Fondation technique : cadre d'apprentissage renforcé asynchrone prime-rl
prime-rl est le moteur d'entraînement central de Prime Intellect, conçu pour des environnements décentralisés asynchrones à grande échelle, réalisant un découplage complet entre l'inférence à haut débit et les mises à jour stables via Actor–Learner. Les exécutants (Rollout Workers) et les apprenants (Trainers) ne sont plus bloqués de manière synchrone, les nœuds peuvent se connecter ou se déconnecter à tout moment, nécessitant simplement de tirer en continu la dernière stratégie et de télécharger les données générées :
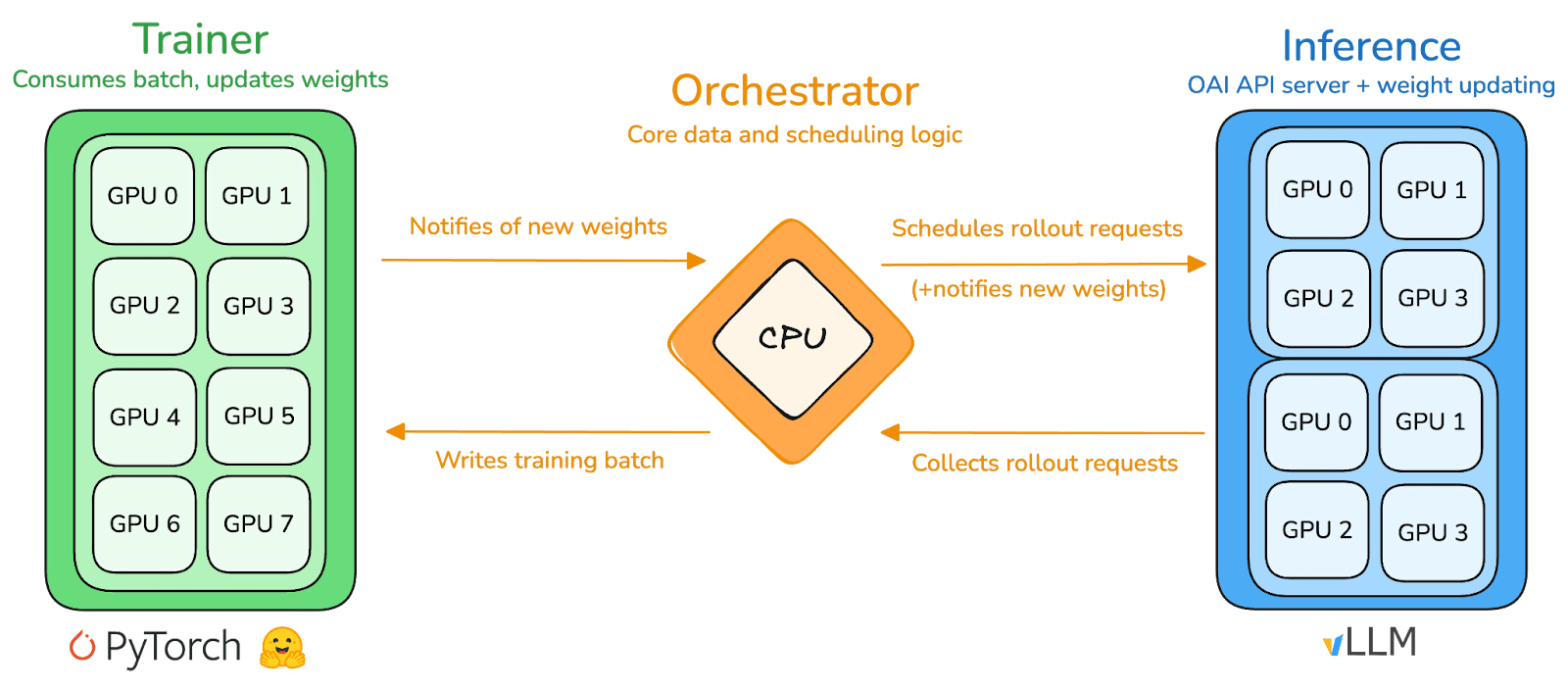
Exécutants Actor (Travailleurs de Rollout) : responsables de l'inférence des modèles et de la génération de données. Prime Intellect intègre de manière innovante le moteur d'inférence vLLM au niveau de l'Actor. La technologie PagedAttention de vLLM et la capacité de traitement par lots continus (Continuous Batching) permettent à l'Actor de générer des trajectoires d'inférence avec un débit extrêmement élevé.
Apprenant Learner (Entraîneur) : responsable de l'optimisation des stratégies. Learner tire des données de manière asynchrone à partir d'un tampon de retour d'expérience partagé (Experience Buffer) pour effectuer des mises à jour de gradients, sans avoir besoin d'attendre que tous les Actors terminent le lot actuel.
Coordinateur (Orchestrator) : responsable de la planification des poids de modèle et des flux de données.
Points d'innovation clés de prime-rl :
Vraie asynchronie (True Asynchrony) : prime-rl abandonne le paradigme synchrone traditionnel de PPO, ne pas attendre les nœuds lents, sans alignement de lots, permettant à un nombre arbitraire de GPU de performances variées de se connecter à tout moment, établissant la faisabilité de l'apprentissage renforcé décentralisé.
Intégration profonde de FSDP2 et MoE : à travers le découpage de paramètres FSDP2 et l'activation éparse de MoE, prime-rl permet d'entraîner efficacement des modèles de dizaines de milliards dans des environnements distribués, l'Actor n'activant que les experts actifs, réduisant considérablement la mémoire et les coûts d'inférence.
GRPO+ (Group Relative Policy Optimization) : GRPO élimine le réseau Critique, réduisant significativement les coûts de calcul et de mémoire, s'adaptant naturellement aux environnements asynchrones, le GRPO+ de prime-rl garantissant en outre une convergence fiable dans des conditions de latence élevée.
