Saya sudah cukup lama terlibat dalam pembicaraan tentang Kecerdasan Buatan dan crypto untuk tahu kapan sebuah penawaran hanya terlihat rapi di luar tetapi ide yang lemah di dalam. Sebagian besar model imbalan di ruang ini masih terasa malas. Bergabung, klik, pos, stake, farm, ulang. Itu hanya menghitung gerakan. Tidak bertanya apakah kerja kerasmu membuat sesuatu menjadi lebih baik. Itu adalah cara buruk untuk menilai kontribusi manusia, dan bahkan lebih buruk ketika data AI terlibat.
@OpenLedger dengan $OPEN lebih layak untuk dibaca dengan seksama karena mencoba menangani kekacauan lama, siapa yang seharusnya mendapatkan imbalan ketika banyak tangan membentuk satu model?
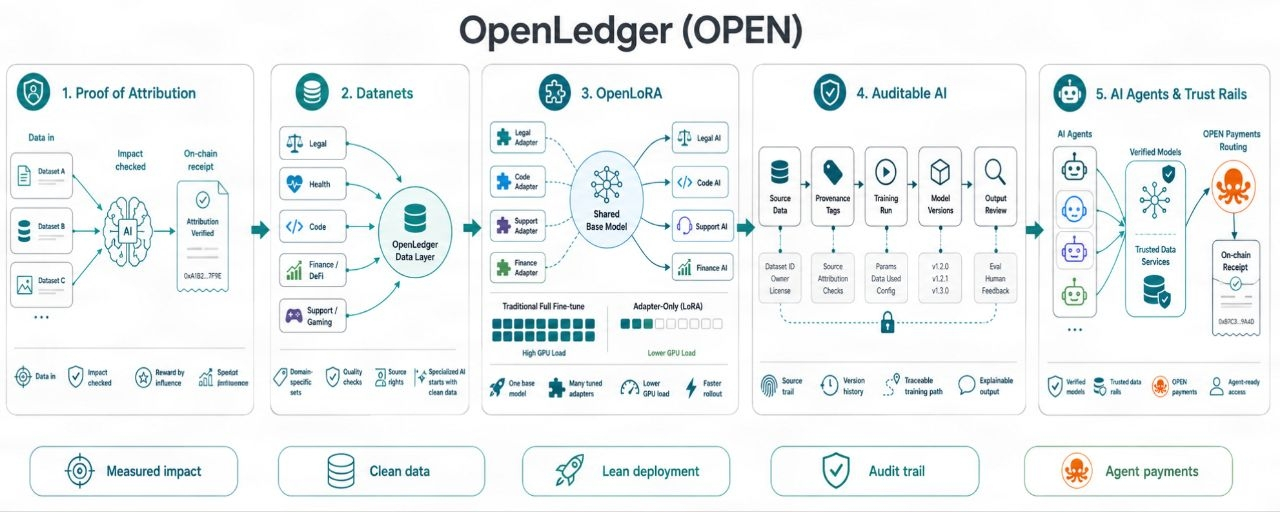
Proof of Attribution itu berguna karena menggeser fokus dari 'Saya ikut serta' ke 'data saya mengubah kualitas output.'
