跟几个当年一起在GameFi里肝到天昏地暗的老兄弟喝了顿酒,聊起现在这行情,大家都沉默了。有个哥们说现在每天还得定闹钟起来收菜,比上班还累,一问赚了多少,他说上个月扣掉电费和脚本钱,净亏两百。说完自己都笑了。
我是Moon,今天是死磕@OpenLedger 的第5天。说真的,我最近越看越觉得,咱们这帮人以前的路子整个就走反了。每天跟个工具人似的在那点鼠标,点到最后项目方一改规则,白干。所以今天不想讲什么大道理,就想跟你们聊聊,为啥我现在觉得AI这波浪潮里,真正值得咱们去搞的东西,不是算力,是数据。

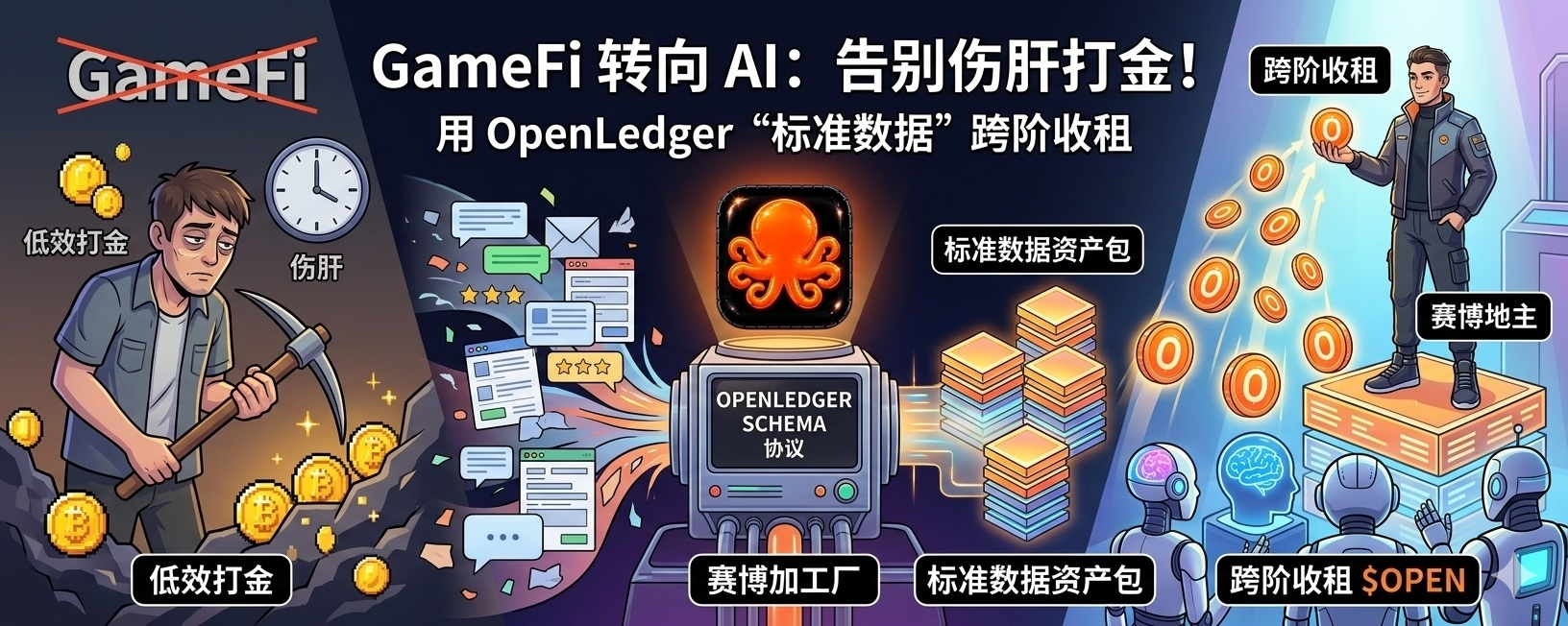
一、 为什么之前的“打金”注定归零?
以前大家玩链游打金,本质上是在出卖**“低效的重复体力”**。你每天花 10 个小时砍树、挖矿,产出几万个像素材料。但这种行为没有任何技术壁垒,工作室开一万个脚本就能瞬间把你的劳动成果冲垮,导致代币无限通缩,最后经济模型彻底崩盘。
但在 AI 时代,核心生产力变了。AI 模型最缺的不是算力,而是**“人类的真实行为数据”**。而这些数据,是工作室用机器死循环生成不出来的。
二、 解密 OpenLedger 的 Schema 协议:把“废语料”变成“金资产”
很多人会问:Moon,我每天在网上吹水、刷帖产生的那些碎碎片片的数据,AI 公司怎么看得上?人家怎么可能为了我几条评论就给我发代币?
这就要提到 @OpenLedger 极其牛逼的一个底层技术护城河——Schema(数据规范协议)。
大白话说,AI 公司确实不需要你零散的网页垃圾,他们需要的是结构化、干净、能直接喂给模型吃的高质量原材料。OpenLedger 就像是一个“赛博加工厂”。
当你把你的垂直领域知识、日常消费反馈或者特定行业的调研语料提交到网络时,OpenLedger 的 Schema 协议会自动把这些杂乱无章的信息,切片、脱敏并翻译成 AI 能够百分之百识别的“标准资产包”。
三、 从“无产网民”到“资产地主”的跨越
一旦你的数据被 Schema 规范化上链,奇迹就发生了:它在链上变成了一个个专属的数据池(Data Pools)。
未来只要有任何垂直领域的 AI 智能体(Agent)或者大厂模型在进行微调时调用了你这个数据池里的内容,智能合约就会严格按照次数,自动把 $OPEN 代币作为地租源源不断地打进你的钱包。
Moon 的投资观察:
以前链游打金,你是在给项目方打工,项目方倒闭你的资产归零。而在 @OpenLedger 里面“打数据”,你是在为整个硅基文明积攒原材料,你产出的高质量标准数据,随着 AI 模型的不断迭代,不仅不会贬值,反而会因为稀缺性而越来越贵。
AI 时代的搞钱姿势已经变了。把你的眼界从那些伤肝的连击盘子里拔出来,了解 @OpenLedger ,做第一批把日常行为转化成数字资产的“赛博地主”! #OpenLedger