La famille de modèles INTELLECT : symbole de la maturité technologique de l'apprentissage renforcé décentralisé.
INTELLECT-1 (10B, octobre 2024) a prouvé pour la première fois qu'OpenDiLoCo pouvait s'entraîner efficacement sur un réseau hétérogène traversant trois continents (communication représentant <2 %, taux d'utilisation de la puissance de calcul 98 %), brisant les limites physiques de l'entraînement interrégional.
INTELLECT-2 (32B, avril 2025), en tant que premier modèle RL sans autorisation, vérifie la capacité de convergence stable de prime-rl et GRPO+ dans des environnements asynchrones et à plusieurs étapes de retard, réalisant un RL décentralisé avec la participation ouverte de la puissance de calcul mondiale.
INTELLECT-3 (106B MoE, novembre 2025) adopte une architecture éparse n'activant que 12B de paramètres, s'entraînant sur 512×H200 pour atteindre des performances de raisonnement de pointe (AIME 90,8 %, GPQA 74,4 %, MMLU-Pro 81,9 %, etc.), affichant des performances approchant ou dépassant celles de modèles centralisés fermés de bien plus grande taille.
Prime Intellect a également construit plusieurs infrastructures de soutien : OpenDiLoCo réduit le volume de communication des entraînements interrégionaux de plusieurs centaines de fois grâce à une communication éparse dans le temps et à des différences de poids quantifiés, permettant à INTELLECT-1 de maintenir un taux d'utilisation de 98 % sur un réseau traversant trois continents ; TopLoc + Verifiers forment une couche d'exécution de confiance décentralisée, activant la vérification de l'empreinte digitale et de l'environnement pour garantir l'authenticité des données d'inférence et de récompense ; le moteur de données SYNTHETIC produit des chaînes d'inférence à grande échelle et de haute qualité, permettant au modèle de 671B de fonctionner efficacement sur des clusters de GPU de consommation grâce à un parallélisme en pipeline. Ces composants fournissent une base d'ingénierie clé pour la génération, la validation et le débit d'inférence des données dans l'IA décentralisée. La série INTELLECT prouve que cette pile technologique peut produire des modèles de classe mondiale matures, marquant le passage du système d'entraînement décentralisé de la phase conceptuelle à la phase pratique.
Gensyn : Core Stack d'apprentissage renforcé RL Swarm et SAPO
L'objectif de Gensyn est de rassembler la puissance de calcul inutilisée dans le monde pour en faire une infrastructure d'entraînement d'IA ouverte, sans confiance et évolutive à l'infini. Son noyau inclut une couche d'exécution standardisée inter-appareils, un réseau de coordination pair-à-pair et un système de validation des tâches sans confiance, et distribue automatiquement les tâches et récompenses à travers des contrats intelligents. En s'appuyant sur les caractéristiques de l'apprentissage renforcé, Gensyn introduit des mécanismes clés tels que RL Swarm, SAPO et SkipPipe, décomposant les trois étapes de génération, d'évaluation et de mise à jour, exploitant un "essaim" de GPU hétérogènes à l'échelle mondiale pour réaliser une évolution collective. Ce qu'il livre finalement n'est pas simplement de la puissance de calcul, mais de l'intelligence vérifiable (Verifiable Intelligence).
Applications d'apprentissage renforcé de la pile Gensyn

RL Swarm : moteur d'apprentissage renforcé collaboratif décentralisé
RL Swarm démontre un tout nouveau mode de coopération. Ce n'est plus simplement une distribution de tâches, mais un cycle décentralisé de "génération-évaluation-mise à jour" simulant l'apprentissage de la société humaine, en boucle infinie :
Solveurs (exécutants) : responsables de l'inférence locale des modèles et de la génération de Rollout, l'hétérogénéité des nœuds ne pose aucun problème. Gensyn intègre localement un moteur d'inférence à haut débit (comme CodeZero), capable de produire des trajectoires complètes et non seulement des réponses.
Proposants (questions) : génération dynamique de tâches (problèmes mathématiques, questions de code, etc.), soutenant la diversité des tâches et une adaptation de la difficulté de type Curriculum Learning.
Évaluateurs (évaluateurs) : utilisent des "modèles d'arbitre" congelés ou des règles pour évaluer les Rollouts locaux, générant des signaux de récompense locaux. Le processus d'évaluation peut être audité, réduisant l'espace de malveillance.
Les trois forment une structure organisationnelle P2P RL, capable de réaliser un apprentissage collaboratif à grande échelle sans planification centralisée.