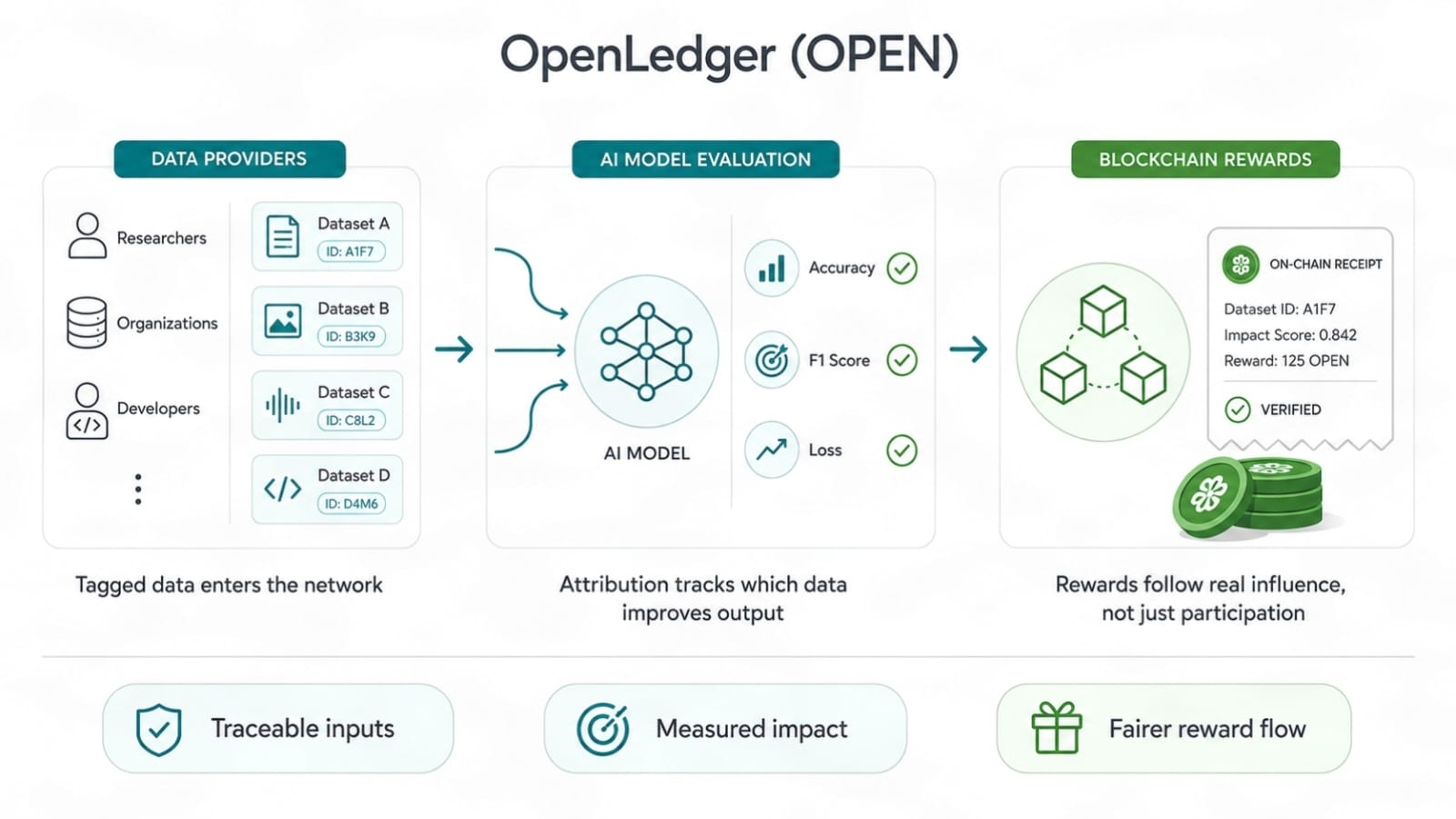
Itu terdengar kecil. Itu tidak. Pasar data AI memiliki banyak bobot sampah. Orang bisa membuang file, menggores teks berkualitas rendah, mengganti namanya, dan berharap skala menyembunyikan nilai sumber yang lemah. Jika imbalan mengikuti input mentah, spam menang. Jika imbalan mengikuti peningkatan nyata, kualitas memiliki jalur.
