It wasn’t down.
It wasn’t working.
It was just unclear.
That “unclear” zone is where most storage pain lives. Not in dramatic outages, not in loud failures, but in those long nights where everything looks mostly normal and nothing is truly reliable. A file seems reachable. A retriever reports success. An indexer claims the data is present. And yet the user experience says otherwise.
This is the worst kind of failure because it refuses to be measured cleanly. When something is fully down, people react fast. Alerts fire. Incidents are declared. Everyone knows what needs to happen next. But when a system stays half-right, teams lose hours chasing shadows. You’re not fixing one broken part. You’re trying to prove what is real.
Most modern apps depend on multiple moving pieces. Storage is one layer. Retrieval is another. Indexing and caching sit on top. In a distributed world, those layers drift apart over time. One component updates quickly, another lags behind, and the result is ambiguity. The data might exist, but the path to it is no longer consistent.
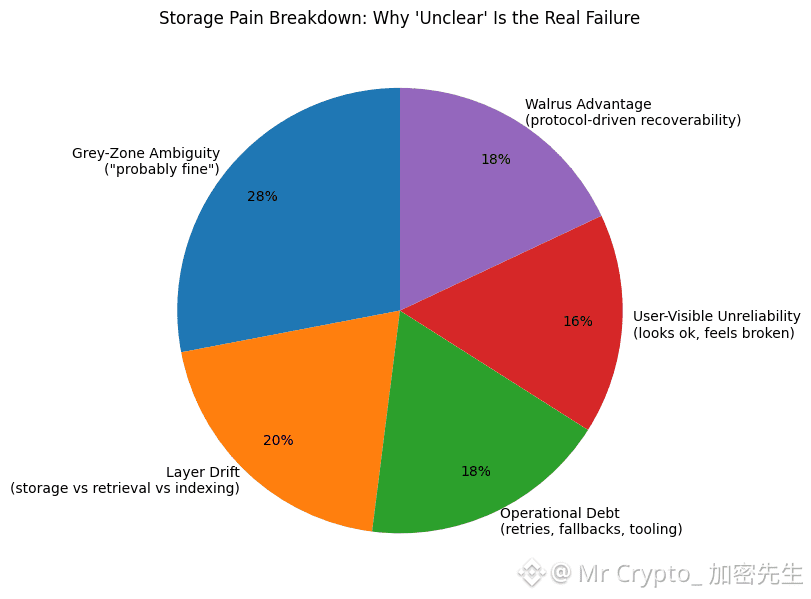
That kind of ambiguity turns into operational debt. Engineers stop trusting signals. They add retries, fallbacks, and background checks. They write tools that compare one source of truth against another. Over time the workflow becomes defensive. You stop building for clean execution and start building for survival.
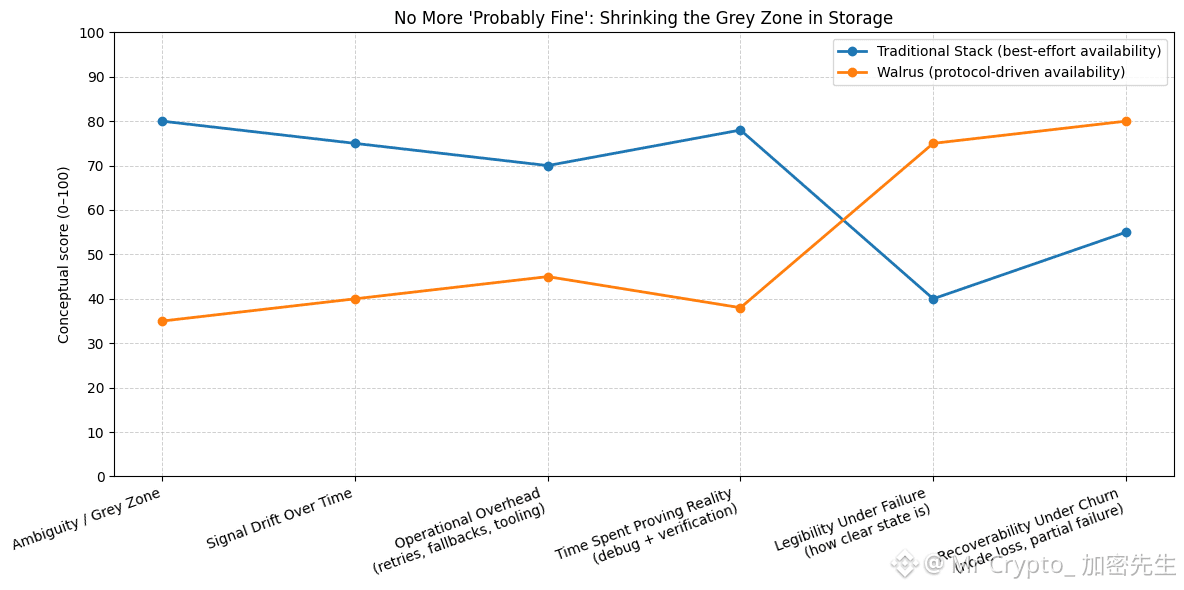
Walrus is designed to shrink that grey zone. The promise is not only that data is stored across many nodes. The deeper promise is that availability becomes a protocol decision, not an interpretation made after the fact.
In systems where availability is “best effort,” you can end up with conflicting stories. The retriever thinks a blob is available. The indexer marks it as present. But the network has changed underneath them and the state is no longer stable. Now you are stuck asking: when did it stop being true, and who should have noticed?
Walrus pushes toward a cleaner answer. Availability is coordinated at the network level, and the system is built to keep data recoverable even when nodes fail. That means the protocol is responsible for carrying state forward, not individual services trying to guess what happened.
This matters because storage should not require constant interpretation. The moment a team needs to “read between the lines,” reliability is already lost. A system that forces humans to interpret the health of data is a system that ages badly.
When ambiguity is removed at the storage layer, teams stop building workflows around excuses. They stop writing special cases for “probably fine.” They stop managing a long list of strange edge conditions. Instead, they can treat storage like a dependable primitive, the same way a serious business expects power, networking, or accounting to behave.
The quiet value of Walrus is that it does not just reduce downtime. It reduces drift. Drift is what turns stable systems into fragile ones over months and years. It is what creates slow degradation, where everything keeps “working” until it suddenly doesn’t.
That is why the difference matters. Reliability is a metric. Removing ambiguity is a design choice. And when you make that choice at the storage layer, the whole stack becomes calmer. Not because nothing ever goes wrong, but because when something changes, the system stays legible. That is how infrastructure grows older without falling apart.