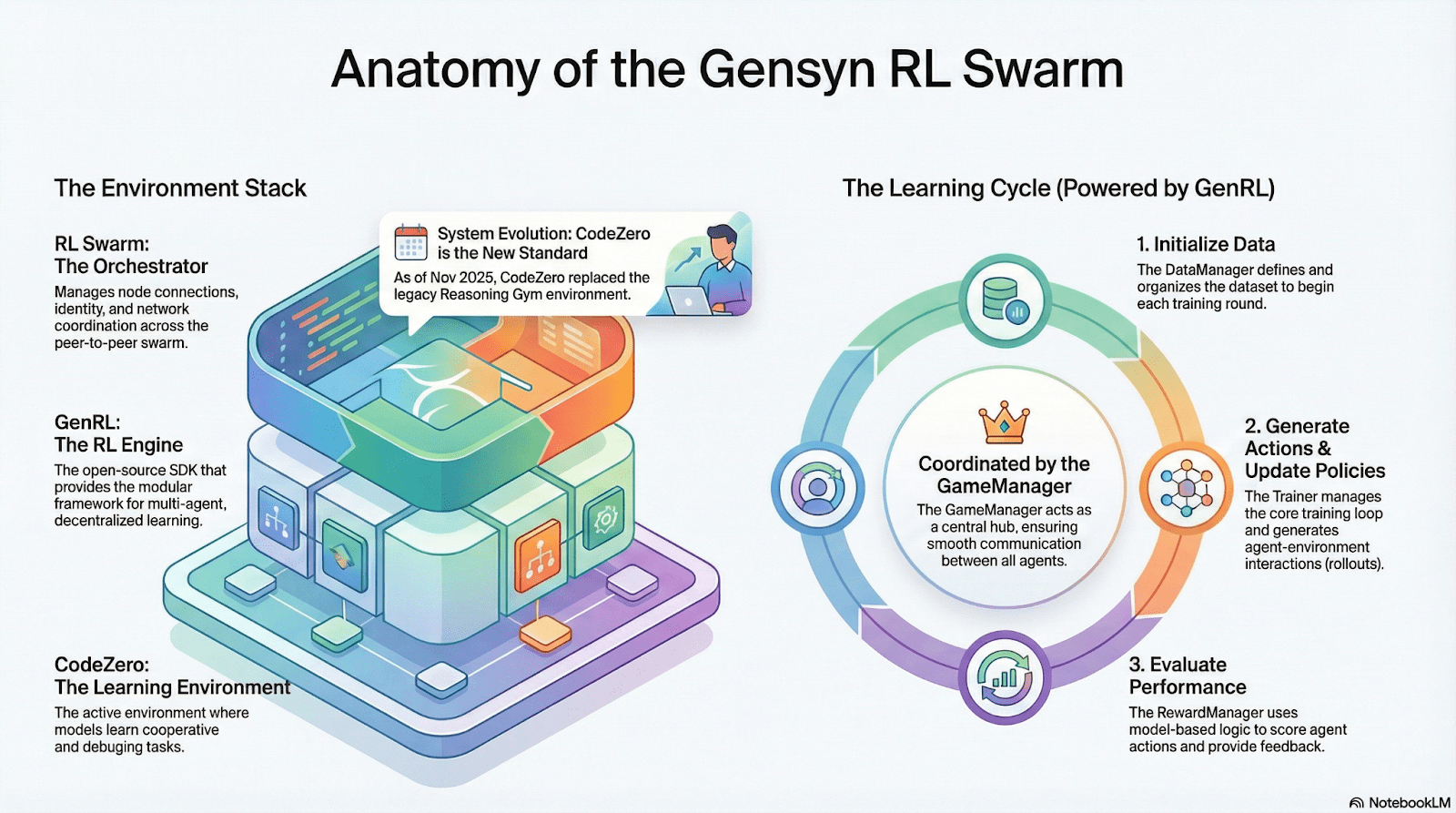
SAPO : un algorithme d'optimisation de stratégie reconstruit pour la décentralisation : SAPO (Swarm Sampling Policy Optimization) se concentre sur "le partage des Rollout et le filtrage des échantillons de signaux sans gradient, plutôt que le partage des gradients", en réalisant un échantillonnage Rollout décentralisé à grande échelle et en considérant les Rollouts reçus comme générés localement, permettant ainsi de maintenir une convergence stable dans un environnement sans coordination centrale et avec des délais de nœuds significatifs. Par rapport au PPO qui dépend d'un réseau Critique et a des coûts de calcul élevés, ou au GRPO basé sur l'estimation de l'avantage intra-groupe, SAPO permet aux GPU de consommation de participer efficacement à l'optimisation de l'apprentissage renforcé à grande échelle avec une bande passante très faible.
À travers RL Swarm et SAPO, Gensyn a prouvé que l'apprentissage renforcé (en particulier la phase de post-entraînement RLVR) s'adapte naturellement aux architectures décentralisées - car il dépend davantage d'explorations à grande échelle et diversifiées (Rollout), plutôt que de synchronisations de paramètres à haute fréquence. En combinant les systèmes de validation de PoL et Verde, Gensyn propose une voie alternative pour l'entraînement de modèles de trillions de paramètres qui ne dépend plus d'un seul géant technologique : un réseau d'intelligence super auto-évolutif composé de millions de GPU hétérogènes dans le monde.
Nous Research : Environnement d'apprentissage renforcé vérifiable Atropos
Nous Research construit une infrastructure cognitive décentralisée et auto-évolutive. Ses composants principaux - Hermes, Atropos, DisTrO, Psyche et World Sim - sont organisés en un système d'évolution intelligente en boucle fermée. Contrairement au processus linéaire traditionnel de "pré-entraînement - post-entraînement - inférence", Nous adopte des techniques d'apprentissage renforcé telles que DPO, GRPO et le rejet d'échantillons, unifiant la génération de données, la validation, l'apprentissage et l'inférence en une boucle de rétroaction continue, créant un écosystème IA en boucle fermée d'amélioration continue.
Aperçu des composants de Nous Research

Niveau du modèle : évolution de Hermes et de la capacité de raisonnement
La série Hermes est l'interface principale des modèles de Nous Research orientée utilisateur, son évolution démontre clairement le passage de l'industrie de l'alignement SFT/DPO traditionnel à l'apprentissage renforcé de raisonnement (Reasoning RL) :
Hermes 1–3 : alignement d'instructions et capacités d'agents précoces : Hermes 1–3 utilise le DPO à faible coût pour un alignement d'instructions robuste, et dans Hermes 3, s'appuie sur des données synthétiques et le mécanisme de vérification Atropos introduit pour la première fois.
Hermes 4 / DeepHermes : écrivait la pensée de type System-2 dans les poids via des chaînes de pensée, utilisant le Test-Time Scaling pour améliorer les performances mathématiques et de code, et s'appuyant sur le "rejet d'échantillons + vérification Atropos" pour construire des données d'inférence à haute pureté.
DeepHermes adopte en outre GRPO à la place de PPO, difficile à déployer de manière distribuée, permettant au RL d'inférence de fonctionner sur le réseau décentralisé GPU Psyche, établissant une base d'ingénierie pour l'évolutivité du RL d'inférence open source.