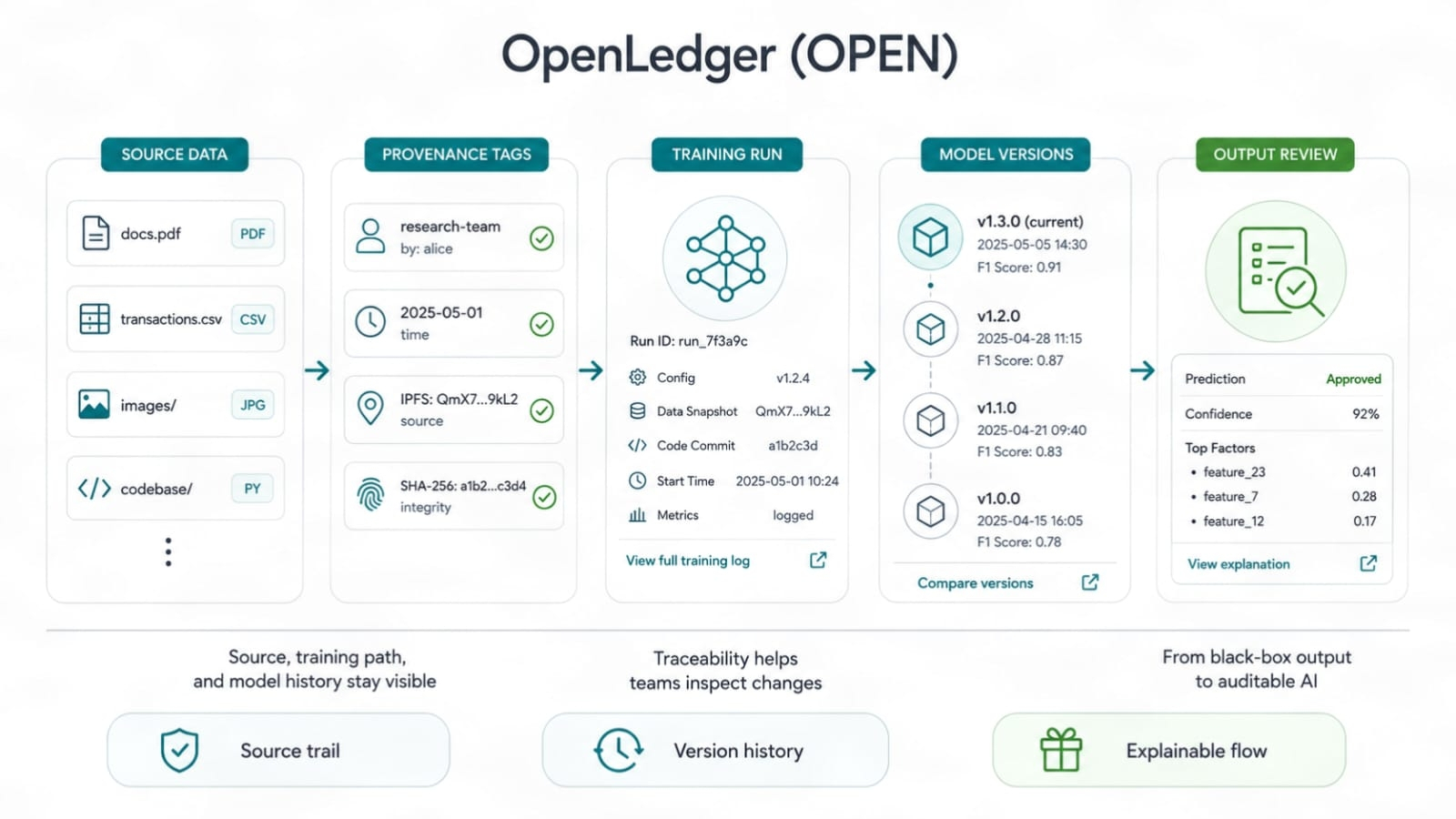
Itu sulit dilakukan. Saya tidak akan mempercantiknya. Atribut dalam AI bukanlah mainan matematika yang bersih. Model belajar dengan cara yang berantakan. Satu dataset mungkin membantu satu tugas dan merugikan yang lain. Beberapa input menambah keterampilan edge-case. Beberapa hanya mengulangi apa yang sudah diketahui model. Jadi klaim OpenLedger harus hidup atau mati tergantung seberapa baik ia dapat melacak dampak data, hak, penggunaan model, dan aliran imbalan. Dokumen yang bagus tidak akan cukup. Bukti hidup akan sangat penting.
Data perlu jejak bukti. Bukan badge palsu. Bukan skor kebanggaan. Jejak yang menunjukkan dari mana input data berasal, bagaimana data itu digunakan, dan peran apa yang dimainkannya. Itulah yang diinginkan penyedia data jika mereka serius. Mereka tidak ingin berdiri di keramaian dan berharap mendapatkan remah-remah. Mereka ingin tahu apakah data mereka memiliki daya tarik.
