I keep watching @OpenLedger and trying to figure out whether community-contributed datanets produce quality data or whether decentralizing data collection just means decentralizing garbage at scale.
What I'm watching isn't whether the attribution infrastructure works. Tracking who contributed what is solved engineering. What I'm watching is whether the data being contributed is actually valuable or whether incentivizing contribution creates quantity without quality.
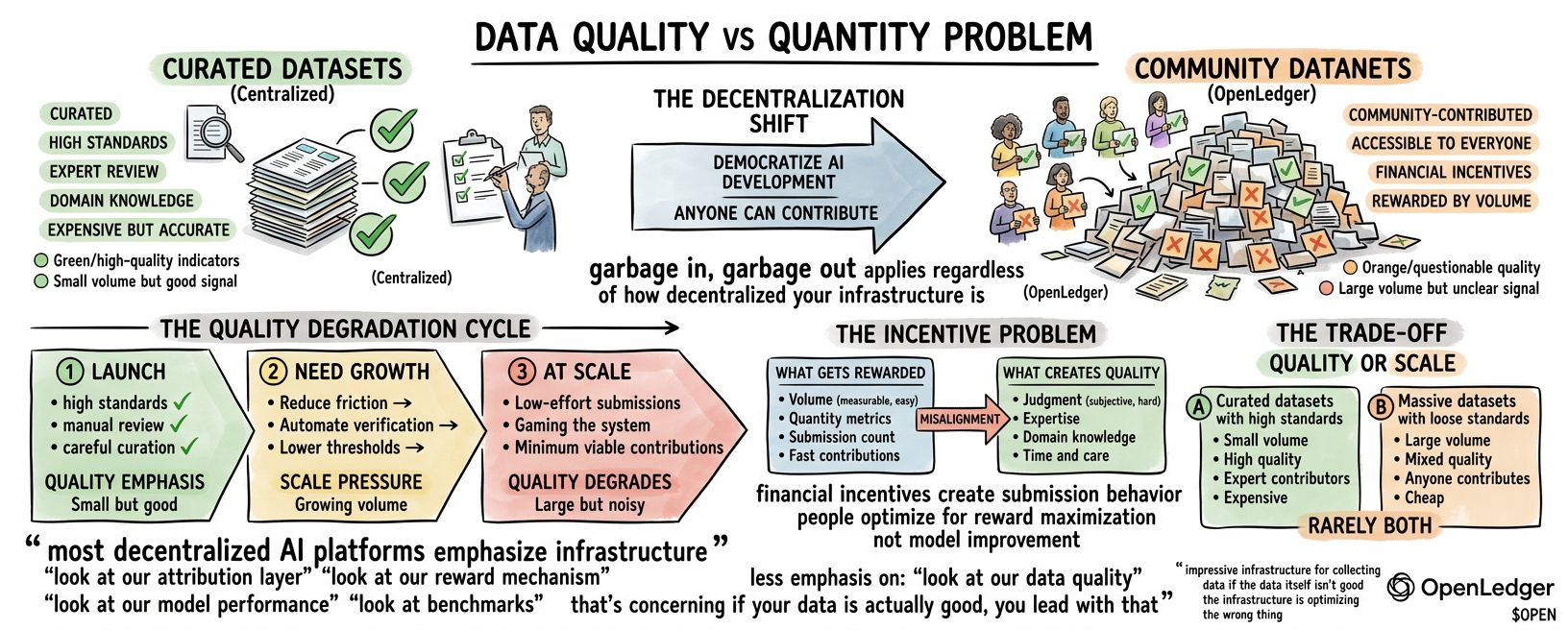
The data quality problem in decentralized AI.
Not the verification mechanism. The fundamental challenge of ensuring that when you reward people for contributing data, they contribute good data rather than gaming the reward system with low-effort submissions that pass minimum standards but don't improve model performance.
That distinction matters because garbage in, garbage out applies regardless of how decentralized your infrastructure is.
OpenLedger lets anyone create datanets or contribute to existing ones. Contributors upload data, get it verified on-chain, and earn rewards. The more you contribute, the more you earn.
What I can't tell is whether "accessible to everyone" produces valuable datasets or whether it produces noise that dilutes signal.
The challenge is that financial incentives create submission behavior. When you pay people to contribute data, they contribute data. But the data they contribute optimizes for reward maximization, not necessarily for model improvement.
Most crowdsourced data collection faces this problem. You need volume. So you lower barriers. You reward quantity.
And you get low-effort submissions. Gaming the system. Minimum viable contributions that qualify for payment but don't add value.
@OpenLedger has verification mechanisms. Data gets reviewed. There's quality control.
What I'm watching is whether those mechanisms work at scale or whether they work initially and break down when volume increases and verification becomes costly relative to rewards.
Most platforms start with high standards. Then they need growth. So they reduce friction. Automate verification.
And quality degrades. Gradually. The dataset grows but average contribution quality declines.
Maybe OpenLedger has solved this. Maybe their verification scales without degradation.
Maybe they haven't and they're facing the same trade-off. Quality or scale. You can have curated datasets with high standards. Or massive datasets with loose standards. Rarely both.
The stakes for model performance depend on whether contribution incentives align with quality or just with quantity. If rewards correlate with actual model improvement, contributors optimize for quality. If rewards correlate with volume, contributors optimize for volume.
Most reward systems optimize for measurable things. Volume is measurable. Quality is subjective. So systems reward volume and hope quality follows.
It usually doesn't. Quality requires judgment. Expertise. Domain knowledge. Time. Those are expensive. Volume is cheap.
I'd prefer seeing evidence that OpenLedger datanets produce better models than centralized alternatives. Not just bigger datasets. Better model performance.
If models trained on OpenLedger data perform similarly or worse, then decentralization isn't adding value.
The data quality question matters because AI models are only as good as their training data. You can have perfect infrastructure, transparent attribution, fair compensation. If the underlying data is mediocre, your models will be mediocre.
Most decentralized AI platforms emphasize their infrastructure. Look at our attribution layer.
Less emphasis on: look at our data quality. Look at model performance.
That's concerning. If your data is actually good, you lead with that. If your infrastructure is impressive but your data is questionable, you talk about infrastructure.
Maybe, OpenLedger has strong data. Maybe, their models perform well. Maybe I haven't seen the benchmarks. because they haven't published them yet.
Maybe, the data is mediocre and they're hoping volumes compensates for quality.
That might work for some use cases. More data can overcome lower quality if you have enough compute.
It doesn't work for specialized domains. Medical data, legal data, scientific data. You can't compensate for low-quality contributions with volume.
I'm watching to see which type of AI OpenLedger becomes. Generic models where volume matters? Or specialized models where quality is critical?
The data quality question's fundamental. You can build impressive infrastructure for collecting and attributing data. If the data itself isn't good, the infrastructure is optimizing the wrong thing.
And honestly, I trust platforms that emphasize model performance over platforms that emphasize infrastructure while avoiding performance comparisons.