Atropos : Environnement d'apprentissage renforcé vérifiable basé sur les récompenses
Atropos est le véritable pivot du système RL de Nous. Il encapsule les invites, les appels d'outils, l'exécution de code et les interactions multiples dans un environnement RL standardisé, permettant de vérifier directement si la sortie est correcte, fournissant ainsi un signal de récompense déterministe, remplaçant l'annotation humaine coûteuse et non évolutive. Plus important encore, dans le réseau d'entraînement décentralisé Psyche, Atropos agit en tant qu'"arbitre", vérifiant si les nœuds améliorent réellement les stratégies, soutenant un Proof-of-Learning auditable, résolvant fondamentalement le problème de la fiabilité des récompenses dans l'apprentissage renforcé distribué.
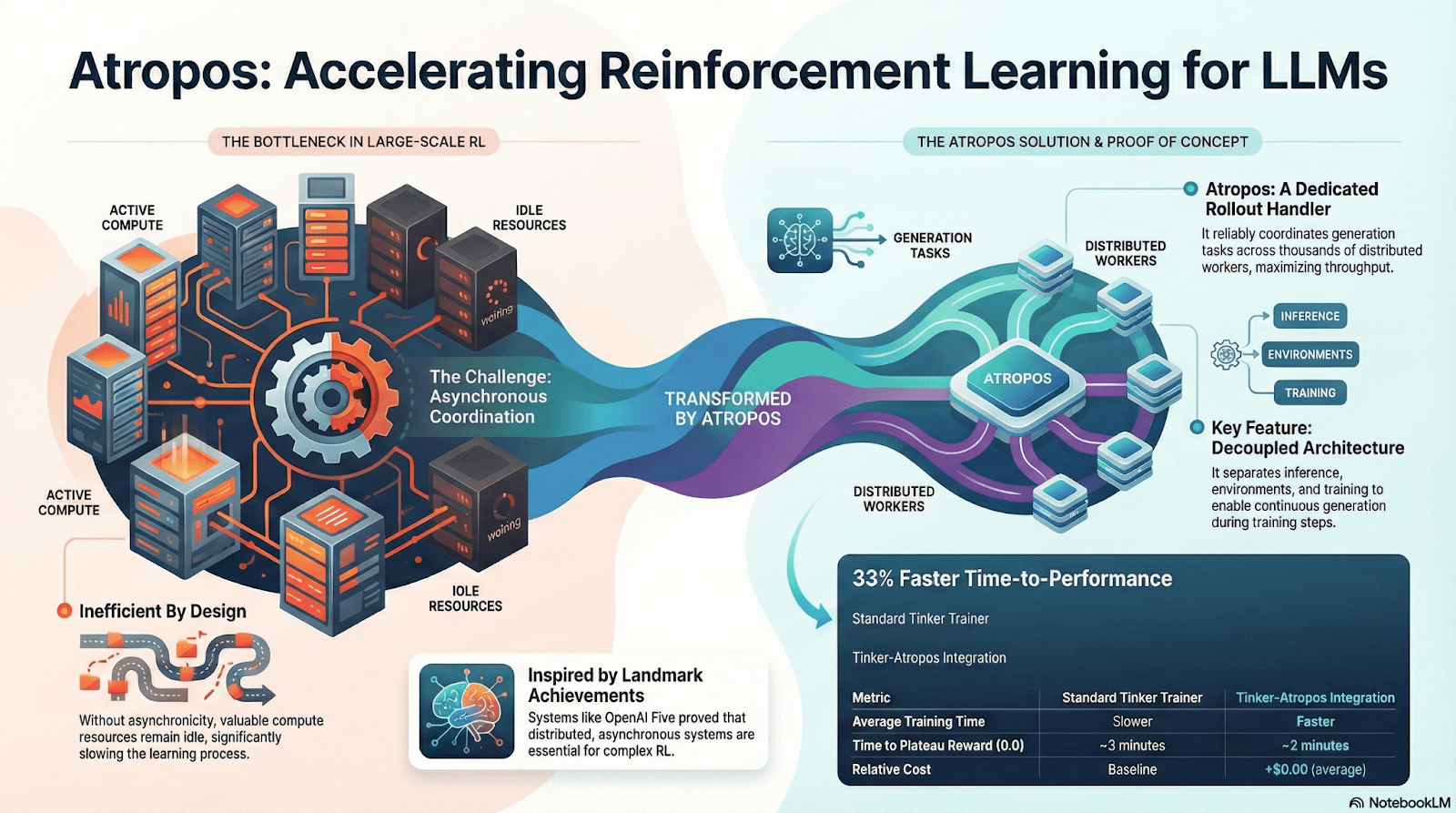
DisTrO et Psyche : couche d'optimisation de l'apprentissage renforcé décentralisé
L'entraînement traditionnel RLF (RLHF/RLAIF) dépend de grappes centralisées à haute bande passante, une barrière centrale que l'open source ne peut pas reproduire. DisTrO réduit le coût de communication du RL de plusieurs ordres de grandeur grâce à un découplage de momentum et à une compression des gradients, rendant l'entraînement réalisable sur les bandes passantes d'Internet ; Psyche déploie ce mécanisme d'entraînement sur le réseau en chaîne, permettant aux nœuds de réaliser localement l'inférence, la validation, l'évaluation des récompenses et la mise à jour des poids, formant un cycle RL complet.
Dans le système de Nous, Atropos vérifie les chaînes de pensée ; DisTrO compresse les communications d'entraînement ; Psyche exécute les boucles RL ; World Sim fournit des environnements complexes ; Forge collecte des inférences réelles ; Hermes intègre tous les apprentissages dans les poids. L'apprentissage renforcé n'est pas seulement une phase d'entraînement, mais est le protocole central du système Nous qui relie les données, l'environnement, le modèle et l'infrastructure, permettant à Hermes de devenir un système vivant capable de s'améliorer de manière continue sur un réseau de puissance de calcul open source.