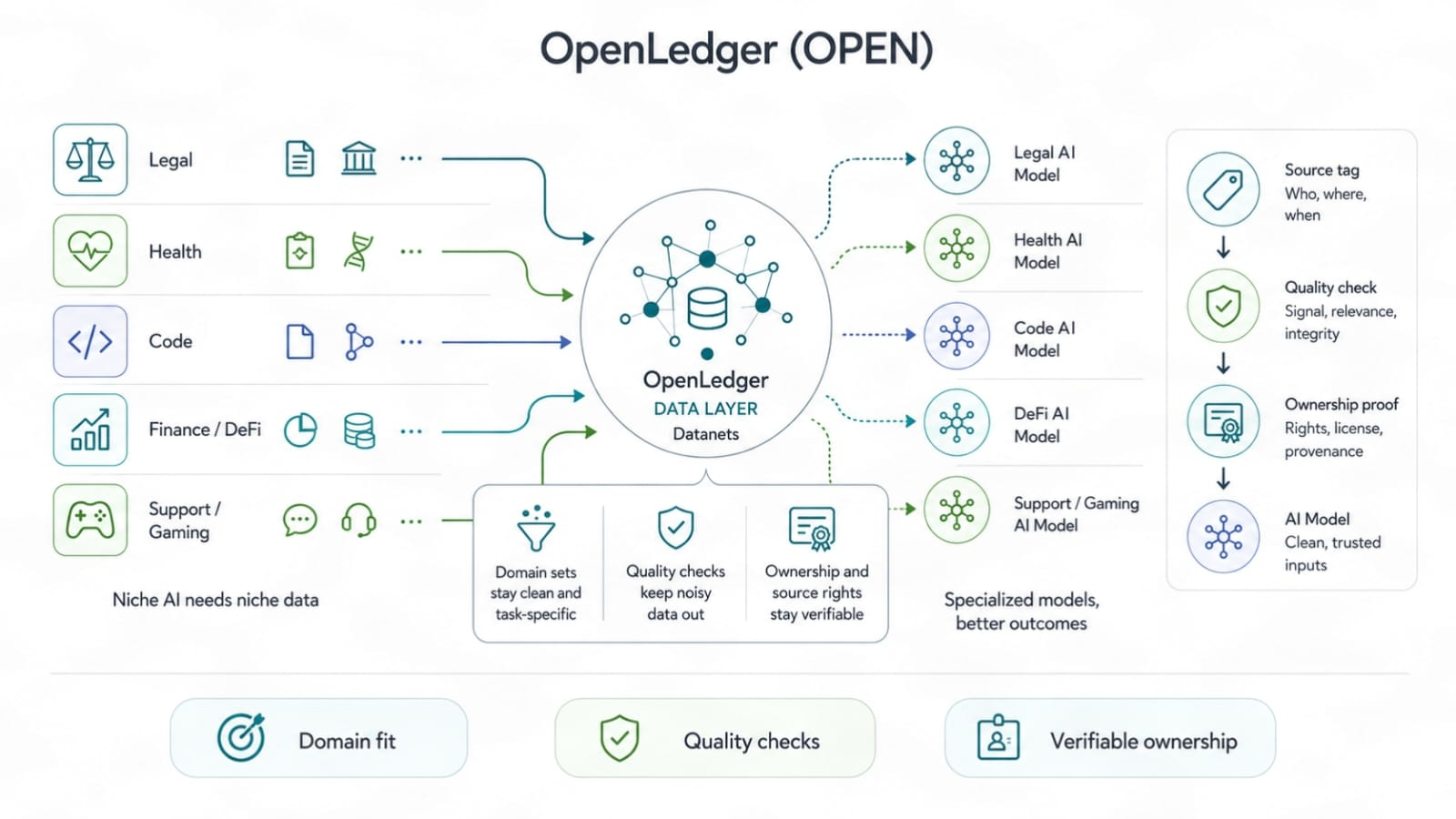
Datanets adalah tempat ini mulai menjadi lebih nyata. Data AI yang luas memiliki batasan. Anda bisa melatih model umum pada tumpukan teks besar, tentu. Tapi saat Anda membutuhkan model untuk hukum, kode, administrasi kesehatan, aset permainan, risiko DeFi, statistik olahraga, atau operasi dukungan, data luas mulai terasa tipis. Data tugas menang. Data bersih menang. Data yang dimiliki menang.
Datanet bisa bertindak seperti ruang kerja untuk satu bidang. Ia bisa menyimpan data sumber, tautan hak, catatan penggunaan, dan kecocokan tugas. Itu lebih berguna daripada satu ember besar di mana semua data dicampur hingga tidak ada yang tahu dari mana asalnya. Jika OpenLedger bisa membantu setiap domain menjaga jejak data mereka sendiri, maka pembangun niche mendapatkan basis yang lebih baik untuk dilatih. Tidak sempurna. Lebih baik.
