The encoding protocol achieves the objective of a low overhead factor with very high assurance, but is still not suitable for a long-lasting deployment. The main challenge is that in a long-running large-scale system, storage nodes routinely experience faults, lose their slivers, and have to be replaced. Additionally, in a permissionless system, there is some natural churn of storage nodes even when they are well incentivized to participate.
Both of these cases would result in enormous amounts of data being transferred over the network, equal to the total size of data being stored in order to recover the slivers for new storage nodes. This is prohibitively expensive. We would instead want the system to be self-healing such that the cost of recovery under churn is proportional only to the data that needs to be recovered, and scale inversely with n.
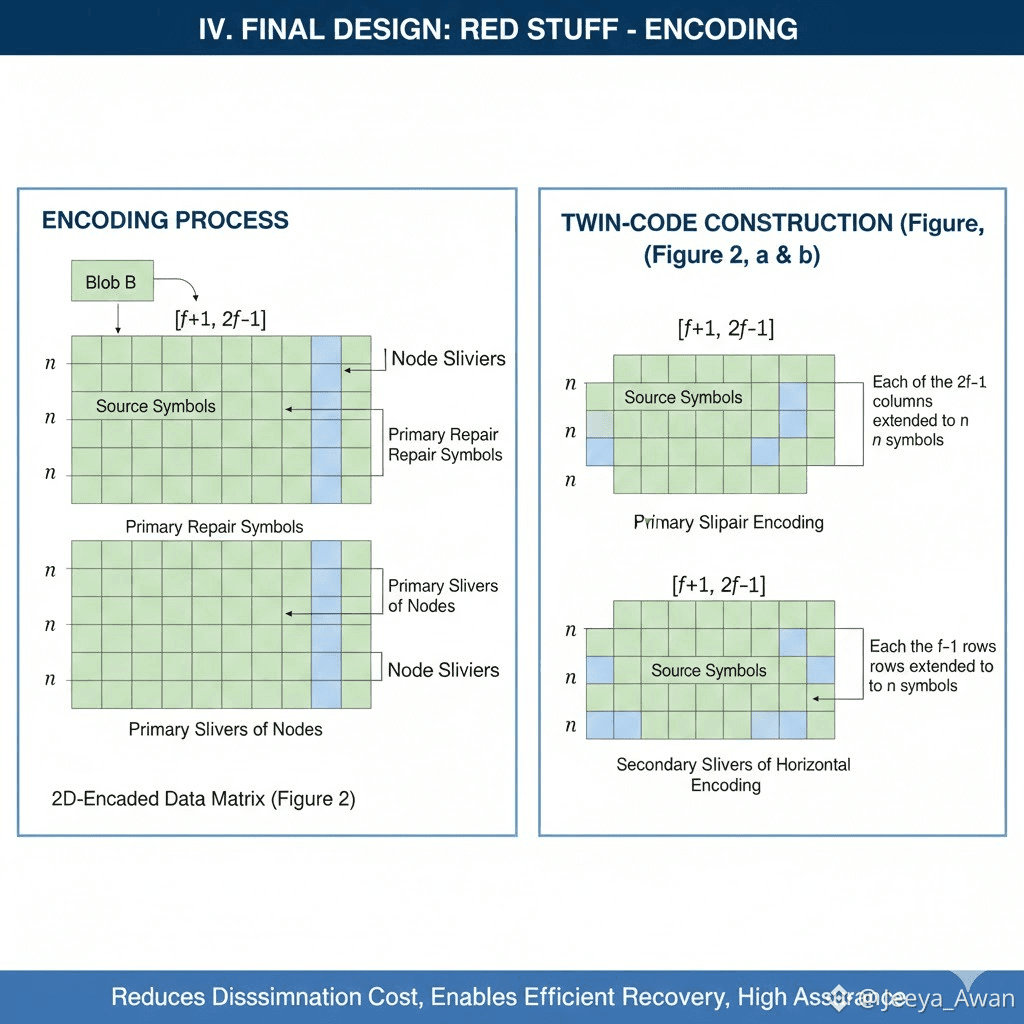
To achieve this, Red Stuff encodes blobs in two dimensions (2D-encoding). The primary dimension is equivalent to the RS-encoding used in prior systems. However, in order to allow efficient recovery of slivers of B we also encode on a secondary dimension. Red Stuff is based on linear erasure coding and the Twin-code framework, which provides erasure coded storage with efficient recovery in a crash-tolerant setting with trusted writers. Walrus adapt this framework to make it suitable in the byzantine fault tolerant setting with a single set of storage nodes.