Réseau de gradients : architecture d'apprentissage renforcé Echo
La vision centrale du Gradient Network est de reconstruire le paradigme de calcul de l'IA à travers une "pile de protocoles intelligents ouverts" (Open Intelligence Stack). La pile technologique de Gradient est composée d'un ensemble de protocoles centraux pouvant évoluer indépendamment tout en collaborant de manière hétérogène. Son système couvre de la communication de base à la collaboration intelligente de haut niveau, comprenant successivement : Parallax (inférence distribuée), Echo (entraînement RL décentralisé), Lattica (réseau P2P), SEDM / Massgen / Symphony / CUAHarm (mémoire, collaboration, sécurité), VeriLLM (vérification de confiance), Mirage (simulation haute-fidélité), formant ensemble une infrastructure intelligente décentralisée en évolution continue.

Echo - Architecture d'entraînement d'apprentissage renforcé
Echo est le cadre d'apprentissage renforcé de Gradient, dont le concept central repose sur le découplage des chemins d'entraînement, d'inférence et de données (récompenses) dans l'apprentissage renforcé, permettant à la génération de Rollout, à l'optimisation des stratégies et à l'évaluation des récompenses de se développer et de s'organiser indépendamment dans un environnement hétérogène. Il fonctionne en synergie dans un réseau hétérogène composé de nœuds de côté inférence et côté entraînement, maintenant la stabilité de l'entraînement dans des environnements hétérogènes étendus grâce à des mécanismes de synchronisation légers, atténuant efficacement les défaillances de SPMD et les goulets d'étranglement de l'utilisation des GPU causés par le mélange des inférences et des entraînements dans le RLHF traditionnel DeepSpeed / VERL.
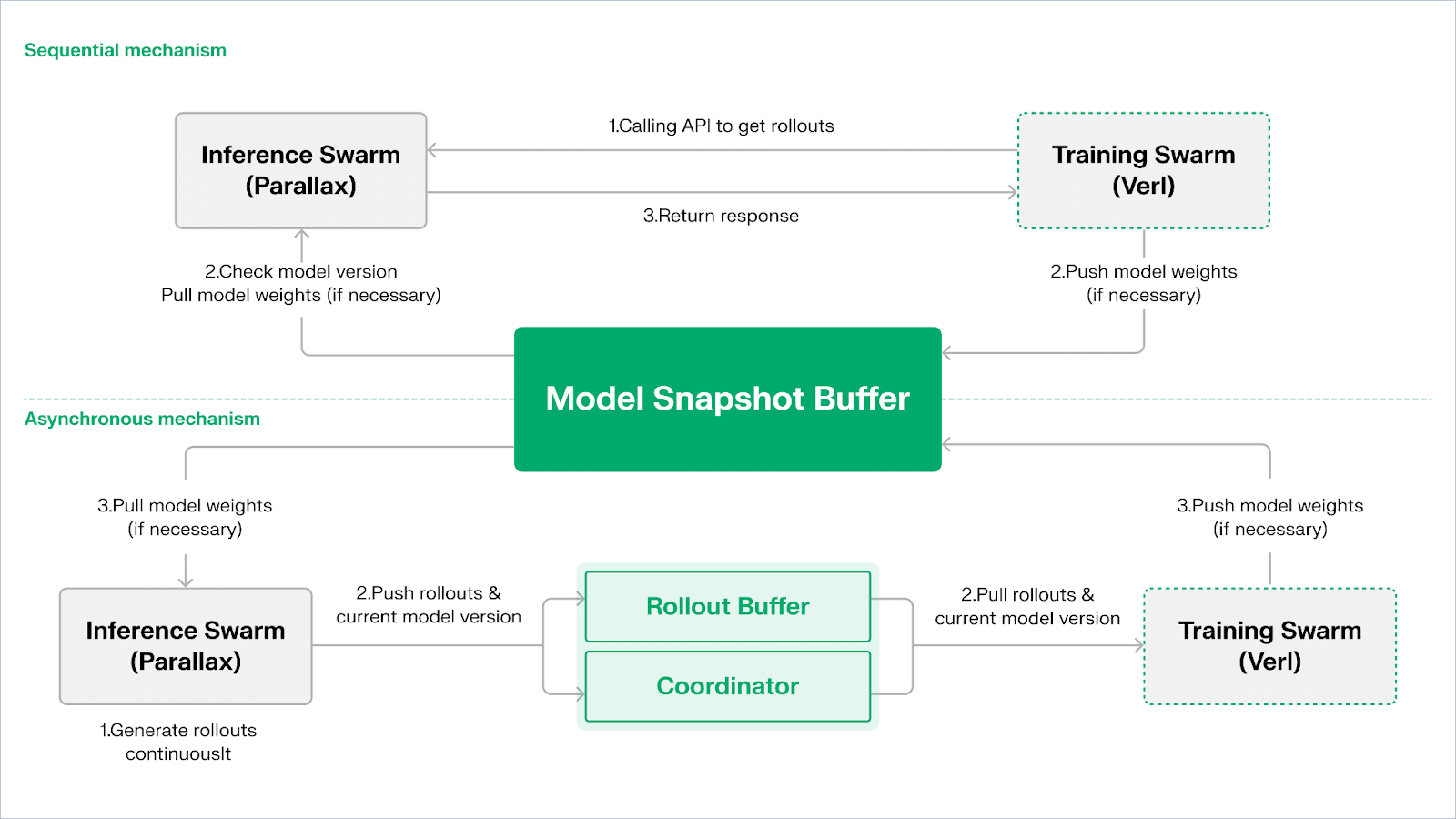
Echo adopte une architecture à double groupe d'inférence-formation pour maximiser l'utilisation de la puissance de calcul, les deux groupes fonctionnant de manière indépendante, sans se bloquer mutuellement :
Maximiser le débit d'échantillonnage : le groupe d'inférence Inference Swarm est composé de GPU de consommation et d'appareils en périphérie, construisant un échantillonneur à haut débit via Parallax en pipeline-parallèle, axé sur la génération de trajectoires ;
Maximiser la puissance de calcul des gradients : le groupe d'entraînement Training Swarm est un réseau de GPU de consommation capable de fonctionner sur des clusters centralisés ou à l'échelle mondiale, responsable de la mise à jour des gradients, de la synchronisation des paramètres et du réglage LoRA, axé sur le processus d'apprentissage.
