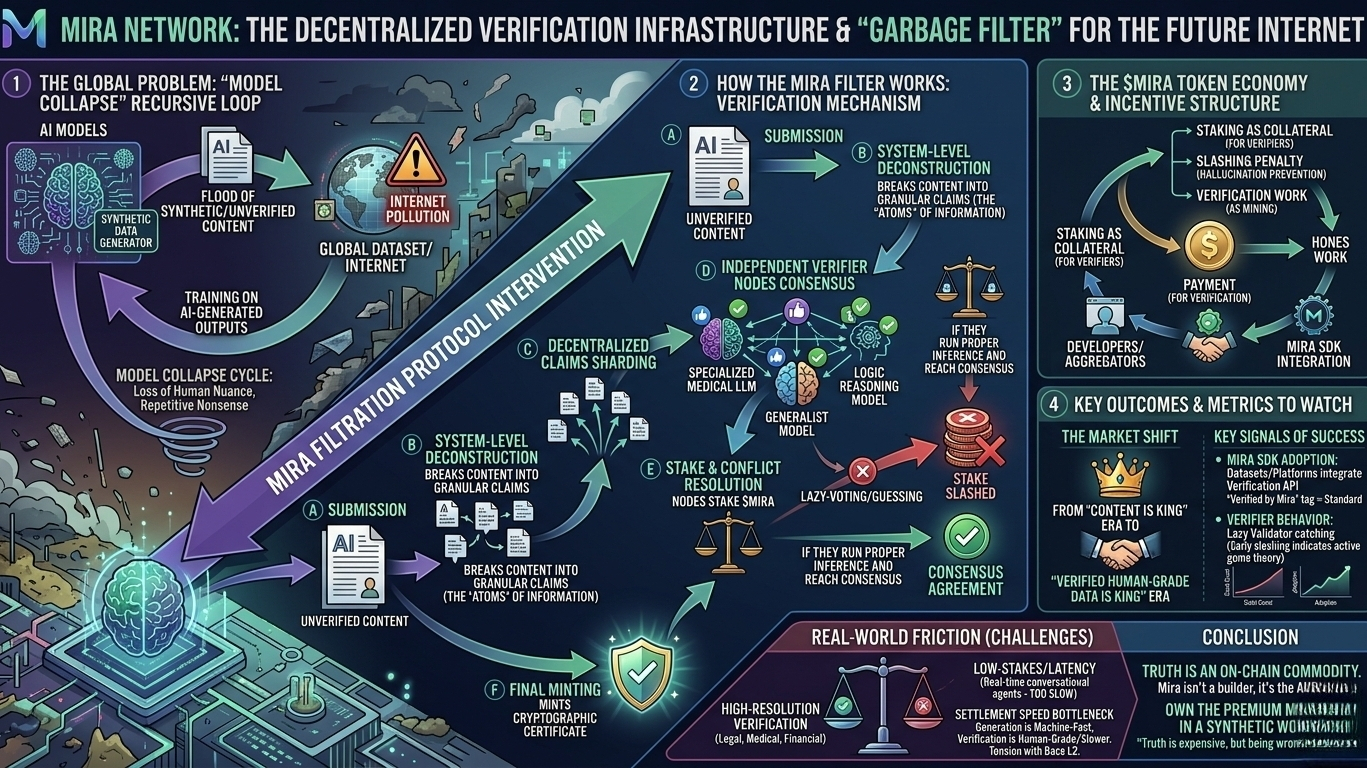
Ho trascorso la maggior parte della mia mattina oggi leggendo l'ultima ricerca su "Model Collapse" e, francamente, è molto più spaventoso del tipico racconto "L'IA ci porterà via il lavoro". Se non hai ancora visto il termine, è il fenomeno in cui i modelli IA iniziano a formarsi sugli output di altri modelli IA. Poiché attualmente Internet è inondato di contenuti sintetici, non verificati e leggermente "fuori" norma, stiamo entrando in un ciclo ricorsivo. I modelli sono essenzialmente inbreeding, perdendo i "particolari" della sfumatura umana e alla fine trasformandosi in una miscela di sciocchezze ripetitive e sicure.
Qui è dove penso che il mercato stia completamente perdendo di vista il punto sulla Rete Mira.
La maggior parte delle persone vede Mira come un'altra opportunità di AI decentralizzata—un modo per ottenere risposte "più economiche" o "decentralizzate". Ma dopo aver approfondito il loro meccanismo di verifica oggi, ho realizzato che questa è la lente sbagliata. Mira non riguarda davvero la creazione di AI; riguarda l'agire come il filtro ad alta risoluzione che impedisce all'intero ecosistema di dati AI di collassare sotto il proprio peso.
