
Walrus Protocol is not trying to be “just another storage narrative” in Web3. It is positioning itself as a serious infrastructure layer where uptime, stability, and operational clarity matter as much as decentralization itself. In decentralized systems, the real test begins after deployment—when nodes run continuously, workloads shift, and network conditions evolve. That is exactly where Walrus stands out, because it doesn’t treat operations as an afterthought. Instead, it supports the operator journey with real tools: monitoring, dashboards, automation, and practical utilities that make day-to-day management reliable and scalable.
Beyond Storage: What Walrus Is Actually Building
At a surface level, people may describe Walrus as a decentralized storage protocol. But for builders and node operators, Walrus represents something deeper: a network designed to function like real production infrastructure. Storage networks are uniquely demanding because they depend on long-term availability, persistent performance, and healthy resource management. When things fail, they often fail slowly, not instantly. Disks fill gradually, memory consumption creeps up, checkpoint downloads become slower over time, or nodes silently slip into degraded performance without fully shutting down.
Walrus recognizes this reality. Instead of expecting operators to “figure out monitoring later,” it embraces the idea that observability is part of the protocol’s survival. A protocol cannot claim long-term reliability unless it gives operators the tools to understand what is happening inside their stack in real time. And Walrus tooling proves that the ecosystem is thinking beyond hype by focusing on the operational backbone.
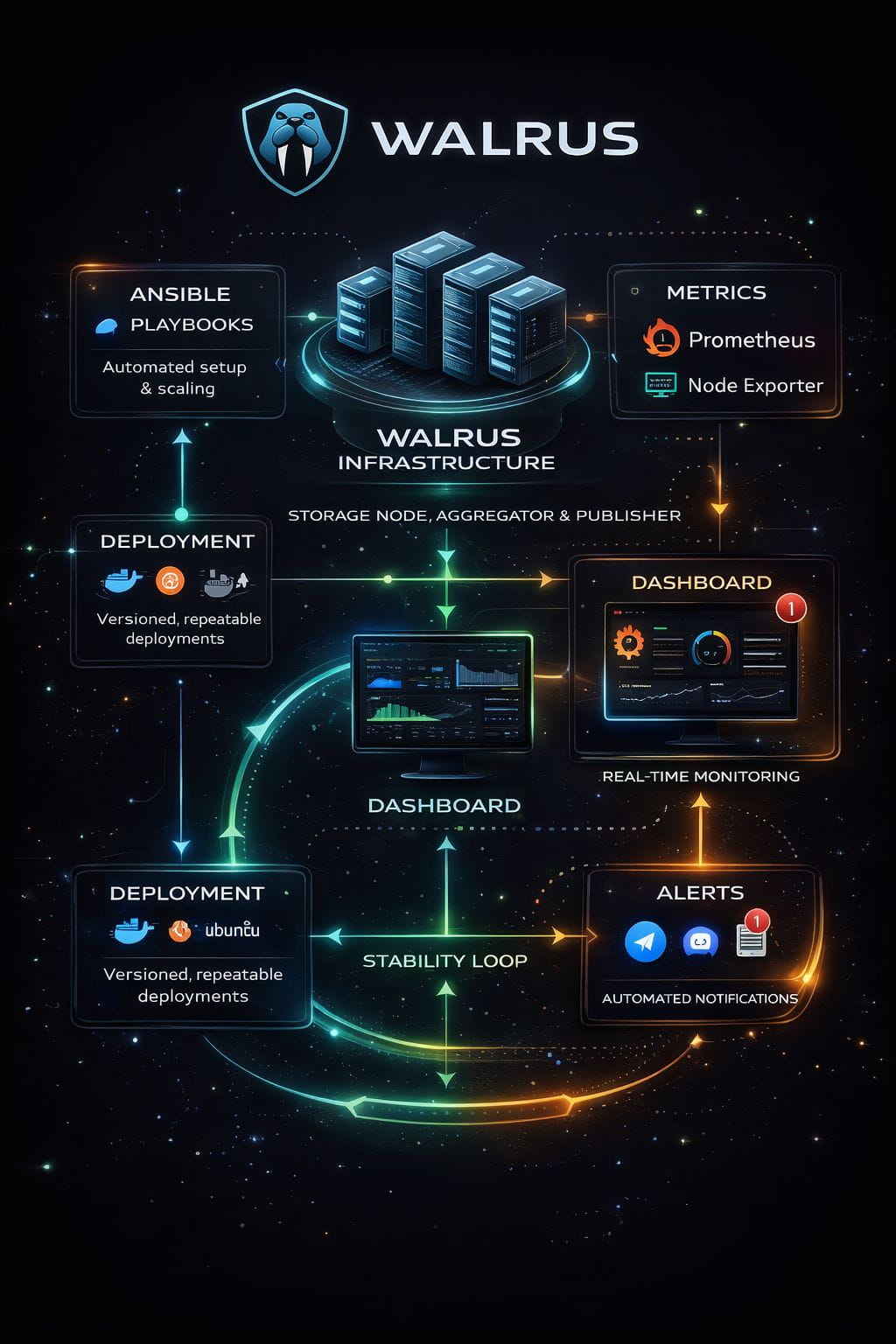