Ini juga memberi pemilik data kecil kesempatan yang adil. Tim mungkin tidak memiliki skala raksasa, tetapi mungkin memiliki data langka dengan nilai penggunaan tinggi. Di pasar lama, ukuran cenderung mengalahkan keterampilan. Di pasar yang berbasis atribusi, seperangkat kecil yang meningkatkan output model bisa lebih berarti daripada tumpukan besar yang menambah kebisingan. Itu adalah kerangka yang lebih sehat. Ini memberi imbalan pada edge nyata, bukan volume yang keras.
OpenLoRA kemudian cocok dengan titik nyeri kedua, biaya penerapan model. Model yang disesuaikan terdengar hebat sampai biaya GPU muncul. Pekerjaan model penuh dapat menghabiskan anggaran dengan cepat. Metode gaya LoRA membantu karena mereka menyesuaikan model dasar dengan perubahan yang lebih ringan. Anda tidak perlu menyeret model baru yang penuh setiap kali. Anda dapat menjalankan banyak jalur yang disesuaikan dengan beban yang lebih sedikit.
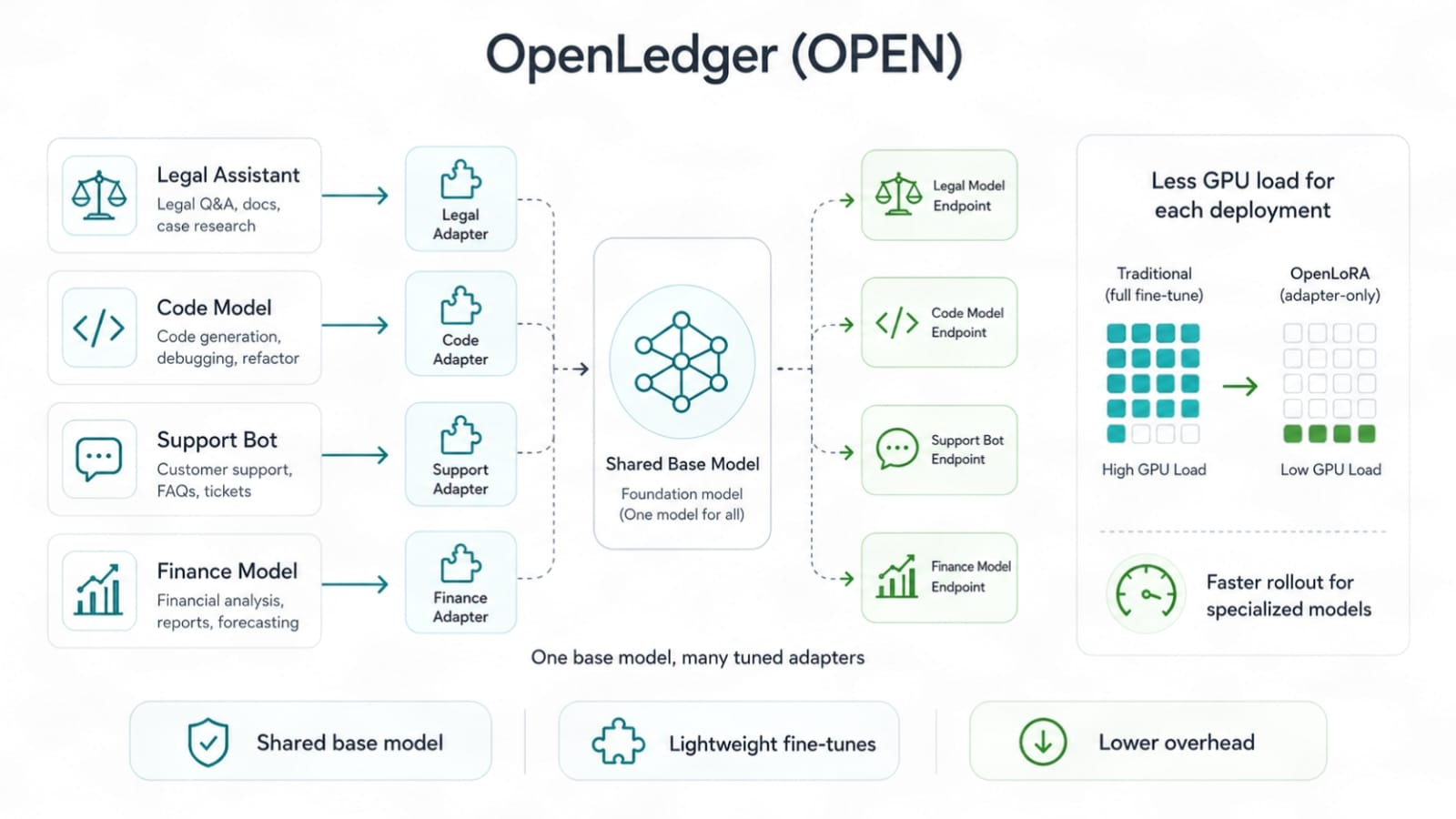
OpenLedger, OpenLoRA bisa berarti lebih banyak model tugas yang dilayani dengan sedikit drag komputasi. Itu penting karena AI masa depan tidak akan menjadi satu model raksasa yang melakukan semua pekerjaan dengan baik. Itu akan menjadi banyak model yang fokus, masing-masing disesuaikan untuk satu jalur. Satu untuk pencarian hukum. Satu untuk operasi keuangan. Satu untuk dukungan permainan. Satu untuk pemeriksaan data rantai. Satu untuk penggunaan alat agen. Kecil, tajam, cukup murah untuk dijalankan. Itu bukan hype. Itu adalah tempat banyak pekerjaan AI sudah mengarah.