• Encoding:
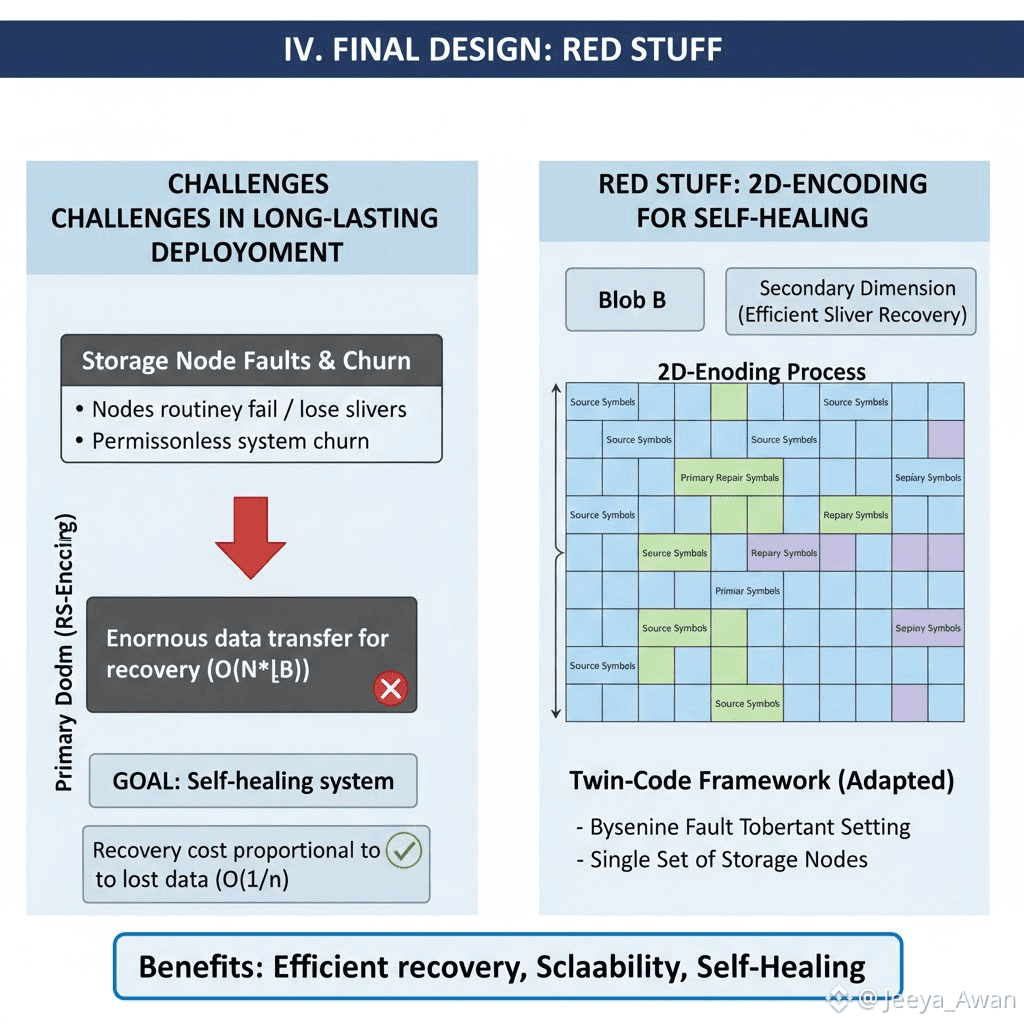
Our starting point is the second strawman design that splits the blobs into f+1 slivers. Instead of simply encoding repair slivers, we first add one more dimension to the splitting process: the original blob is split into f+1 primary slivers (vertical in the figure) into 2f+1 secondary slivers (horizontal in figure). As a result, the file is now split into (f+1)(2f+1) symbols that can be visualized in an [f+1,2f+1] matrix.
Given this matrix we then generate repair symbols in both dimensions. We take each of the 2f+1 columns (of size f+1) and extend them to n symbols such that there are n rows. We assign each of the rows as the primary sliver of a node (Figure 2(a)). This almost triples the total amount of data we need to send and is very close to what 1D encoding did in the protocol in Section III-B. In order to provide efficient recovery for each sliver, we also take the initial [f+1,2f+1] 6 matrix and extend with repair symbols each of the f+1 rows (of size 2f+1) and extend them to n symbols (Figure 2(b)) using our encoding scheme. This creates n columns, which we assign as the secondary sliver of each node, respectively.