Walrus Monitoring: The Invisible Layer That Makes Decentralization Real
Monitoring is one of those topics that isn’t flashy, but it determines whether a network is truly sustainable. Walrus supports monitoring across core node services such as the Storage Node, Publisher, and Aggregator, while also tracking the health of the underlying hardware. This is important because most failures start at the machine level. CPU saturation, RAM exhaustion, disk IO pressure, overheating, and network bottlenecks are the first signals of future downtime. A decentralized storage operator must see these signals early, not after they become disasters.
That is why Walrus integrates a monitoring stack based on Grafana, Prometheus, and Node Exporter. Prometheus works as the time-series engine that collects and stores metrics. Node Exporter provides deep visibility into hardware and operating system performance. Grafana acts as the visual command center where all metrics come together in a clean dashboard interface. When these pieces work together, an operator can understand not only whether services are running, but also how efficiently they are running and what risks are building up under the surface.
This is what turns node operation into professional infrastructure management.
Importing the Walrus Dashboard: A Fast Setup With a Professional Result
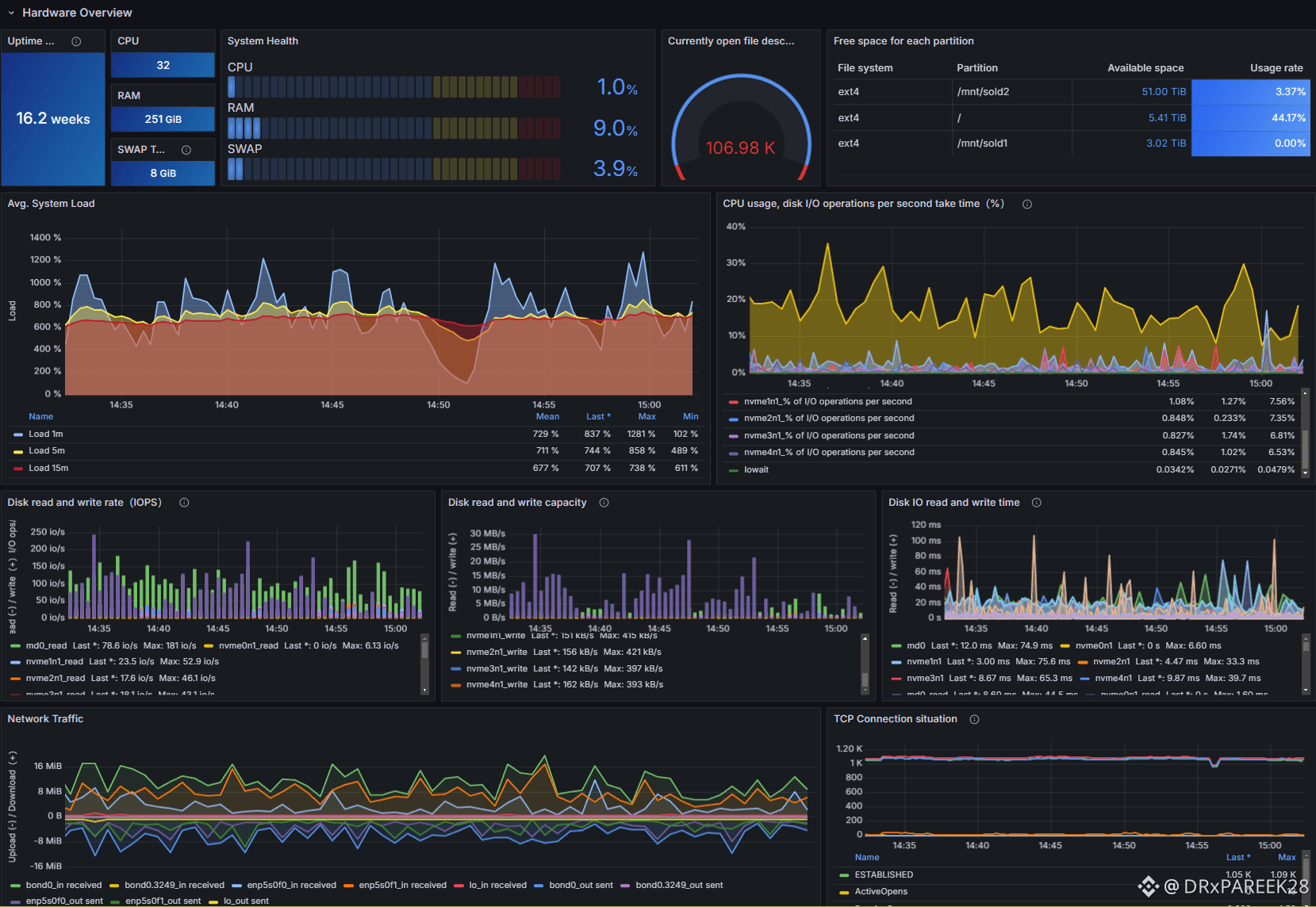
A major advantage in Walrus tooling is the ability to import a ready-made Grafana dashboard. For most operators, creating dashboards manually is both time-consuming and error-prone. Walrus avoids that pain by providing a structured dashboard configuration in JSON format. By downloading the Walrus-Dashboard.json file and importing it inside Grafana through the dashboard import workflow, operators can instantly deploy a full monitoring layout that reflects the key performance and health indicators relevant to the Walrus stack.
What makes this process even smoother is that the imported dashboard automatically searches for Prometheus data sources matching names like “Walrus,” “walrus,” or even “wal.” This reduces friction during setup and helps ensure that the system connects to the correct monitoring source with minimal manual tuning. If adjustments are required, the operator can modify the selection conditions later inside dashboard settings by working with variables such as the datasource variable and updating the instance name filter logic.
This attention to usability matters. It means Walrus isn’t only building technology. It’s designing an experience, and that’s what accelerates adoption.
Prometheus Metrics: Understanding More Than “Node Online”
In many networks, operators only track basic uptime. But in real decentralized systems, uptime is not enough. Walrus monitoring goes deeper. It allows operators to observe checkpoint download progress and rate, understand epoch-related node behavior, and track operational performance indicators that reveal whether the system is healthy or quietly struggling.
Metrics like checkpoint progress are especially important because they represent synchronization stability and network readiness. If checkpoint download rates slow down, it may indicate bandwidth issues, storage issues, or a bottleneck in the pipeline. If pending events start accumulating, it could hint at performance constraints or service degradation. Walrus monitoring gives access to these signals so operators can react early rather than waiting for full failure.