La Tesi
Il vero valore di Mira non è la generazione di contenuti, ma la Prova di Provenienza. Mentre i dati sintetici inquinano il set di addestramento globale, il mondo passerà da un'era in cui "il contenuto è re" a un'era in cui "i dati di qualità umana verificati sono re". Mira è la prima infrastruttura che ho visto trattare la "Verità" come una merce dimostrabile e on-chain attraverso un meccanismo che può effettivamente scalare.
Come Funziona Effettivamente il Filtro
Se guardi alla documentazione, il nucleo di Mira non è un singolo modello "giudice". Sarebbe solo un collo di bottiglia centralizzato. Invece, è una de-costruzione a livello di sistema.
Quando un'AI (o un umano) presenta un output, il protocollo di Mira non guarda solo l'intero paragrafo e dice "sembra buono." Scompone il contenuto in affermazioni granulari e indipendenti. Queste sono gli "atomi" di informazione. Queste affermazioni vengono poi shardate—invitate a una rete decentralizzata di nodi verificatori indipendenti.
Qui è dove diventa interessante dal punto di vista meccanico: questi nodi non eseguono tutti lo stesso modello. Sono diversi. Uno potrebbe essere un LLM medico specializzato, un altro un generalista, un altro un modello di ragionamento logico pesante. Votano tutti.
Ma parlare è economico nel crypto, quindi Mira costringe a mettere in gioco del capitale. Per essere un verificatore, devi mettere in stake $MIRA. Se cerchi di risparmiare denaro con "votazione pigra" o indovinando senza effettivamente eseguire l'inferenza, e il resto della rete raggiunge un consenso diverso, il tuo stake viene ridotto.
Il Token è l'Incentivo per la Verità
Il token $MIRA non è solo un "pagamento per un chatbot." È la garanzia funzionale che rende la verifica onesta.
Riduzione come Controllo Qualità: Crea una penalità finanziaria diretta per le allucinazioni.
Lavorare come Mining: In Mira, "Lavorare" non significa risolvere enigmi inutili; è il reale calcolo della verifica.
Il Certificato: Una volta che la rete è d'accordo, conia un certificato crittografico.
Pensa a perché questo è importante per il problema del "Collasso del Modello". Se sono uno sviluppatore che costruisce un nuovo modello fondamentale nel 2027, non posso semplicemente estrarre dati dal web—è troppo avvelenato. Ho bisogno di un modo per filtrare i dati di "Qualità Verificata". Pagherei (in $MIRA) per verificare che il mio set di addestramento sia passato attraverso un consenso decentralizzato.
L'Attrito del Mondo Reale
Ora, diciamo la verità—questo non è ancora un rimedio magico. Il collo di bottiglia più grande che vedo in questo momento è la latenza. Suddividere un articolo di 500 parole in 20 affermazioni e aspettare che un consenso decentralizzato si "stabilizzi" richiede più tempo di una chiamata API grezza a GPT-4.
Se Mira vuole essere l'infrastruttura globale per la verità, deve risolvere la "Velocità di Liquidazione" della verifica. In questo momento, è ottima per documenti ad alto rischio (legali, medici, finanziari), ma è ancora troppo lenta per un agente conversazionale in tempo reale. Stanno usando Base per l'efficienza L2, il che aiuta, ma il livello di verifica "di qualità umana" è naturalmente più lento rispetto al livello di generazione "veloce per macchina". Questa è una tensione che non hanno ancora risolto completamente.
Cosa Sto Guardando
Mi sto distaccando dal guardare il loro "numero di utenti" e invece guardando l'adozione del loro SDK per sviluppatori.
Il segnale che proverebbe giusta la mia tesi non è un aumento di prezzo; è vedere un grande aggregatore di dati o una piattaforma di affinamento integrare l'API di verifica di Mira per "pre-filtrare" i loro dataset. Se vediamo un'etichetta "Verificato da Mira" diventare uno standard per dati di addestramento di alta qualità, allora il progetto è transitato con successo da un "giocattolo crypto-AI" a un'utilità globale.
Sto anche monitorando il comportamento del "Validatore Pigro". Se vediamo molti tagli all'inizio, significa che la teoria dei giochi sta funzionando—sta catturando le persone che cercano di imbrogliare il sistema.
Pensiero Finale
Abbiamo trascorso gli ultimi due anni ossessionati da quanto velocemente l'AI possa generare contenuti. Stiamo per trascorrere i prossimi cinque anni ossessionati da come possiamo provare che uno qualsiasi di essi sia realmente vero. Mira non è un costruttore di AI; è il suo revisore. In un mondo di spazzatura sintetica, il revisore è colui che possiede realmente il mercato premium.
La verità è costosa, ma avere torto sta iniziando a costare molto di più.
@SignOfficial #SingDigitalSovereignInfr $SIGN