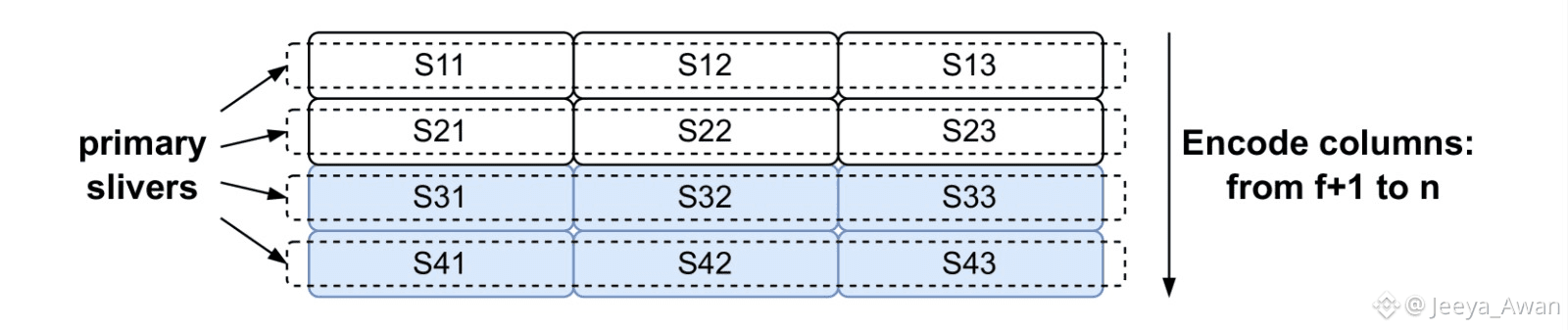
Figure: Primary Encoding in two dimensions. The file is split into 2f+1 columns and f+1 rows. Each column is encoded as a separate blob with 2f repair symbols. Then each extended row is the primary sliver of the respective node.
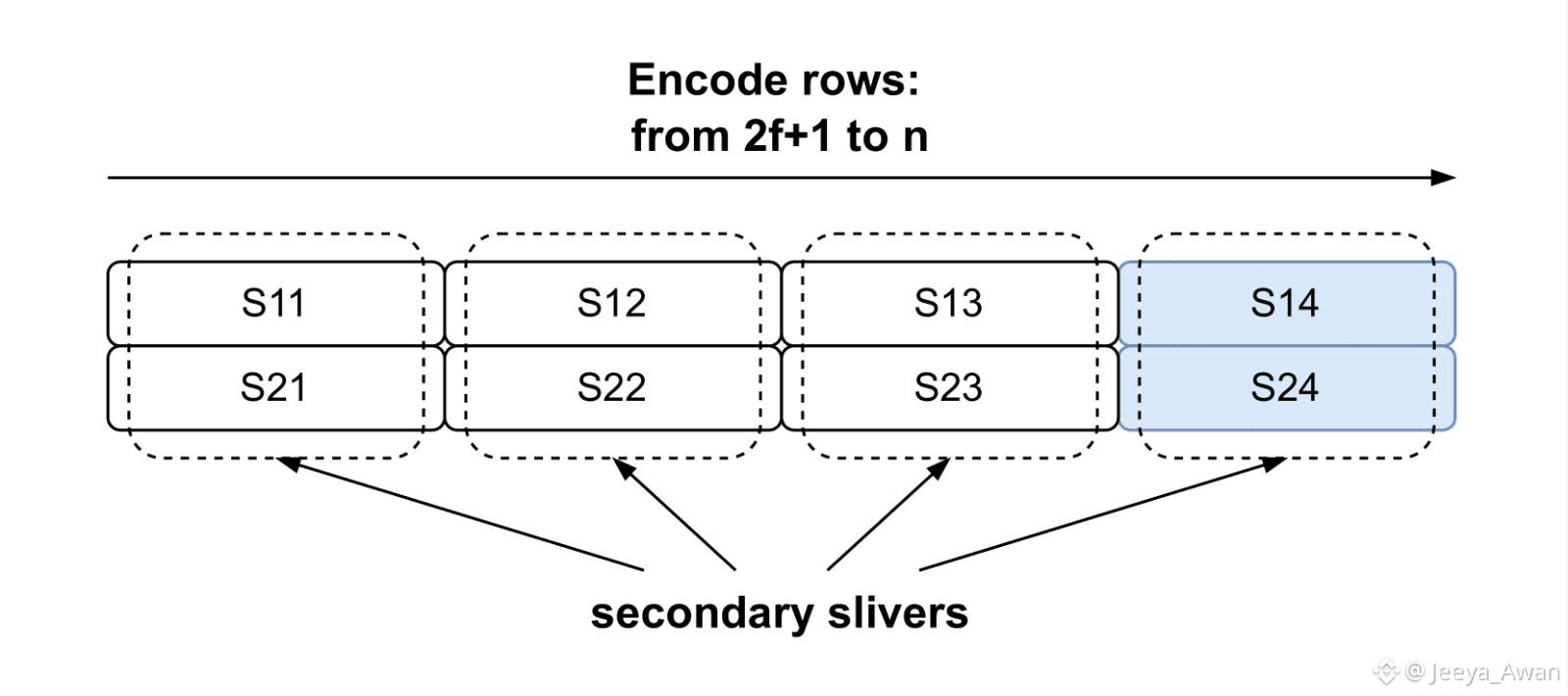
Figure: Secondary Encoding in two dimensions. The file is split into 2f+1 columns and f+1 rows. Each row is encoded as a separate blob with f repair symbols. Then each extended columns is the secondary sliver of the respective node.