Tetapi pemotongan biaya tidak bisa datang dengan mengorbankan kepercayaan. Model murah yang tidak bisa dilacak oleh siapa pun hanyalah masalah cepat. Tim membutuhkan sejarah model. Data apa yang digunakan? Versi mana yang berubah? Siapa yang menambahkan apa? Apakah dataset baru membuat jawaban semakin buruk? Bisakah pembangun mengembalikan? Bisakah pemilik data membuktikan penggunaan? Ini bukan item yang bisa dikesampingkan. Ini adalah cara tim nyata menjaga kontrol ketika AI bergerak ke dalam operasi sehari-hari.
AI black-box masih memiliki bau lemah di sekitarnya. Bukan karena AI itu buruk, tetapi karena kepercayaan rusak ketika tidak ada yang bisa mengaudit jalur. Jejak audit OpenLedger bertujuan untuk membuat sejarah pembangunan model lebih mudah untuk diperiksa. Kemampuan pelacakan dan bukti sumber terdengar kering sampai sesuatu rusak. Kemudian mereka menjadi alat inti. Siapa pun yang telah mengirimkan sistem nyata tahu ini. Log mengalahkan vibe.
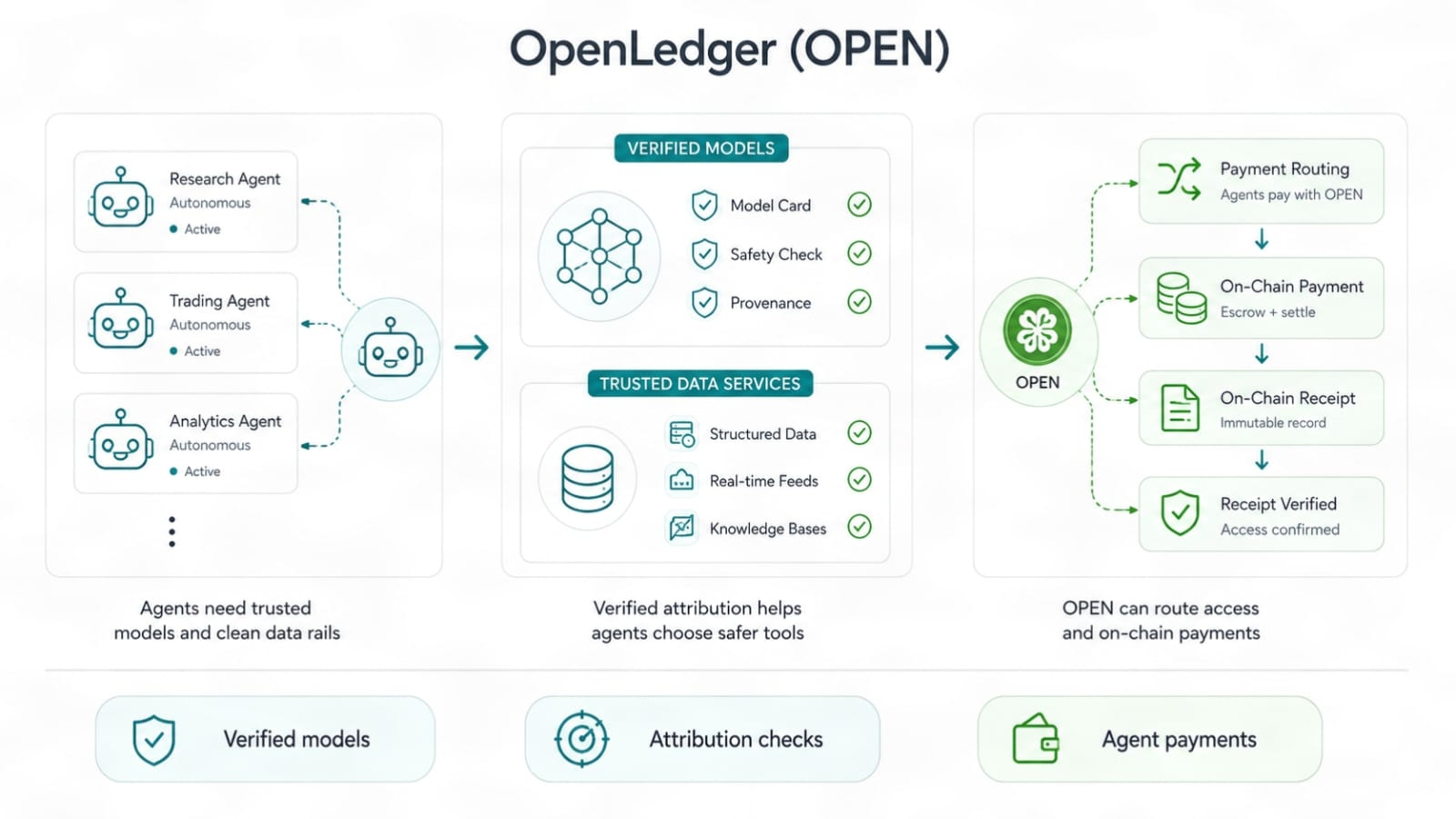
Agen AI meningkatkan taruhan lagi. Agen tidak hanya menjawab. Mereka bertindak. Mereka memanggil model, menggunakan data, mengarahkan tugas, dan mungkin membayar untuk akses di seluruh sistem. Begitu agen mulai membuat lebih banyak pilihan sendiri, rel kepercayaan menjadi penting. Model dengan sejarah data yang terverifikasi lebih aman untuk dipasangkan ke aliran agen daripada yang memiliki akar yang tidak diketahui. Layer pembayaran yang terikat pada OPEN bisa membantu mengarahkan biaya dan imbalan dalam pengaturan itu, tetapi hanya jika penggunaan nyata dan aturan tetap jelas.