Pour maintenir la cohérence entre les stratégies et les données, Echo propose deux types de protocoles légers de synchronisation : séquentiel (Sequential) et asynchrone (Asynchronous), réalisant une gestion bidirectionnelle de la cohérence des poids de stratégie et des trajectoires :
Mode de tirage séquentiel (Pull) | Priorité à la précision : du côté de l'entraînement, avant de tirer de nouvelles trajectoires, les nœuds d'inférence forcent le rafraîchissement de la version du modèle, garantissant ainsi la fraîcheur des trajectoires, adapté aux tâches hautement sensibles à l'obsolescence des stratégies ;
Mode de tirage asynchrone (Push–Pull) | Priorité à l'efficacité : du côté de l'inférence, les trajectoires avec étiquettes de version sont continuellement générées, le côté de l'entraînement consomme à son propre rythme, le coordinateur surveille l'écart de version et déclenche le rafraîchissement des poids, maximisant l'utilisation des appareils.
Au niveau sous-jacent, Echo est construit sur Parallax (inférence hétérogène dans des environnements à faible bande passante) et des composants d'entraînement distribués légers (comme VERL), s'appuyant sur LoRA pour réduire les coûts de synchronisation entre nœuds, permettant à l'apprentissage renforcé de fonctionner de manière stable sur des réseaux hétérogènes à l'échelle mondiale.
Grail : apprentissage renforcé de l'écosystème Bittensor
Bittensor, grâce à son mécanisme de consensus unique Yuma, a construit un réseau immense, éparse et non stationnaire de fonctions de récompense.
Covenant AI dans l'écosystème Bittensor construit une chaîne verticale intégrée de pré-entraînement à RL post-entraînement via SN3 Templar, SN39 Basilica et SN81 Grail. Parmi eux, SN3 Templar est responsable du pré-entraînement des modèles de base, SN39 Basilica fournit un marché de puissance de calcul décentralisé, et SN81 Grail sert de "couche d'inférence vérifiable" pour le RL post-entraînement, portant le processus central du RLHF / RLAIF et complétant l'optimisation en boucle fermée des stratégies alignées à partir des modèles de base.

L'objectif de GRAIL est de prouver de manière cryptographique la véracité de chaque rollout d'apprentissage renforcé et le lien d'identité du modèle, garantissant que le RLHF peut être exécuté en toute sécurité dans des environnements sans confiance. Le protocole établit une chaîne de confiance par le biais de trois mécanismes :
Génération de défis déterministes : utilisant des signaux aléatoires de drand et des hachages de blocs pour produire des tâches de défi imprévisibles mais reproductibles (comme SAT, GSM8K), éliminant ainsi la tricherie par pré-calcul ;
À travers l'échantillonnage par index PRF et les engagements sketch, les validateurs peuvent à faible coût échantillonner les probabilités de log au niveau des tokens et les chaînes d'inférence, confirmant que le rollout a bien été généré par le modèle déclaré.
Liage d'identité du modèle : lier le processus d'inférence à la signature structurelle des empreintes de poids de modèle et la distribution des tokens, garantissant que le remplacement du modèle ou la relecture des résultats seront immédiatement identifiés. Cela fournit ainsi une base de véracité pour les trajectoires d'inférence (rollout) dans le RL.
Sur cette base, le sous-réseau Grail a mis en œuvre un processus de post-entraînement vérifiable de style GRPO : les mineurs génèrent plusieurs chemins d'inférence pour le même problème, les validateurs notent la précision, la qualité des chaînes d'inférence et la satisfaction des SAT, et écrivent les résultats normalisés sur la chaîne, en tant que poids TAO. Des expériences publiques montrent que ce cadre a déjà amélioré le taux de précision MATH de Qwen2.5-1.5B de 12,7 % à 47,6 %, prouvant qu'il peut prévenir la tricherie et renforcer significativement les capacités du modèle. Dans la pile d'entraînement de Covenant AI, Grail est la pierre angulaire de la confiance et de l'exécution de l'apprentissage renforcé décentralisé RLVR/RLAIF, n'ayant pas encore été officiellement lancé sur le réseau principal.
Fraction AI : apprentissage renforcé basé sur la compétition RLFC
L'architecture de Fraction AI est clairement centrée sur l'apprentissage renforcé de compétition (Reinforcement Learning from Competition, RLFC) et l'annotation de données gamifiée, remplaçant les récompenses statiques de RLHF traditionnel et l'annotation humaine par un environnement de compétition ouvert et dynamique. Les agents s'opposent dans différents Spaces, leur classement relatif et les évaluations des juges AI constituent ensemble des récompenses en temps réel, transformant le processus d'alignement en un système de jeu multi-agents en ligne continu.
Différences fondamentales entre RLHF traditionnel et RLFC de Fraction AI :

La valeur fondamentale du RLFC réside dans le fait que les récompenses ne proviennent plus d'un seul modèle, mais d'adversaires et d'évaluateurs en constante évolution, évitant ainsi l'exploitation des modèles de récompense et empêchant l'écosystème de tomber dans des optima locaux grâce à la diversité des stratégies. La structure des Spaces détermine la nature du jeu (à somme nulle ou à somme positive), stimulant l'émergence de comportements complexes dans l'adversité et la coopération.
Au niveau de l'architecture système, Fraction AI décompose le processus d'entraînement en quatre composants clés :
Agents : unités stratégiques légères basées sur des LLM open source, s'étendant par QLoRA avec des poids différentiels, mises à jour à faible coût ;
Spaces : environnements de domaine de tâche isolés, où les agents paient pour entrer et reçoivent des récompenses selon leurs performances ;
Juges AI : couche de récompense instantanée construite avec RLAIF, offrant une évaluation décentralisée et évolutive ;
Proof-of-Learning : lie les mises à jour de stratégie à des résultats compétitifs spécifiques, garantissant que le processus d'entraînement est vérifiable et anti-tricherie.