• Write protocol:
The Write protocol of Red Stuff uses the same pattern as the RS-code protocol. The writer W first encodes the blobs and creates a sliver pair for each node. A sliver pair i is the pair of ith primary and secondary slivers. There are n=3f+1 sliver pairs, as many as nodes. Then, W sends the sliver commitments to every node, along with the respective sliver pair. The nodes check their own sliver pair against the commitments, recompute the blob commitment, and reply with a signed acknowledgment. When 2f+1 signatures are collected, W generates a certificate and posts it on-chain to certify the blob’s availability. In theoretical asynchronous network models with reliable delivery the above would result in all correct nodes eventually receiving a sliver pair from an honest writer. However, in practical protocols the writer needs to stop re-transmitting. It is safe to stop the re-transmission after 2f+1 signatures are collected, leading to at least f+1 correct nodes (out of the 2f+1 that responded) holding a sliver pair for the blob.
• Handling Metadata:
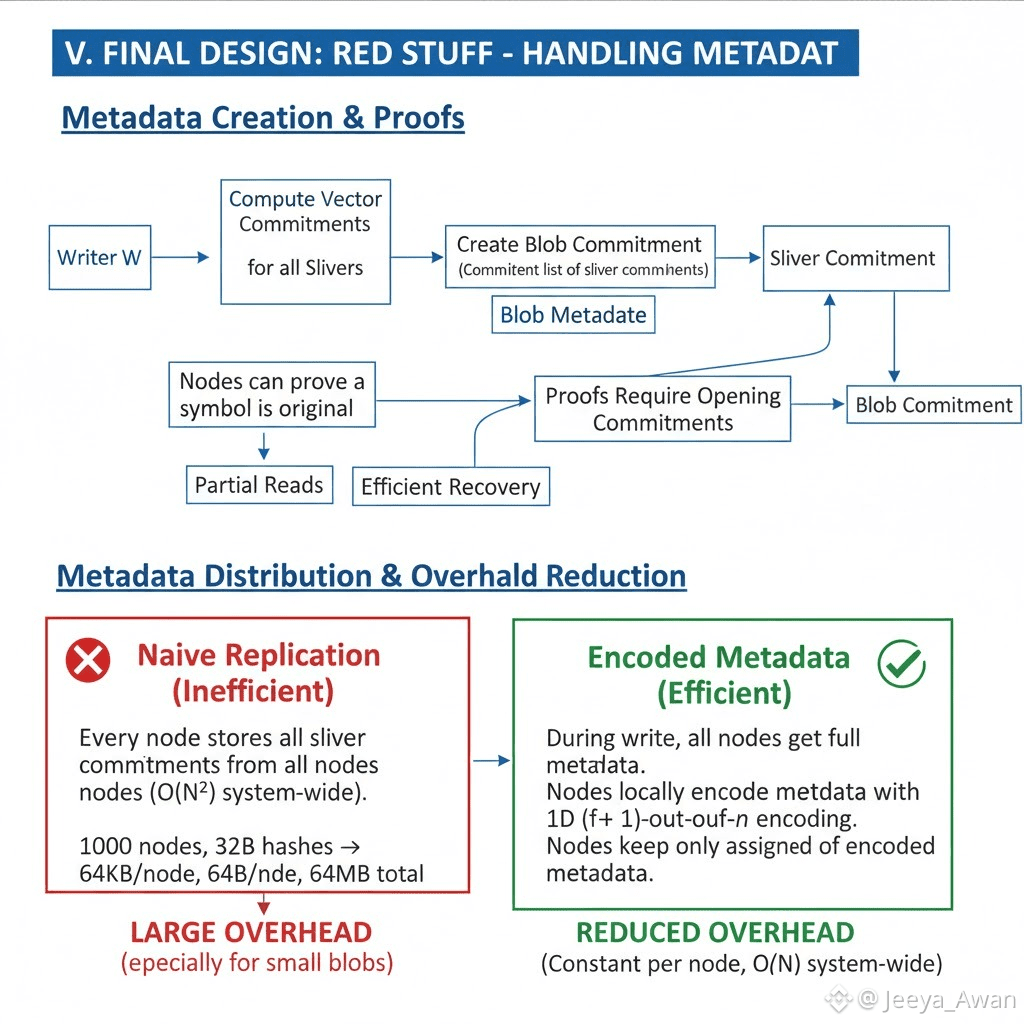
During the write protocol W computes vector commitments of all slivers and as a last step creates a commitment over the list of these sliver commitments, which serves as a blob commitment. These commitments for each sliver form the blob metadata. Using these, nodes can later, when queried for a single symbol, prove that the symbol they return is the symbol originally written. This allows for partial reads of data when the systematic symbols are available as well as for efficient recovery. However, these proofs require the opening of the commitments for the respective sliver as well as of the blob commitment w.r.t. the respective sliver commitment. A node that holds all of their slivers can easily recompute the sliver commitment and its openings, but to open the blob commitment, all sliver commitments from all nodes are required. If we naively replicate this metadata to every single storage node to enable secure self-healing, we create a large overhead that is quadratic in the number of nodes, since each node needs to store the sliver commitments of all nodes. Especially for small blobs, this can make a large difference in the relative overhead. For example, using 32B hashes in a system of 1000 nodes would require storing an additional 64kB on each node, or 64MB in total.