OpenLedger menunjuk pada kebutuhan pasar yang nyata, imbalan yang adil untuk data AI yang berguna. Proof of Attribution bukan tentang memberikan token kepada siapa pun yang muncul. Ini tentang menghubungkan imbalan dengan dampak. Datanets memberikan data domain tempat untuk membuktikan nilai. OpenLoRA memberikan model yang disesuaikan jalur penerapan yang ramping. Alat audit membawa sejarah sumber ke dalam pandangan. Pembayaran agen mengisyaratkan pekerjaan AI masa depan di mana model, data, dan tugas bergerak dengan lebih sedikit drag manusia.
DYOR, selalu. Baca dokumen. Lacak penggunaan. Perhatikan bagaimana imbalan bekerja dalam pandangan terbuka. Periksa apakah kualitas data tetap tinggi ketika insentif tumbuh. Periksa apakah OPEN memiliki kebutuhan yang jelas dalam alur kerja, bukan hanya logo di atas. Desain bersih tidak sama dengan kecocokan pasar yang keras.
Saya tidak di sini untuk memunculkan apapun. Crypto telah membakar terlalu banyak orang pintar yang jatuh cinta dengan kata-kata yang rapi. Tapi saya percaya OpenLedger sedang menanyakan salah satu pertanyaan yang tepat. Dalam kecerdasan buatan, nilai tidak akan datang hanya dari memiliki data. Itu akan datang dari membuktikan data mana yang membantu, siapa yang memilikinya, ke mana ia pergi, dan mengapa ia layak mendapatkan bagian. Di situlah cerita ini memiliki gigi.