L'essence de Fraction AI est de construire un moteur d'évolution collaboratif homme-machine. Les utilisateurs agissent en tant que "méta-optimisateurs" (Meta-optimizer) au niveau stratégique, guidant la direction d'exploration à travers l'ingénierie des invites (Prompt Engineering) et la configuration des hyperparamètres ; tandis que les agents génèrent automatiquement d'énormes quantités de données de préférences de haute qualité (Preference Pairs) dans une compétition microscopique. Ce modèle permet à l'annotation des données d'atteindre un cycle commercial grâce à un "réglage sans confiance" (Trustless Fine-tuning).
Comparaison des architectures de projets d'apprentissage renforcé Web3

V. Résumé et perspectives : chemins et opportunités de l'apprentissage renforcé × Web3
Sur la base de l'analyse déconstructive des projets de pointe mentionnés ci-dessus, nous avons observé que, bien que les points d'entrée (algorithmes, ingénierie ou marché) des différentes équipes soient variés, l'architecture sous-jacente converge vers un paradigme hautement cohérent de "découplage-validation-incitation" lorsque l'apprentissage renforcé (RL) est combiné avec Web3. Cela n'est pas seulement une coïncidence technique, mais aussi le résultat inévitable de l'adaptation des propriétés uniques de l'apprentissage renforcé aux réseaux décentralisés.
Caractéristiques de l'architecture générale de l'apprentissage renforcé : résoudre les limites physiques et de confiance fondamentales
Découplage de la physique d'entraînement (Decoupling of Rollouts & Learning) - Topologie de calcul par défaut
Communications éparses et parallèles des Rollouts externalisées aux GPU de consommation mondiale, les mises à jour de paramètres à haute bande passante centralisées se concentrent sur un nombre limité de nœuds d'entraînement, allant de l'Actor–Learner asynchrone de Prime Intellect à l'architecture en double groupe de Gradient.
Couche de confiance vérifiable (Verification-Driven Trust) - Infrastructure
Dans un réseau sans permission, l'authenticité du calcul doit être contrainte par des conceptions mathématiques et mécaniques, représentant des réalisations telles que PoL de Gensyn, TOPLOC de Prime Intellect et la vérification cryptographique de Grail.
Boucle d'incitation tokenisée (Tokenized Incentive Loop) - Auto-régulation du marché
L'approvisionnement en puissance de calcul, la génération de données, l'évaluation des classements et la distribution des récompenses forment une boucle fermée, incitant à la participation par le biais de récompenses, tout en inhibant la tricherie via le Slash, permettant au réseau de maintenir sa stabilité et son évolution continue dans un environnement ouvert.
Chemin technologique différencié : différents "points de rupture" sous une architecture cohérente
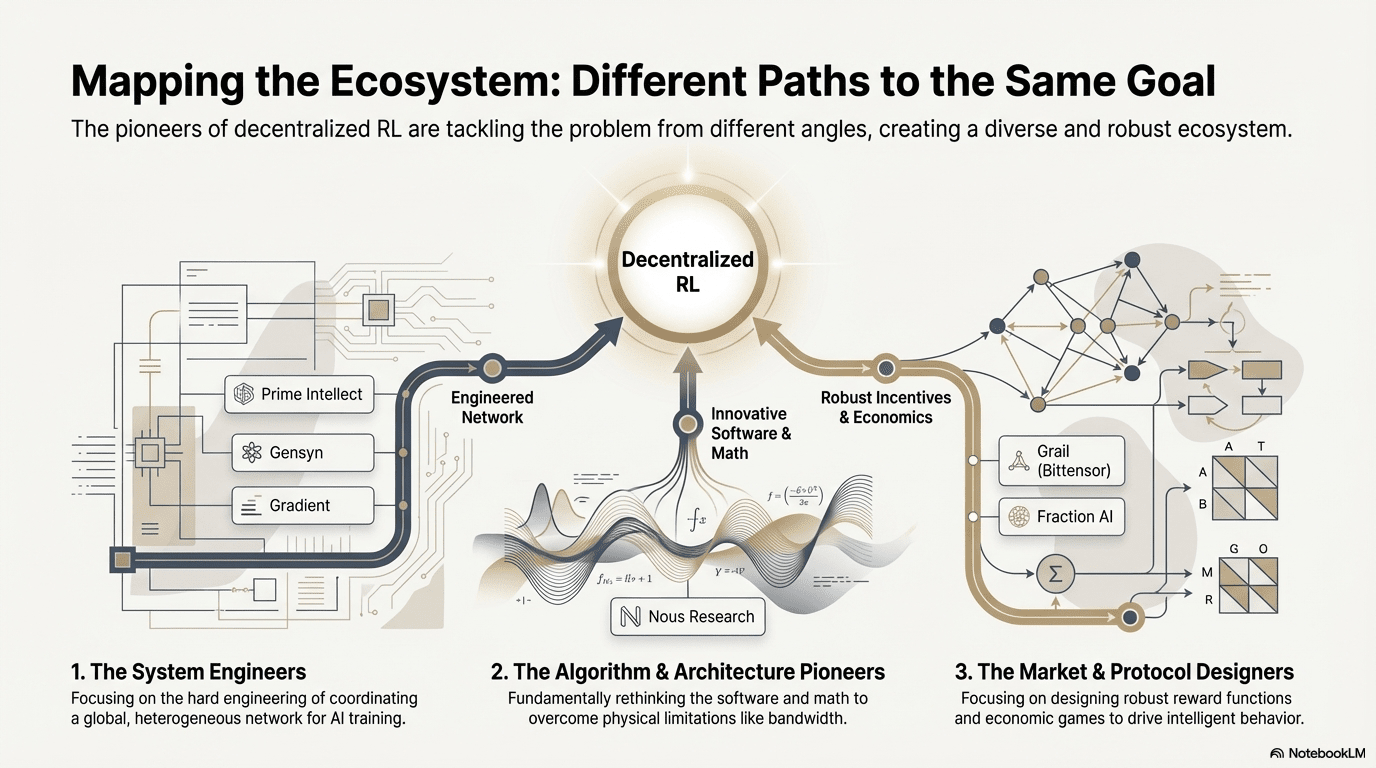
Bien que les architectures se rapprochent, chaque projet sélectionne des fossés technologiques différents en fonction de son propre ADN :
École des percées algorithmiques (Nous Research) : cherche à résoudre les contradictions fondamentales de l'entraînement distribué (goulots d'étranglement de bande passante) à partir des bases mathématiques. Son optimiseur DisTrO vise à réduire le volume de communication des gradients de milliers de fois, avec l'objectif de permettre aux connexions Internet domestiques d'exécuter des entraînements de grands modèles, un "écrasement dimensionnel" des limites physiques.