To reduce the overhead, storage nodes maintain an encoded version of the metadata. Since all storage nodes need to get the metadata in full when the write is in progress, there is no need for the client to perform the encoding or to do a 2D encoding. Instead, storage nodes can simply locally encode the metadata with an 1D (f+1)-out-of-n encoding and keep the shard assigned to them7. This reduces the overhead to a constant per node, i.e., from quadratic to linear system-wide overhead.
• Read Protocol:
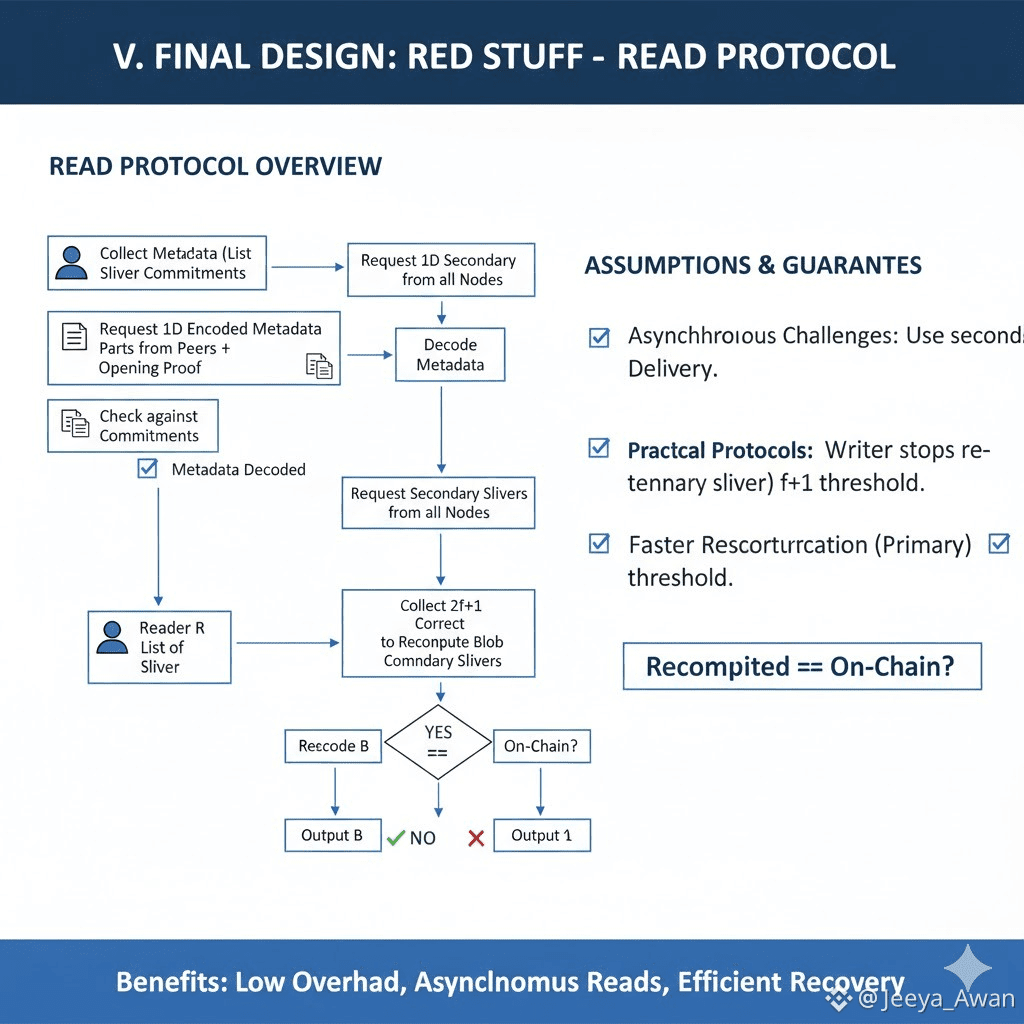
The Read protocol is the same as for RS-codes. In order to allow for asychronous challenges, nodes only use their secondary sliver. If this is not necessary, we can use the primary sliver and have a faster reconstruction threshold of f+1.