This kind of visibility transforms the role of an operator from “someone who runs a node” into “someone who maintains infrastructure reliability.”
Alertmanager: Turning Monitoring Into Protection
Dashboards are powerful, but dashboards don’t prevent downtime by themselves. The real weapon is automated alerting. With Alertmanager integrated into the monitoring approach, Walrus operators can set thresholds and define alert rules that trigger notifications before issues become critical.
Alerting can be connected to channels like Tg, Discord, SMS, or other delivery methods. This makes node operations much more resilient because the operator does not need to constantly stare at Grafana to know something is wrong. Instead, the system becomes proactive. Disk usage thresholds can warn the operator when storage consumption reaches dangerous levels. Node and epoch status alerts can flag unusual behavior. Checkpoint download progress warnings can highlight slowdowns before they turn into downtime. Even patterns in persisted, processed, and pending events can be used as predictive signals that the node is under stress.
This is where Walrus becomes truly operator-first. It enables not only observability but also operational defense.
Walrus Ansible Deployment: Scaling Like Real Infrastructure
Another major strength of Walrus tooling is automation through Ansible-based deployment. In decentralized networks, scalability is not just about the protocol’s throughput. It is also about whether operators can deploy nodes consistently across environments without configuration drift and without repeated human errors.
Ansible playbooks make deployment repeatable and structured. Walrus deployment support includes automating node setup on Ubuntu and handling components such as Storage, Aggregator, and Publisher. This creates a clean framework for operators who want professional-level control. It also makes upgrades easier, because changes can be applied systematically instead of manually patching production setups.
Walrus even acknowledges the practical reality that deployment requirements may change. If different Docker images are required for different setups, operators can modify templates such as docker-compose.yaml and Dockerfile to reflect the correct image URL and version. This flexibility matters because production environments are never “one size fits all.” Walrus tooling is designed with that reality in mind.
Operator Tooling: Walrus Makes Participation Easier and More Sustainable
Beyond monitoring and deployment, Walrus also supports operator tooling that improves usability and long-term participation. Utilities like commission claim tools reduce the operational friction that often discourages consistent node operators. Supporting commission collection through Sui wallet-compatible options like zkLogin wallets, hardware wallets, and passphrase wallets makes the ecosystem more accessible.
At the same time, Walrus supports technical configurations like aggregator cache setup with NGINX and Let’s Encrypt. This shows that the protocol ecosystem understands performance and security at the edge. Caching helps enhance responsiveness and reduce load, while proper encryption improves trust and safety for traffic handling.
When a protocol supports these details, it demonstrates maturity. It is not just building features; it is building operational quality.
The Bigger Meaning: Why Walrus Feels Like Real Infrastructure
Many Web3 projects focus on narratives and overlook operational sustainability. Walrus takes the opposite path. By supporting monitoring stacks, dashboard imports, alerting, automation, and operator tools, Walrus creates a strong foundation for decentralized infrastructure that can actually stay online and perform.
This matters because the future of decentralized storage won’t be decided by marketing. It will be decided by reliability. Users will always choose the infrastructure layer that works consistently, scales smoothly, and gives confidence to operators and builders alike.
Conclusion: Walrus Is Storage With Operational Intelligence
Walrus Protocol is not only a storage network. It is an ecosystem designed to be operated professionally. The monitoring stack using Prometheus, Grafana, and Node Exporter provides visibility into both services and hardware. The dashboard import workflow makes setup fast and standardized. Alertmanager turns monitoring into active protection. Ansible deployment makes scaling repeatable and safe. Operator utilities reduce friction and strengthen participation.
When all of these pieces come together, Walrus doesn’t feel like an experiment. It feels like the next evolution of decentralized infrastructure—where reliability is not assumed, but engineered.