École d'ingénierie système (Prime Intellect, Gensyn, Gradient) : met l'accent sur la construction des "systèmes d'exécution IA" de prochaine génération. ShardCast de Prime Intellect et Parallax de Gradient visent tous deux à maximiser l'efficacité des grappes hétérogènes dans les conditions réseau existantes par des moyens d'ingénierie extrêmes.
École de la stratégie de marché (Bittensor, Fraction AI) : se concentre sur la conception des fonctions de récompense (Reward Function). En concevant des mécanismes de notation astucieux, elle incite les mineurs à rechercher des stratégies optimales, accélérant ainsi l'émergence de l'intelligence.
Avantages, défis et perspectives finales
Dans le paradigme de la combinaison de l'apprentissage renforcé et de Web3, les avantages au niveau système se manifestent d'abord dans la restructuration des structures de coûts et de gouvernance.
Restructuration des coûts : la demande de Rollout dans l'apprentissage renforcé post-entraînement (Post-training) est infinie ; Web3 peut mobiliser la puissance de calcul mondiale à long terme à un coût extrêmement bas, ce qui est un avantage de coût que les fournisseurs de cloud centralisés peinent à égaler.
Alignement souverain (Sovereign Alignment) : briser le monopole des grandes entreprises sur les valeurs de l'IA (Alignment), permettant à la communauté de décider ce qui constitue une "bonne réponse" par vote des jetons, réalisant ainsi la démocratisation de la gouvernance de l'IA.
Parallèlement, ce système fait face à deux contraintes structurelles majeures.
Mur de bande passante (Bandwidth Wall) : Malgré des innovations comme DisTrO, la latence physique limite toujours l'entraînement complet des modèles à très grande échelle (70B+), rendant actuellement l'IA Web3 davantage limitée à l'ajustement et à l'inférence.
Loi de Goodhart (Reward Hacking) : Dans un réseau à forte incitation, il est très facile pour les mineurs de "surcharger" les règles de récompense (gagner des points) plutôt que d'améliorer l'intelligence réelle. Concevoir une fonction de récompense robuste contre la tricherie est un jeu éternel.
Attaque par nœuds malveillants de type Byzantin (BYZANTINE worker) : en manipulant activement les signaux d'entraînement et en empoisonnant, cela détruit la convergence du modèle. Le cœur du problème ne réside pas dans la conception continue de fonctions de récompense anti-tricherie, mais dans la construction de mécanismes dotés de robustesse contre les attaques.
La combinaison de l'apprentissage renforcé avec Web3 réécrit essentiellement les mécanismes de "comment l'intelligence est produite, alignée et valorisée". Son chemin d'évolution peut être résumé en trois directions complémentaires :
Réseau d'entraînement et d'inférence décentralisé : des machines de minage de puissance de calcul aux réseaux de stratégie, externalisant les Rollout parallèles et vérifiables à des GPU de longue traîne mondiaux, se concentrant à court terme sur le marché d'inférence vérifiable, évoluant à moyen terme en sous-réseaux d'apprentissage renforcé regroupés par tâche ;
Capitalisation des préférences et des récompenses : de la main-d'œuvre d'annotation aux droits de données. Réalisant la capitalisation des préférences et des récompenses, transformant les retours de haute qualité et le modèle de récompense en actifs de données gouvernables et répartissables, passant de "la main-d'œuvre d'annotation" à "des droits de données".
Évolution "petite mais belle" dans des domaines verticaux : cultivant des agents RL spécialisés puissants dans des scénarios verticaux avec des résultats vérifiables et des revenus quantifiables, tels que l'exécution de stratégies DeFi et la génération de code, liant directement l'amélioration des stratégies et la capture de valeur, avec l'espoir de surpasser les modèles fermés généraux.
Dans l'ensemble, la véritable opportunité de l'apprentissage renforcé × Web3 ne réside pas dans la reproduction d'une version décentralisée d'OpenAI, mais dans la réécriture des "relations de production intelligentes" : permettre à l'exécution d'entraînement de devenir un marché de puissance de calcul ouvert, faire des récompenses et des préférences des actifs sur chaîne gouvernables, et redistribuer la valeur apportée par l'intelligence entre les formateurs, les alignateurs et les utilisateurs.
Avertissement : Cet article a été assisté par les outils IA ChatGPT-5 et Gemini 3 au cours de sa rédaction. L'auteur a fait de son mieux pour vérifier et s'assurer que les informations sont réelles et précises, mais des omissions peuvent encore exister, merci de votre compréhension. Il est particulièrement important de noter que le marché des actifs cryptographiques présente généralement des divergences entre les fondamentaux des projets et les performances de prix sur le marché secondaire. Le contenu de cet article est uniquement destiné à l'intégration d'informations et à des échanges académiques/recherche, et ne constitue pas un conseil en investissement, ni ne doit être considéré comme une recommandation d'achat ou de vente de tout jeton.