The Read process starts with R collecting the metadata, i.e., the list of sliver commitments for the blob commitment. To do so, R requests the 1D encoded metadata parts from its peers along with the opening proofs. After the metadata is decoded, R checks that the returned set corresponds to the blob commitment. Then R
requests a read for the blob commitment from all nodes and they respond with the secondary sliver they hold (this may happen gradually to save bandwidth). Each response is checked against the corresponding commitments in the commitment set for the blob. When 2f+1 correct secondary slivers are collected R decodes B and then re-encodes it to recompute the blob commitment and check that it matches the blob commitment. If it is the same with the one W posted on chain then R outputs B, otherwise it outputs ⊥.
• Sliver Healing:
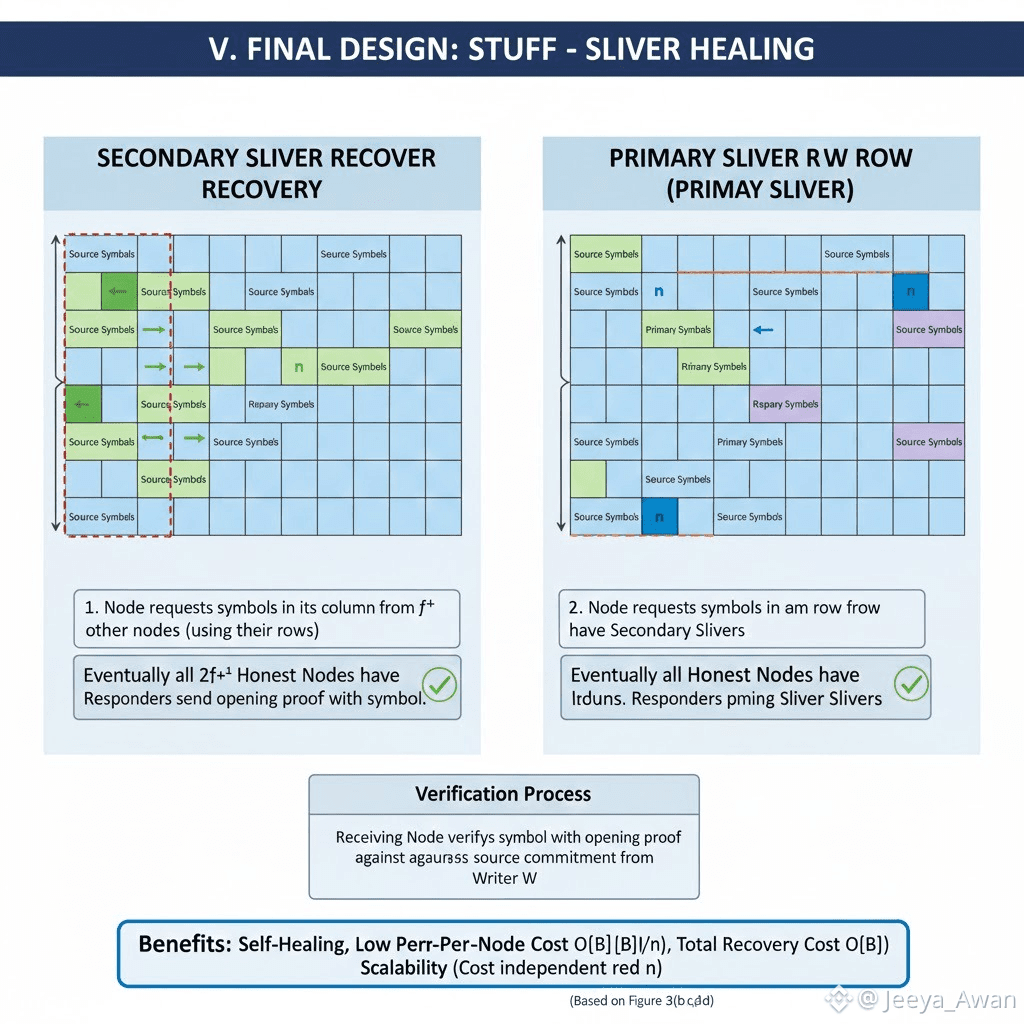
The big advantage of Red Stuff compared to the RS-code protocol is its self-healing property. This comes into play when nodes that did not receive their slivers directly from W try to recover them. Any storage node can recover their secondary sliver by asking f+1 storage nodes for the symbols that exist in their row, which should also exist in the (expanded) column of the requesting node (fig. 3(b) and fig. 3(c)). This means that eventually all 2f+1 honest nodes will have secondary slivers. At that point, any node can also recover their primary sliver by asking the 2f+1
honest nodes for the symbols in their column (Figure 3(d)) that should also exist in the (expanded) row of the requesting storage node. In each case, the responding node also sends the opening for the requested symbol of the commitment of the source sliver. This allows the receiving node to verify that it received the symbol intended by the writer W, which ensures correct decoding if W was honest. Since the size of a symbol is 𝒪(|B|n2) each, and each storage node will download 𝒪(n) total symbols, the cost per node remains at 𝒪(|B|n) and the total cost to recover the file is 𝒪(|B|) which is equivalent to the cost of a Read and of a Write. As a result by using Red Stuff, the communication complexity of the protocol is (almost8) independent of n making the protocol scalable.
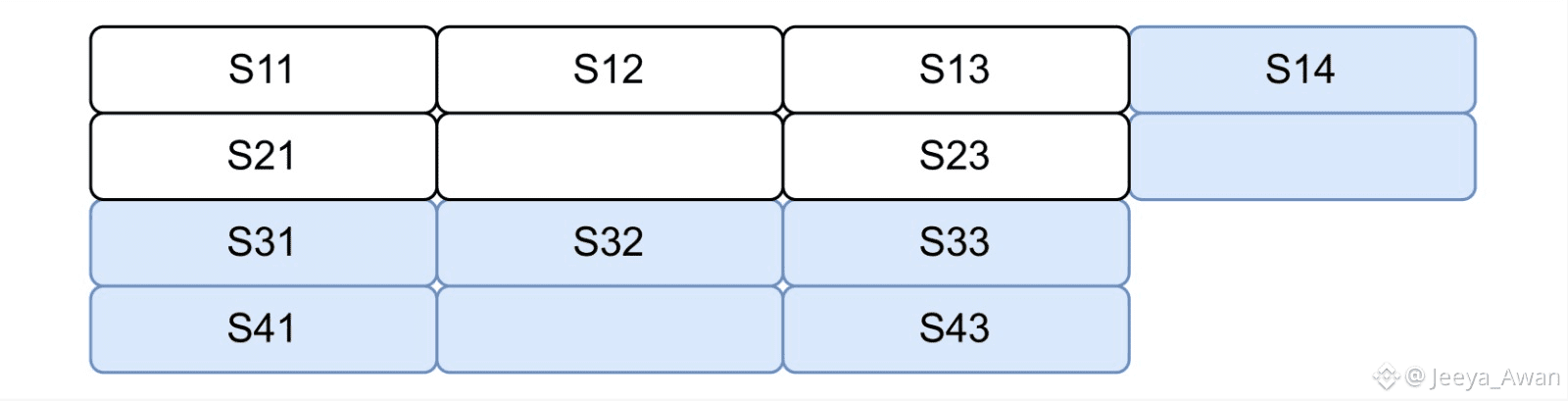
(a)Nodes 1 and 3 collectively hold two rows and two columns.
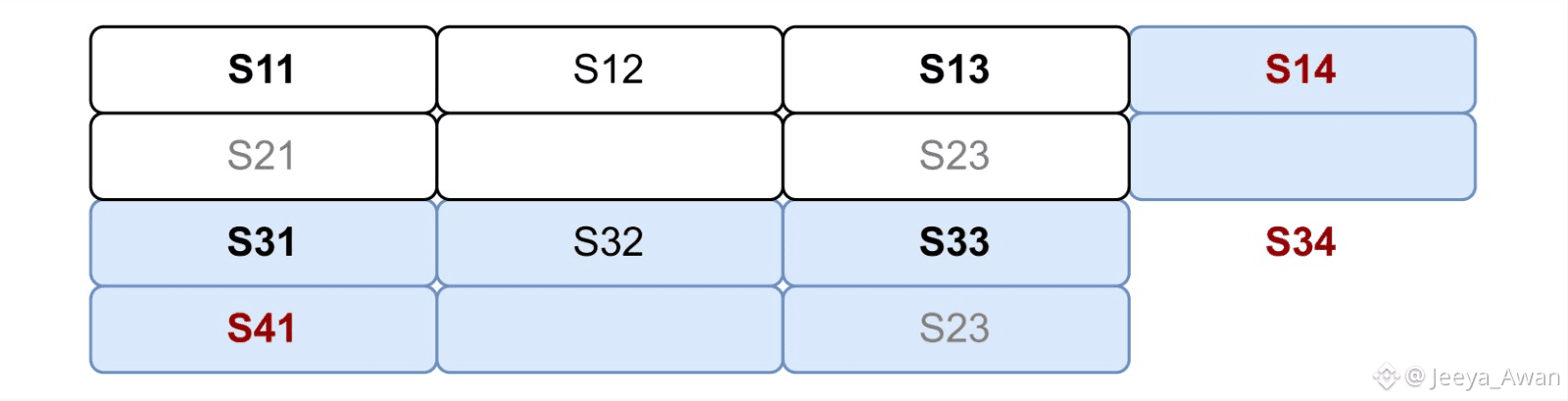
(b)Each node sends the intersection of their row/column with the column/row of Node 4 to Node 4 (Red). Node 3 needs to encode the row for this.
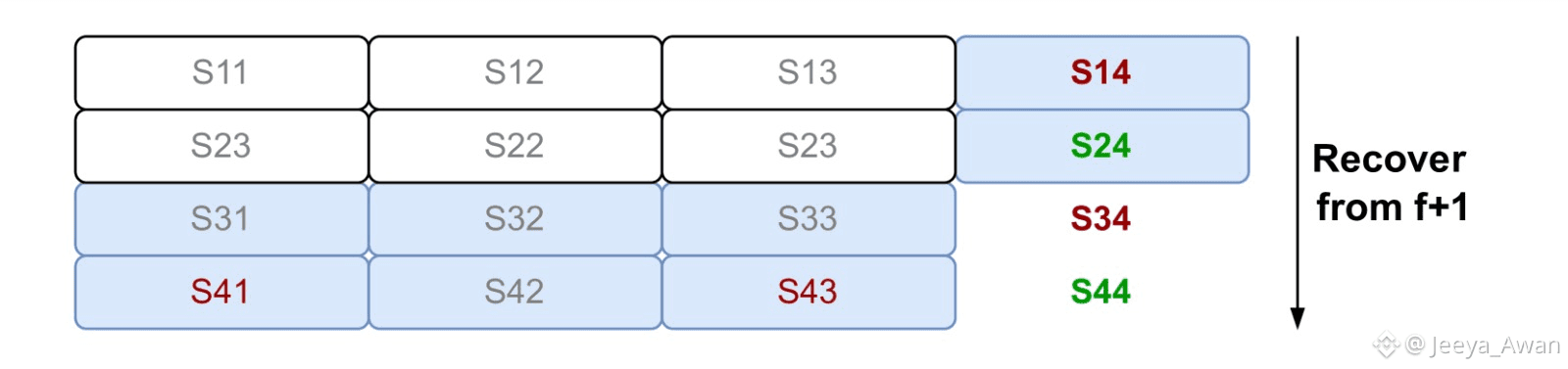
(c)Node 4 uses the f+1 symbols on its column to recover the full secondary sliver (Green). It will then send any other recovering node the recovered intersections of its column to their row.
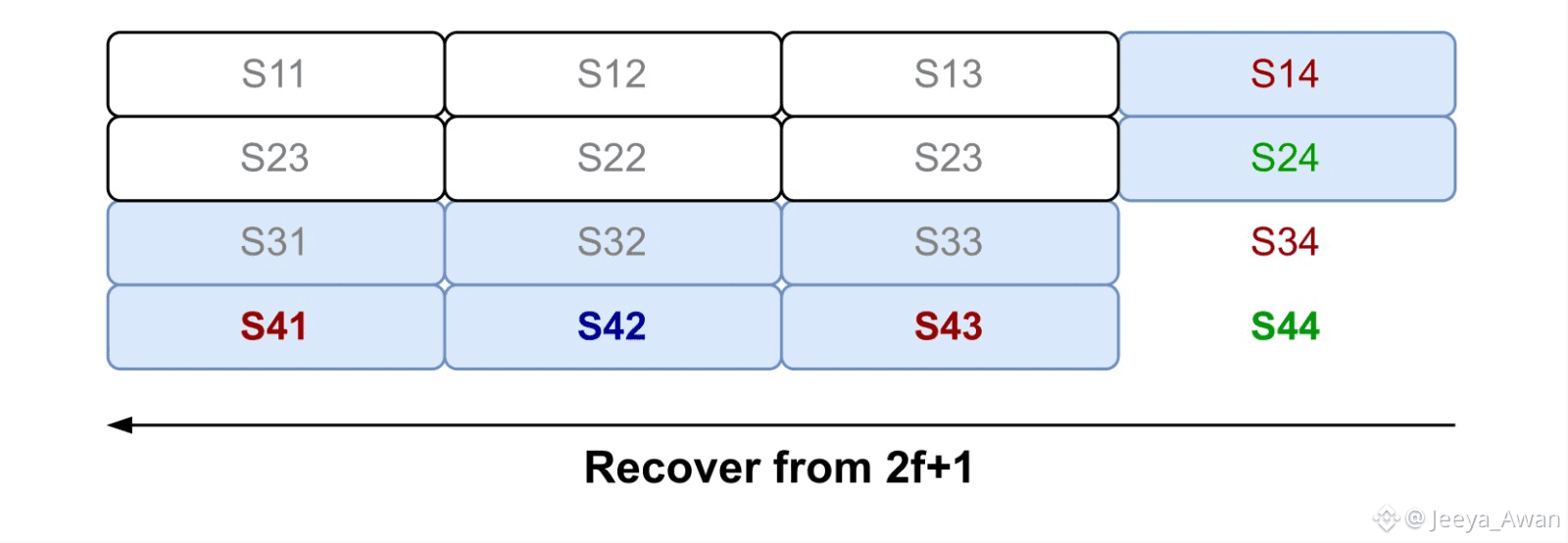
(d)Node 4 uses the f+1 symbols on its row as well as all the recovered secondary symbols send by other honest recovering nodes (Green) (which should be at least 2f plus the 1 recovered in the previous step) to recover its primary sliver (Dark Blue).

